Part01 ☀️
Part01 ☀️
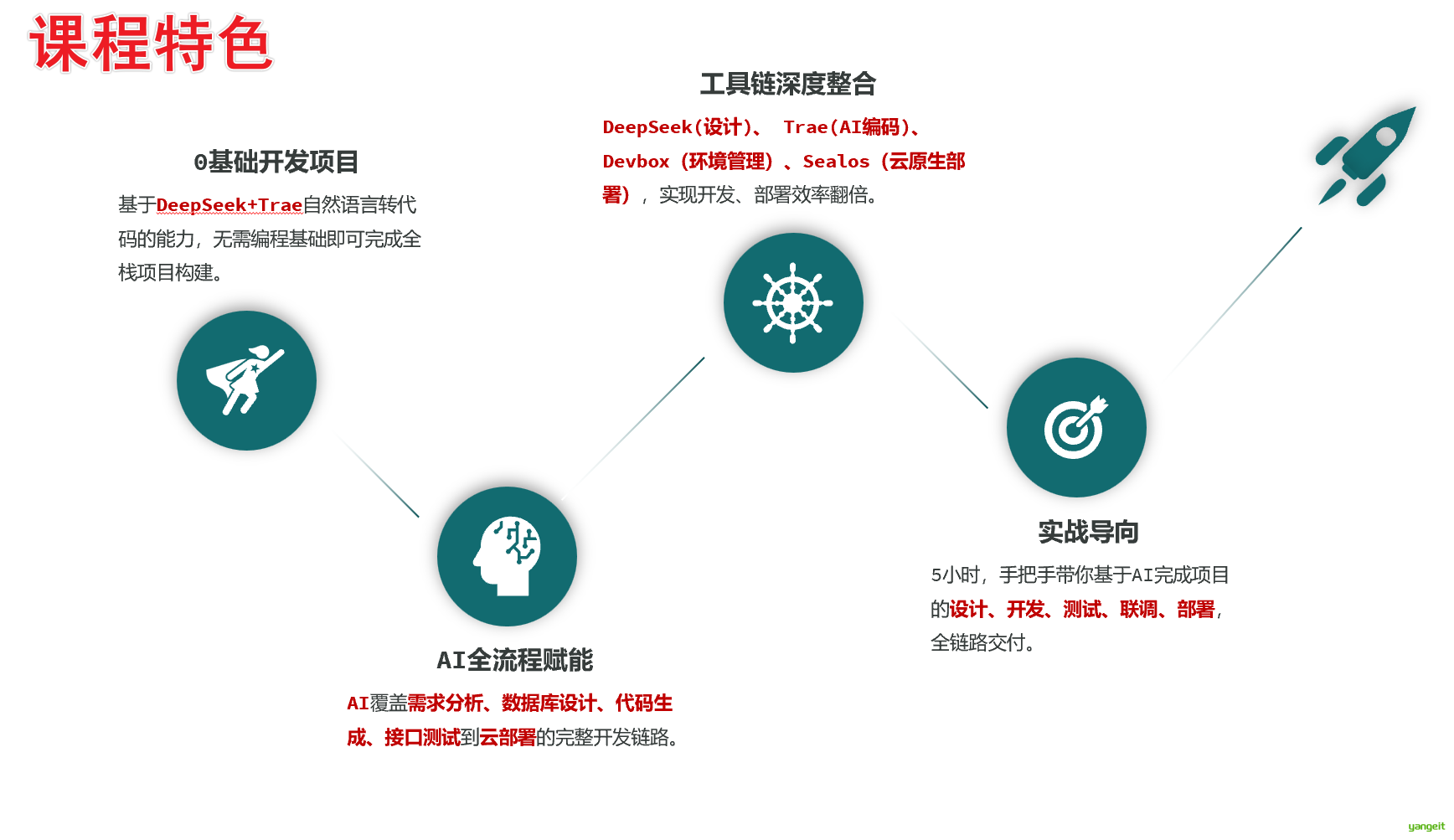
课程内容
- 整体介绍
- AI编程介绍
- 成品项目的演示
- 编程环境安装
- Sealos云操作系统介绍
- Trae介绍和安装
- Deepseek介绍和使用
- Devbox介绍和安装
- Apifox介绍和使用
- 编程前置知识讲解
- 页面原型 🍐
- 接口文档 🍐
- Http协议、域名和端口 🍐
- 服务器 🍐
1. 课程介绍
课程介绍

不写代码,搞定项目开发(数据库设计+后端开发+前端开发)
案例 👇
适用人群

2. 实训编码的环境
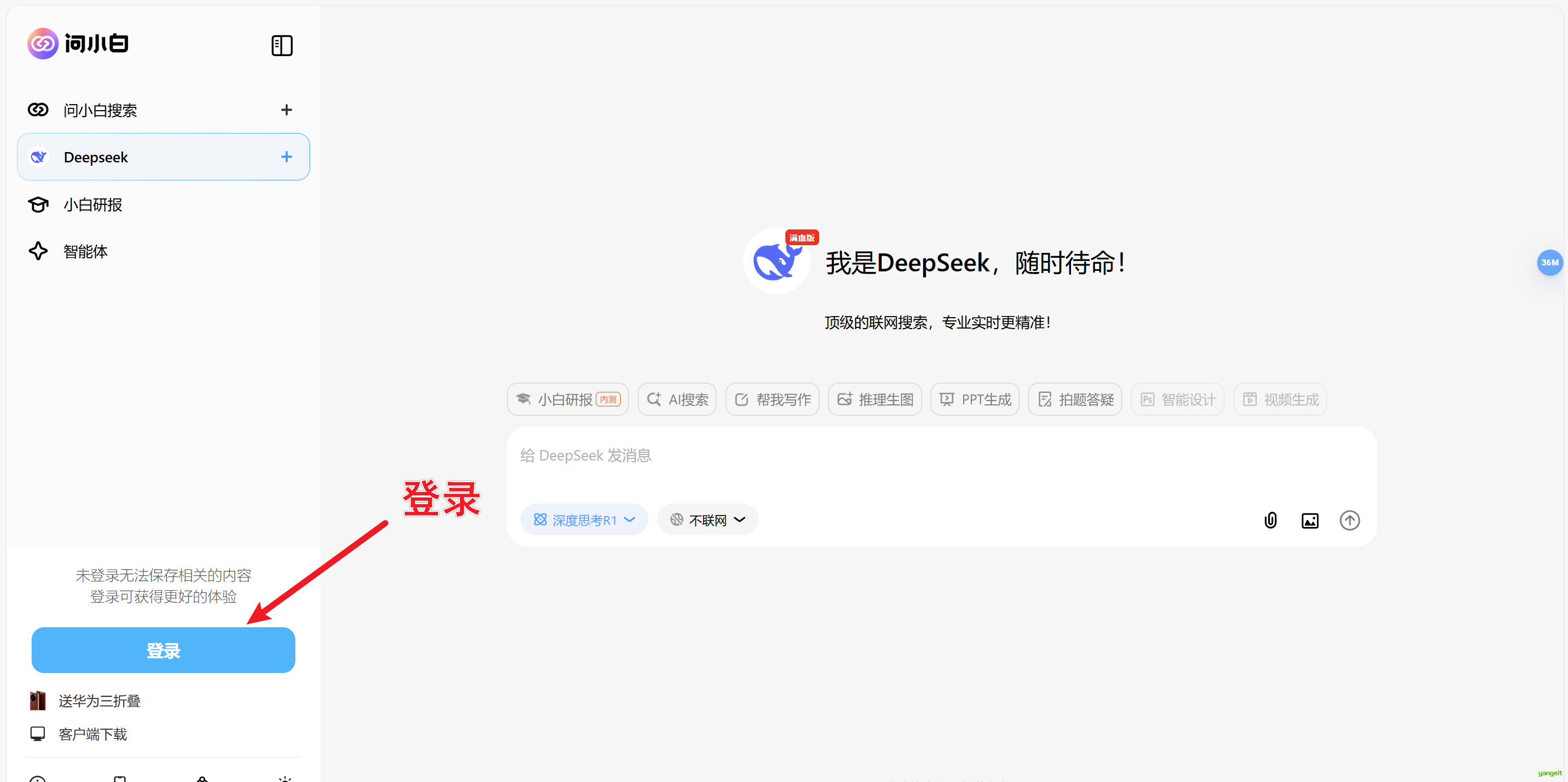
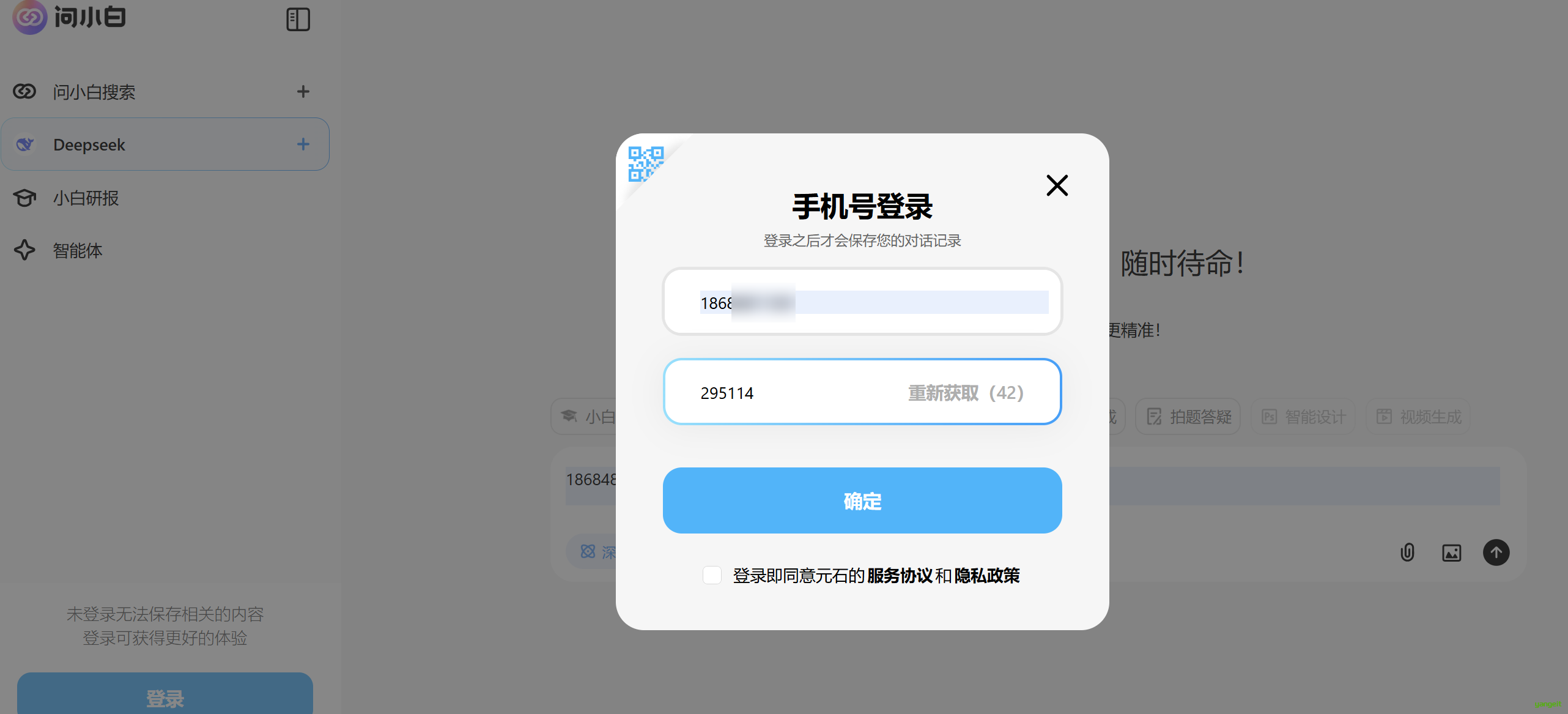
2.1 Deepseek介绍和使用
Deepseek介绍和使用

DeepSeek(中文名:深度求索)是一款由杭州深度求索人工智能基础技术研究有限公司开发的人工智能模型。其英文名“DeepSeek”可以读作“深思”(Deep)和“探索”(Seek),寓意着通过深度学习技术探索未知的领域。
功能:
- 深度学习模型:DeepSeek使用深度学习技术,可以处理和分析大量的数据,并从中提取有价值的信息。
- 自然语言处理:DeepSeek可以理解和生成自然语言,可以用于机器翻译、情感分析、文本分类等任务。
- 编程辅助:DeepSeek可以辅助编程,可以提供代码补全、代码生成、代码优化等功能。
- 语音识别:DeepSeek可以处理和理解语音,可以用于语音识别、语音合成、语音翻译等任务。
- 个性化推荐:DeepSeek可以根据用户的兴趣和行为,提供个性化的推荐服务。

考虑到官网只识别文字,因此推荐使用wenxiaobaiDeepseek
代码操作


总结
课堂作业
- 你使用过Deepseek吗?平常让他帮你做什么?🎤
- 向Deepseek提出你想问的问题把!!
- 为什么要使用wenxiaobai的Deepseek?
2.2 Sealos云操作系统介绍
Sealos云操作系统介绍

Sealos DevBox 是一个一站式云开发平台,将在线开发、测试和生产环境完美集成。只需一键点击,即可快速创建所需的开发环境和数据库依赖。开发者可以使用熟悉的本地 IDE(如 VSCode、Cursor、JetBrains 等)进行开发,同时享受简化的环境配置和自动化的应用部署体验。平台支持所有主流编程语言和框架,包括 Node.js、Python、Java、Go、PHP、Ruby 等,以及各类前端框架如 React、Vue、Angular 等。
代码操作

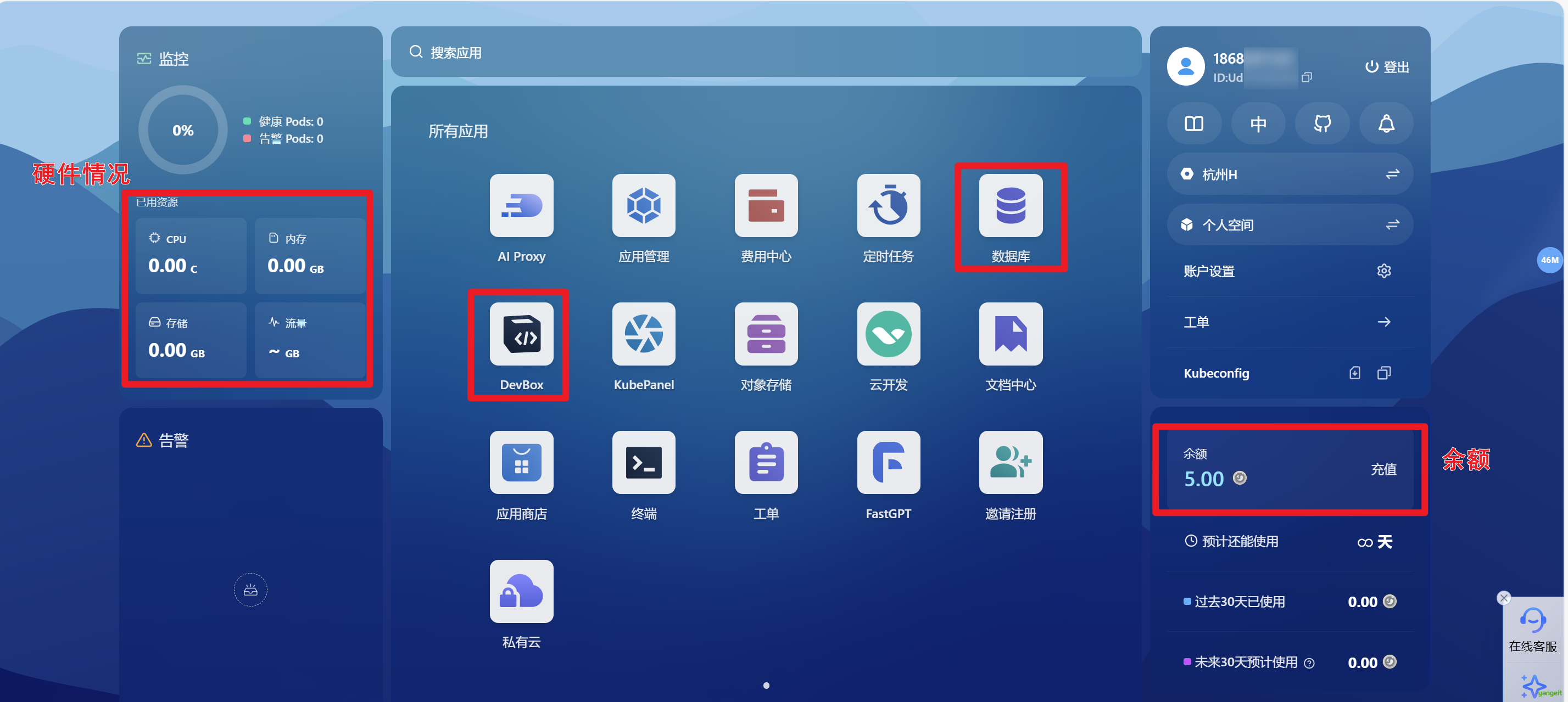

DevBox:一站式云开发平台,支持在线开发、测试和生产环境,支持所有主流编程语言和框架,包括 Node.js、Python、Java、Go、PHP、Ruby 等,以及各类前端框架如 React、Vue、Angular 等。 
数据库:支持 MySQL、PostgreSQL、MongoDB 等主流数据库,支持在线管理、备份和恢复。 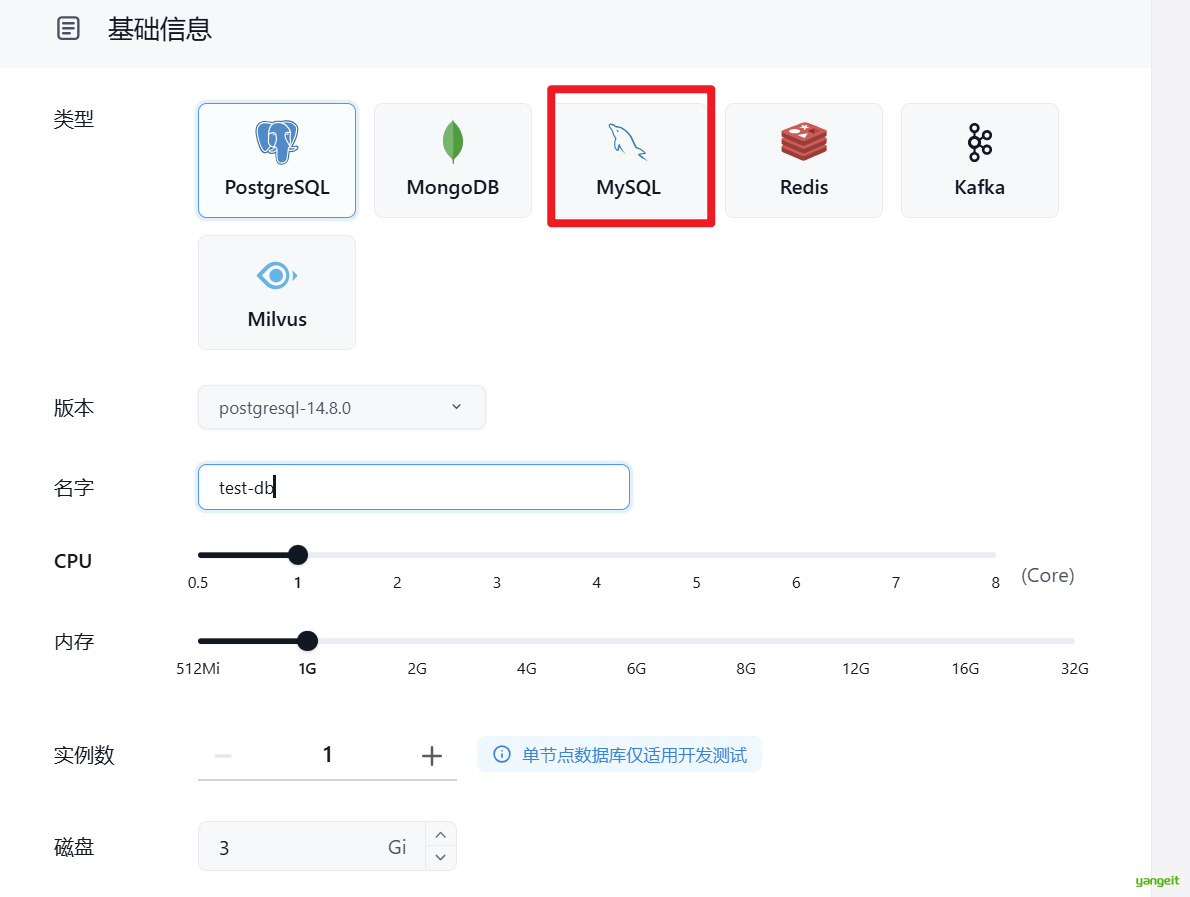
对象存储:支持存储和检索各种类型的数据,包括图片、视频、音频等。
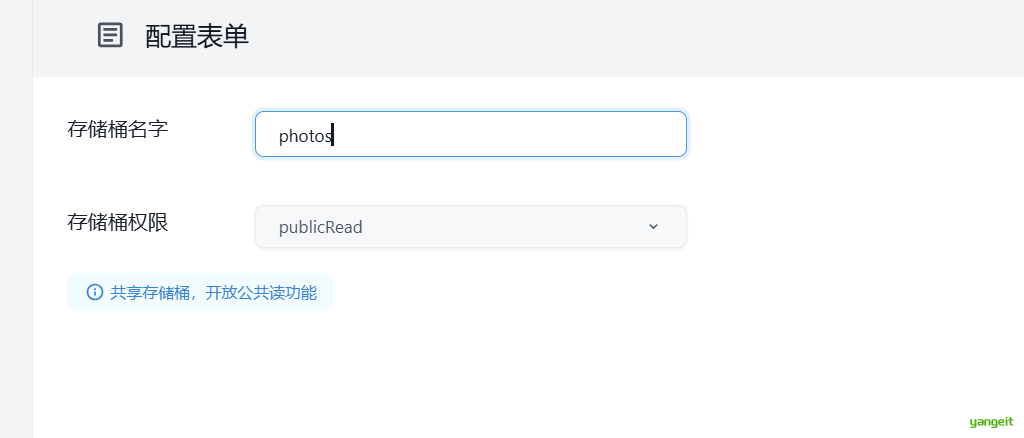
有了这些功能,意味着本地电脑上都不需要安装对应的软件,就可以进行项目开发了
总结
课堂作业
- 为什么要使用Sealos云操作系统?有什么好处?🎤
- Sealos云操作系统常用有哪些功能?🎤
- Sealos云操作系统是免费的吗?🎤
2.2 Trae介绍和安装
Trae介绍和安装
Trae( 国际官网:https://www.trae.ai) Trae是 字节跳动 2025年1月推出的 AI原生集成开发环境,由旗下新加坡公司SPRING PTE开发。 它主打“用自然语言生成代码”。 具备 AI 问答、代码自动补全、基于 Agent 的 AI 编程等功能,能助力程序员完成开发任务,甚至实现端到端开发。
Trae的功能:
- Builder 模式下,Trae 会自主拆解需求并自动完成多轮编码任务。从想法描述到功能实现,Trae 为你一气呵成。
- Trae 可以深入理解你的代码仓库,并深度结合 IDE 内信息,更准确识别你的需求,为你提供更优质的解决方法。
- 通过强大的上下文分析,Trae 可以实时预测和续写你的代码片段,快速无缝扩展你未完成的代码,数倍提升你的编码效率
当前时代如果还没有使用AI编程,你可能真的out了,这不代表你的技术不行,而是你还没有跟上时代的步伐。
代码操作


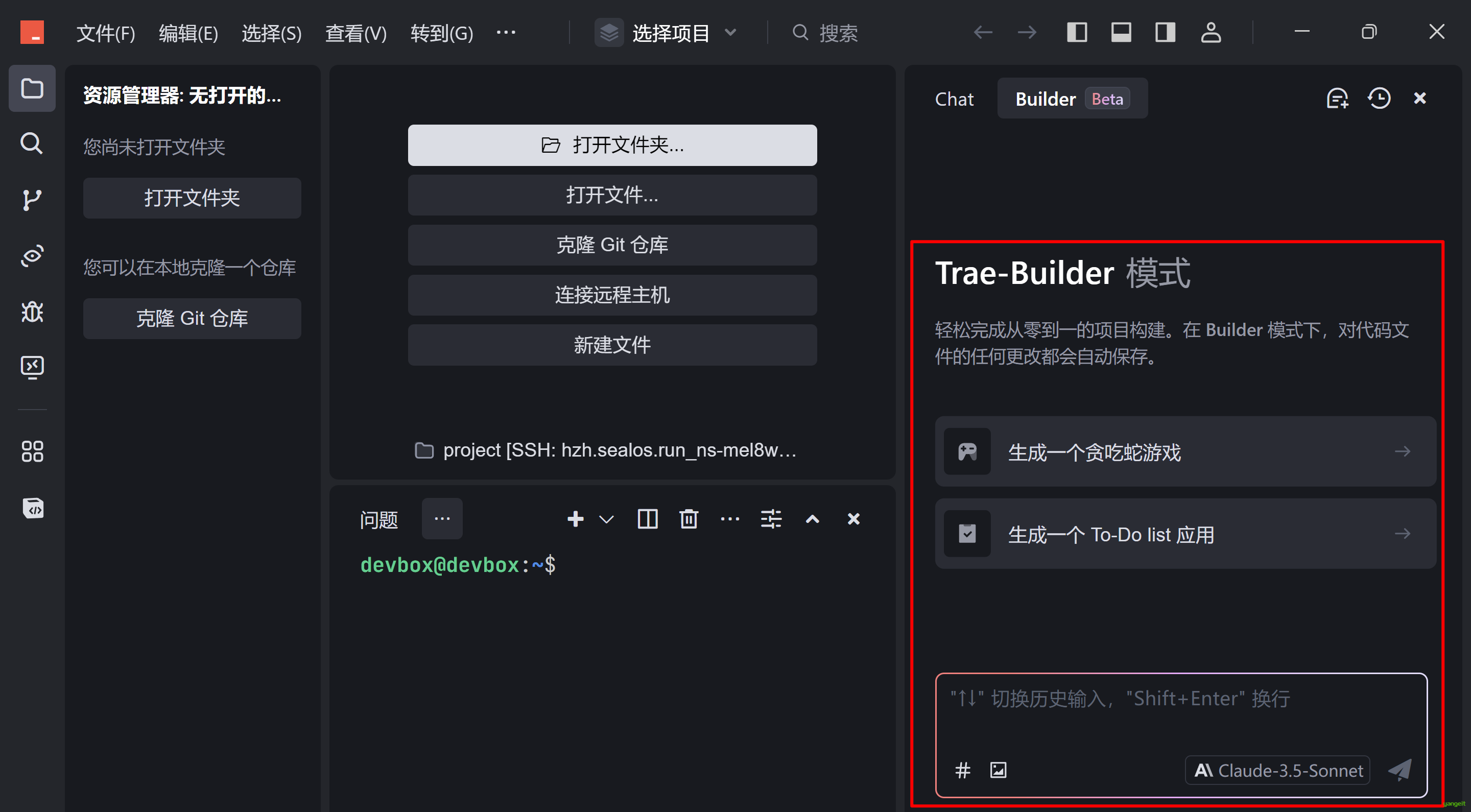
总结
课堂作业
- 为什么要下载国际版Trae?🎤
- 使用Trae来开发一个贪吃蛇游戏吧!
- 如果没有科学上网的工具,那就下载国内版本吧:https://www.trae.com.cn/home
注意:没有图片理解,只能依靠文字描述问题
2.3 Trae+Sealos完成SpringBoot入门功能
入门案例
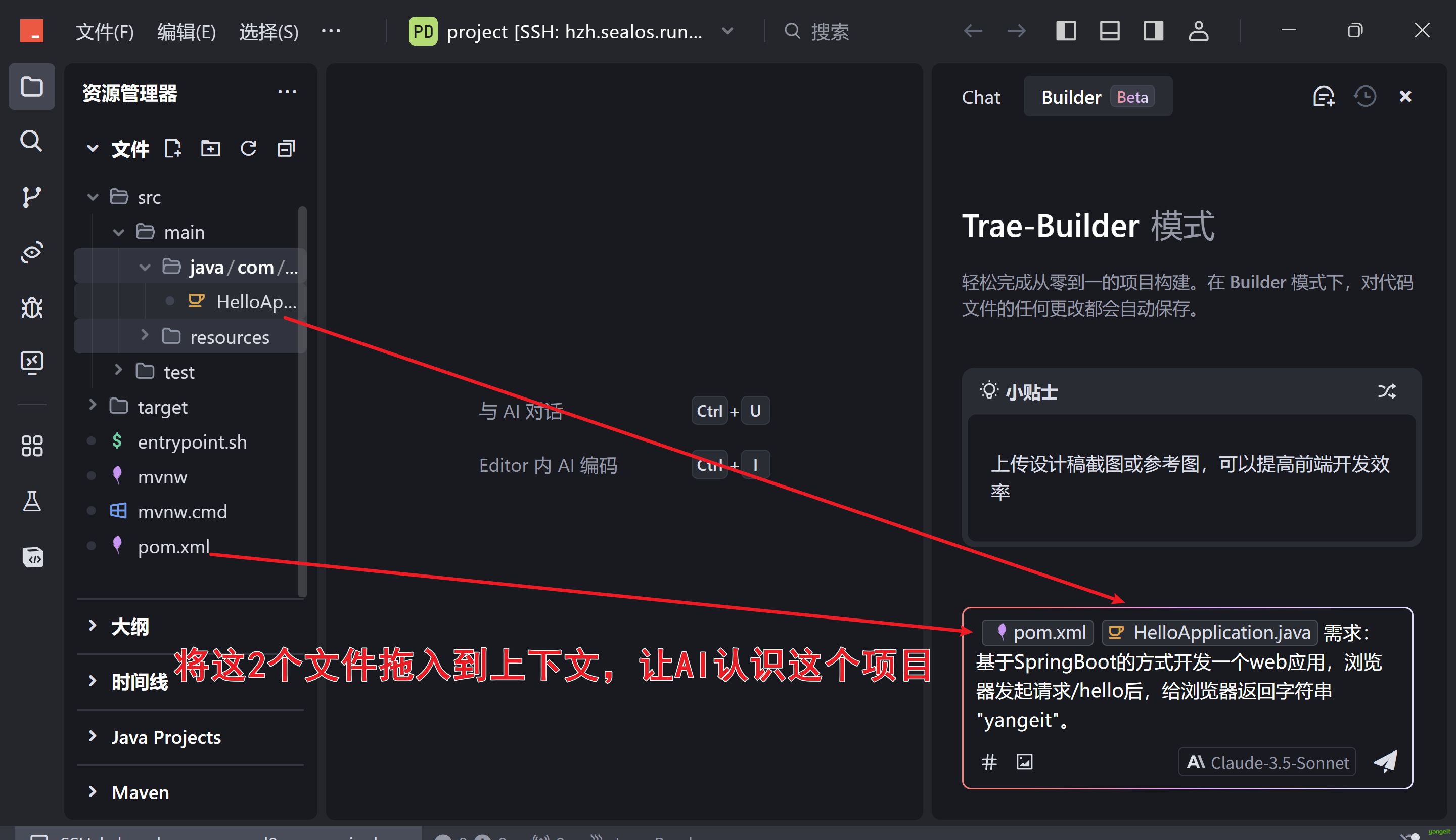
需求:基于SpringBoot的方式开发一个web应用,浏览器发起请求/hello后,给浏览器返回字符串 "yangeit"。

代码操作
步骤
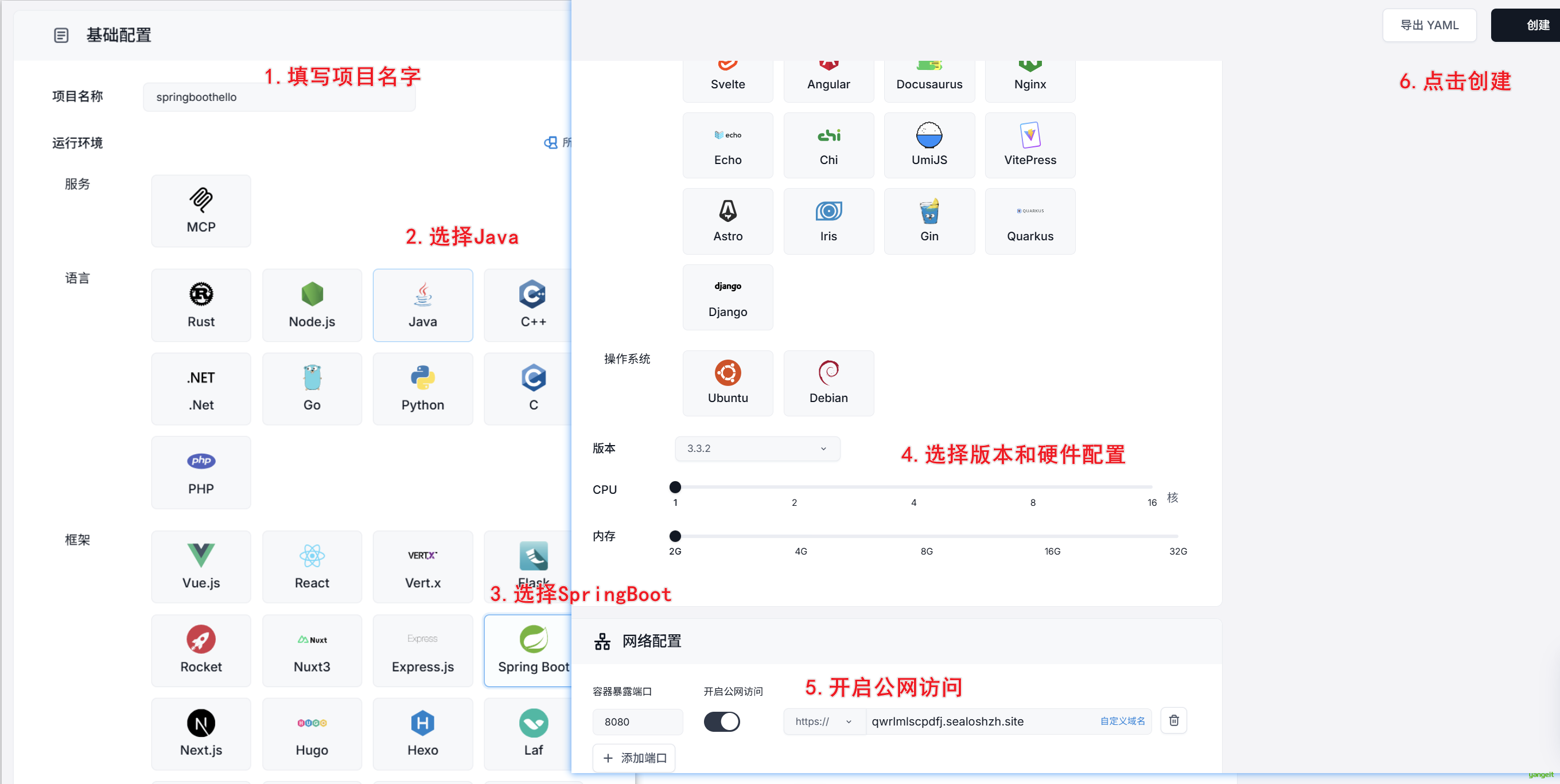
- 在sealos上创建一个项目,名称为:springboothello
- 使用trae打开Sealos中已经创建的项目 springboothello
- 在trae中通过Builder模式进行对话,将需求提交给大模型,大模型会自动生成代码
- 启动sealos中的springboot项目,外网访问,观察结果
- 进入sealos页面,点击Devbox,创建一个项目,名称为:springboothello

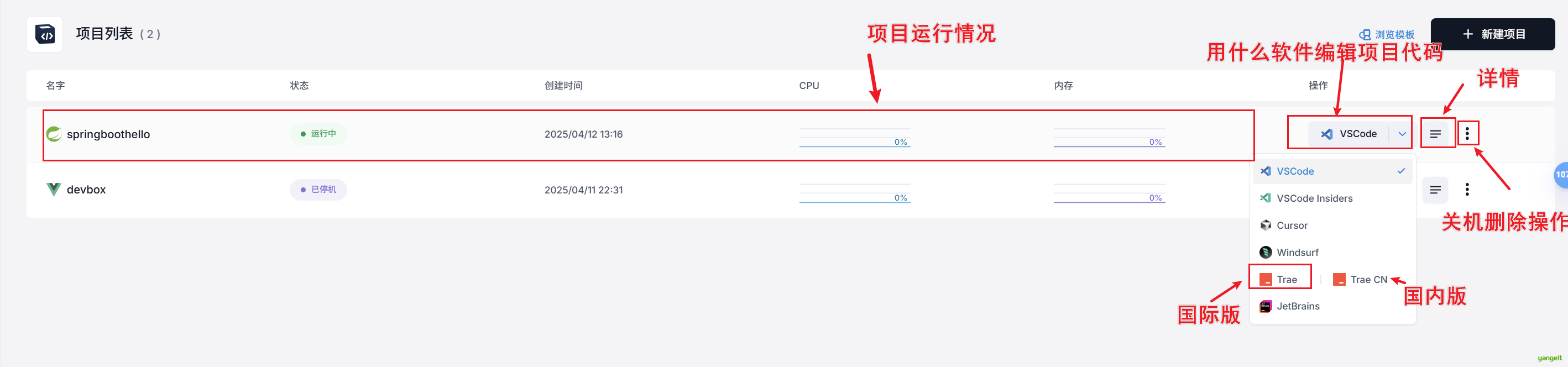
- 使用trae打开Sealos中已经创建的项目 springboothello
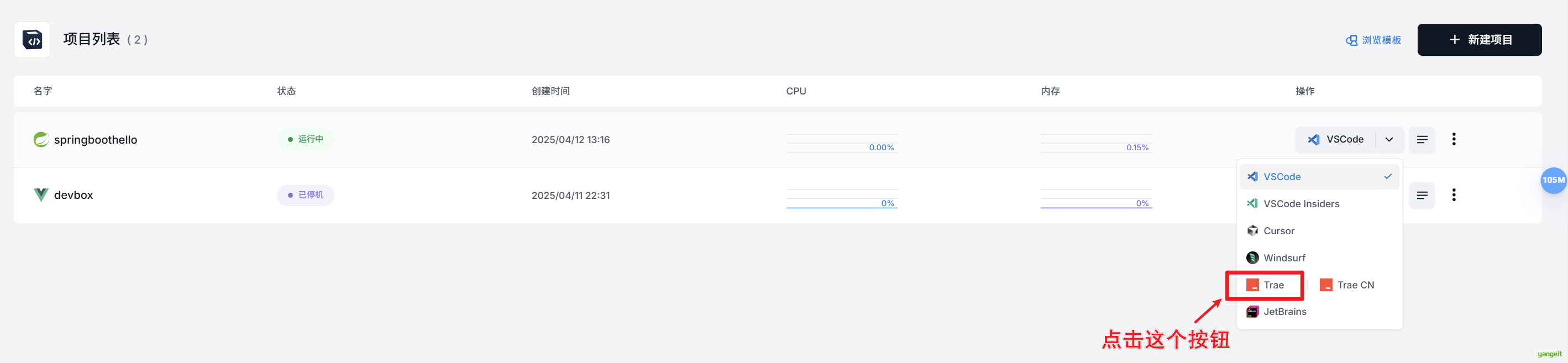
此时浏览器会自动打开trae的页面,自动连接到Sealos中已经创建的项目 springboothello,并显示代码,其中提示要安装插件,全部同意即可
提示信任项目,同意 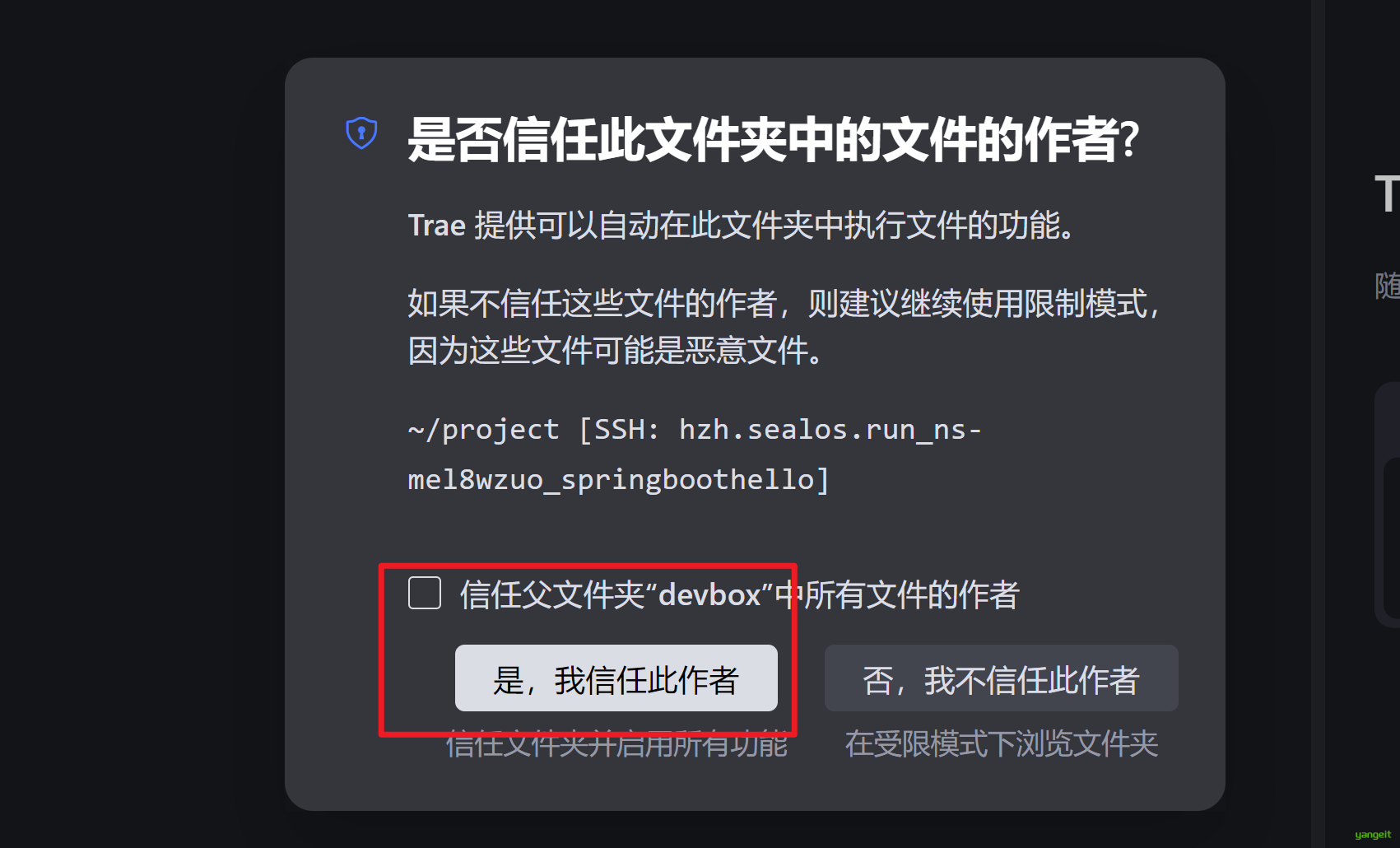
提示安装插件:同意 
链接成功后,会显示服务器中的代码 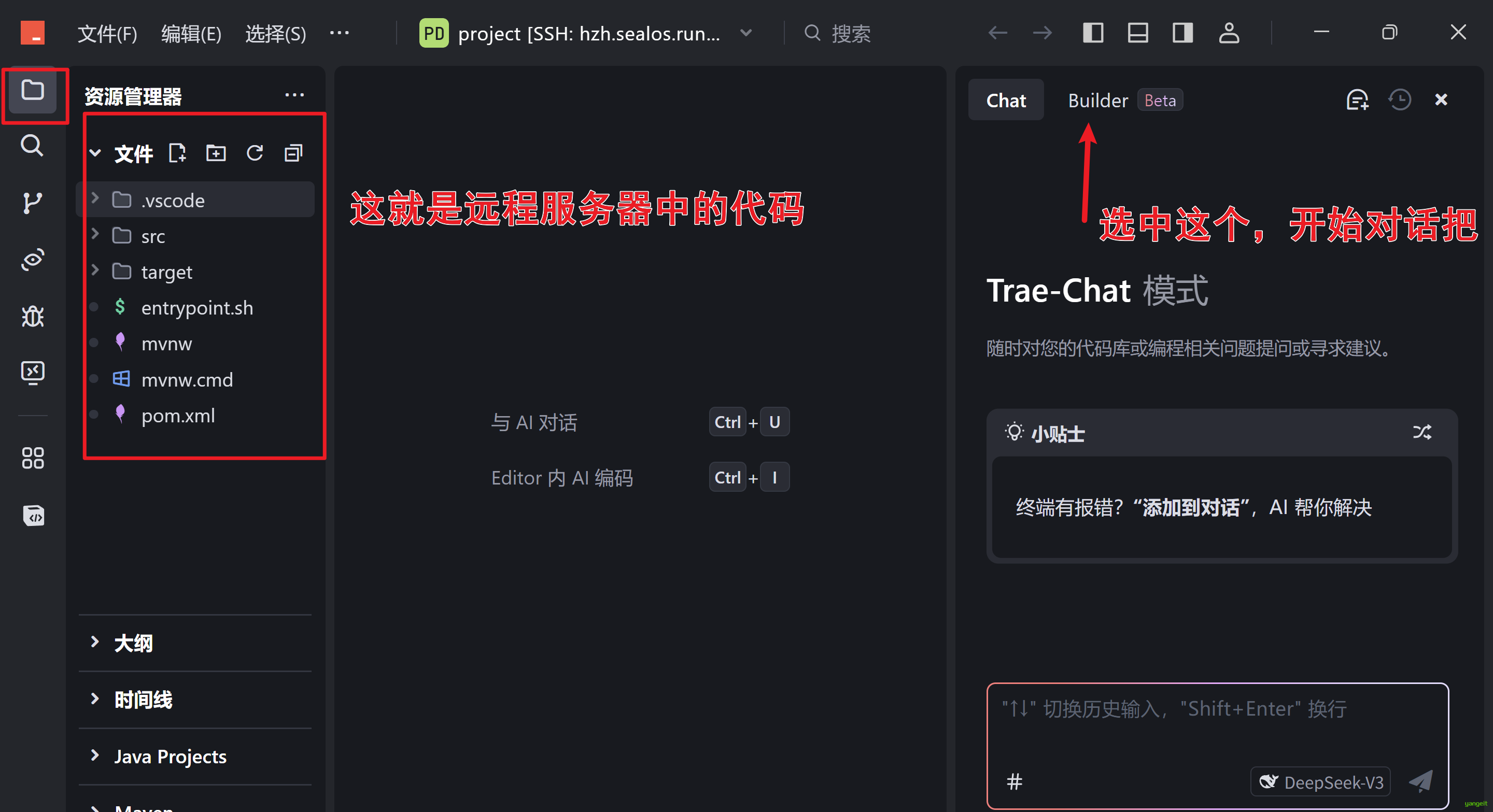
- 在trae中通过Builder模式进行对话,将需求提交给大模型,大模型会自动生成代码
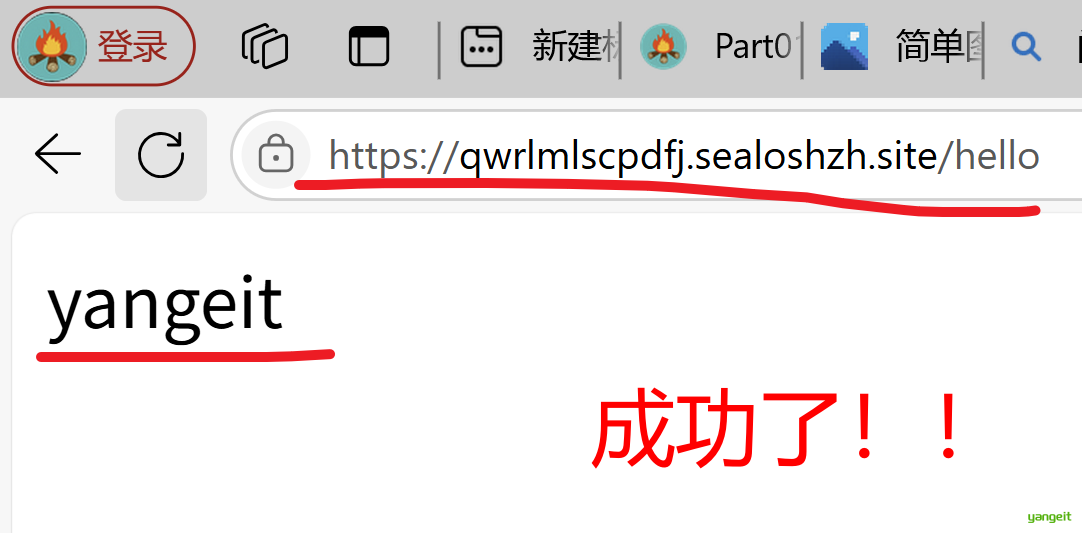
点击接受并点击运行,观察控制台是否有报错信息,如果没有报错信息,则表示代码已经成功运行 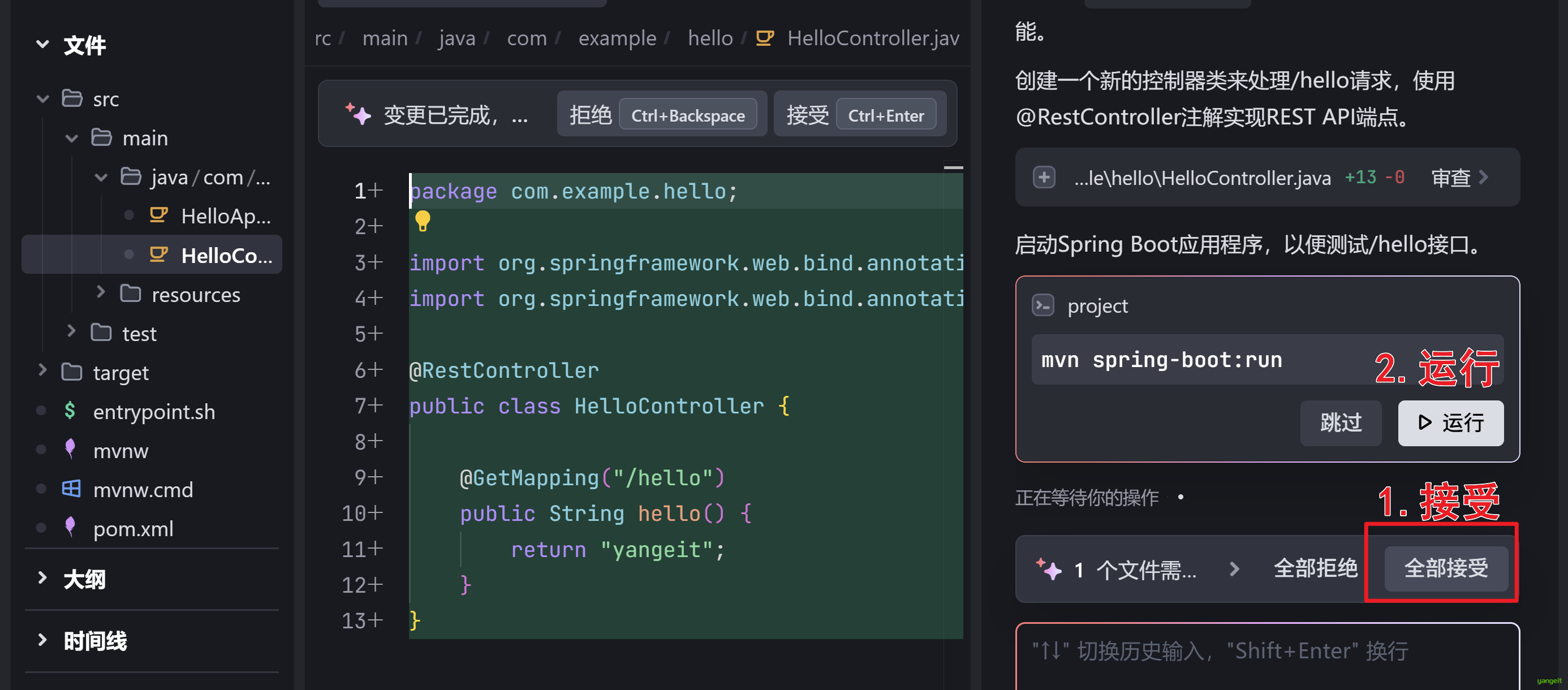
参考日志,发现成功了, 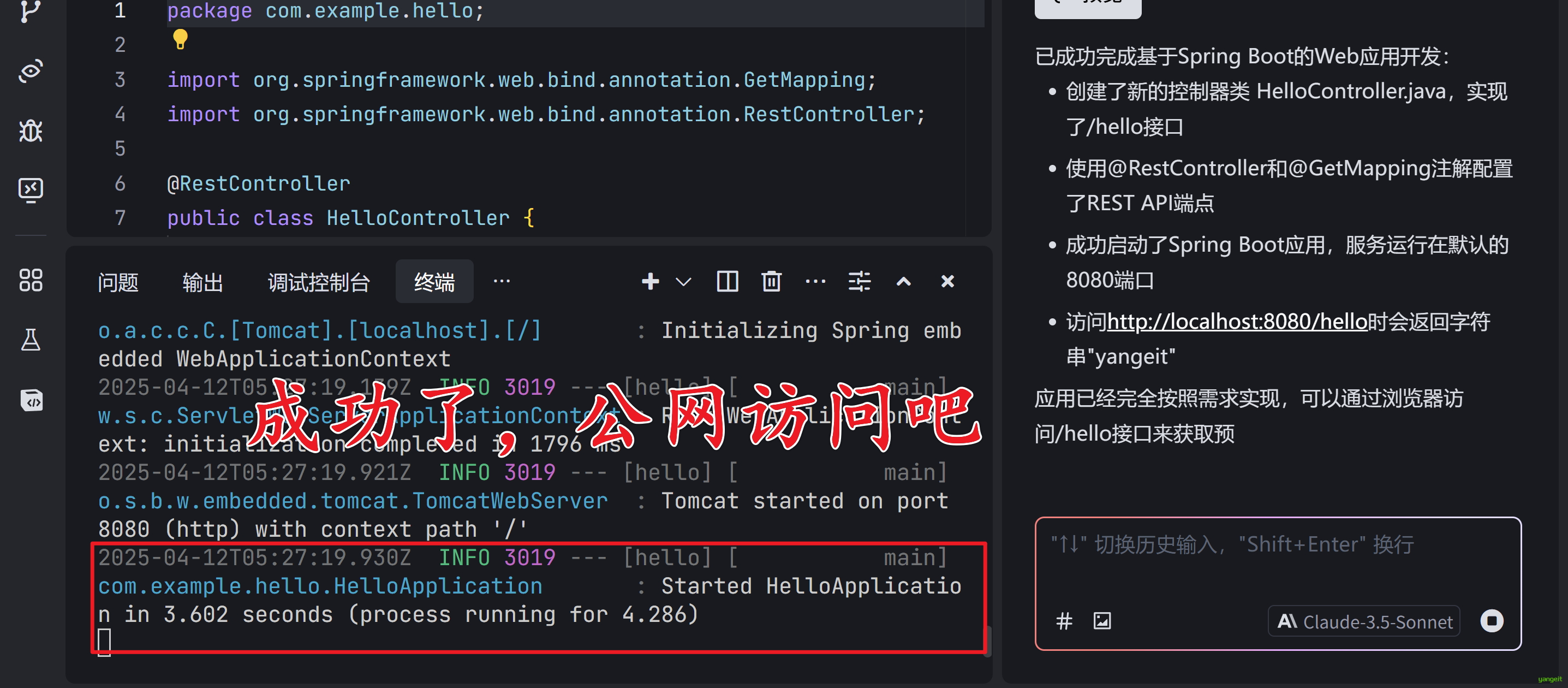
复制公网地址,访问:https://qwrlmlscpdfj.sealoshzh.site/hello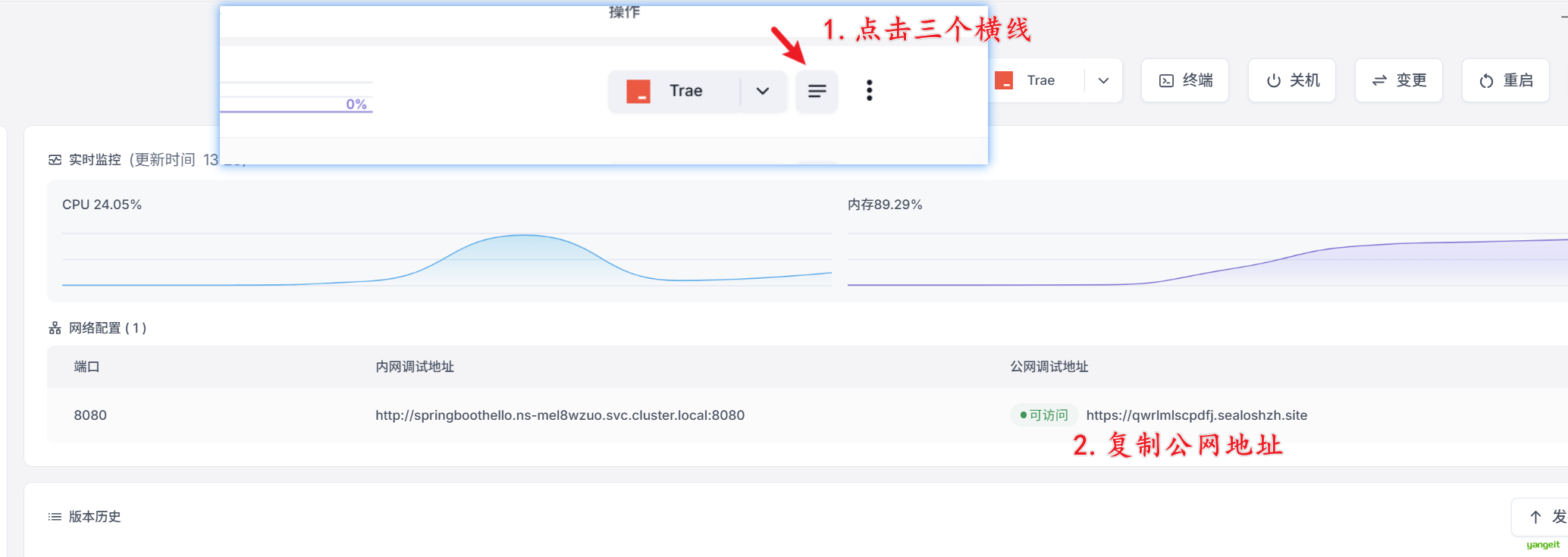
总结
课堂作业
- 参考上述步骤,实操试试吧!🎤
3. 编程前置知识讲解
3.1 页面原型
页面原型
页面原型是指:
- 一个模拟真实产品界面和交互的初步模型
- 用于展示页面布局、功能结构和用户流程的可视化表达
- 不包含完整视觉设计或后端功能的"半成品"演示
核心作用:
- 沟通工具
- 让团队成员对产品有统一认知
- 帮助非技术人员理解设计意图
- 验证工具
- 早期发现设计缺陷
- 测试用户流程是否合理
- 开发指南
- 为工程师提供明确的实现参考
- 减少后期修改成本
代码操作
总结
课堂作业
- 页面原型是谁开发的?❓
- 页面原型的作用是什么?能直接作为项目运行吗?🎤
- 页面原型的截图可以用来做什么?❓
- 上面提供了在线的页面原型,全部点击打开瞅瞅,观察里面的内容,有什么作用?❓
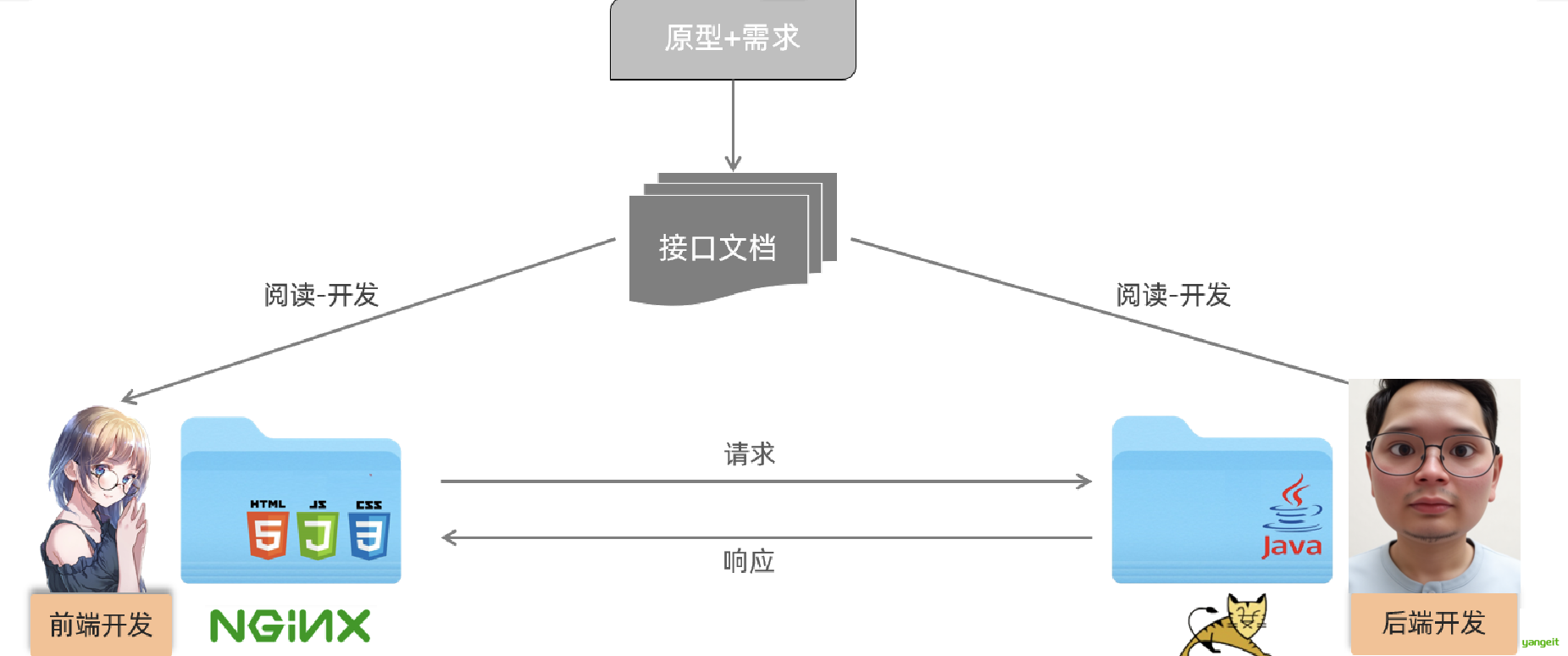
3.2 接口文档
接口文档
页面原型和接口文档对比👇
| 对比项 | 页面原型 | 接口文档 |
|---|---|---|
| 主要用途 | - 展示页面布局和功能结构 - 模拟用户交互流程 - 验证产品设计 | - 定义接口规范 - 明确数据交互方式 - 规范前后端对接 |
| 目标用户 | - 产品经理 - 设计师 - 开发人员 - 非技术人员/客户 | - 前端开发人员 - 后端开发人员 - 测试人员 |
| 核心作用 | - 统一产品认知 - 早期发现设计问题 - 验证用户体验 - 提供界面参考 | - 前后端沟通桥梁 - 接口调用参考 - 后端实现依据 - 减少沟通成本 |
| 内容形式 | - 可视化界面 - 交互原型 - 页面布局 | - 接口描述 - 参数说明 - 数据格式 |
| 开发阶段 | 产品设计阶段 | 技术开发阶段 |
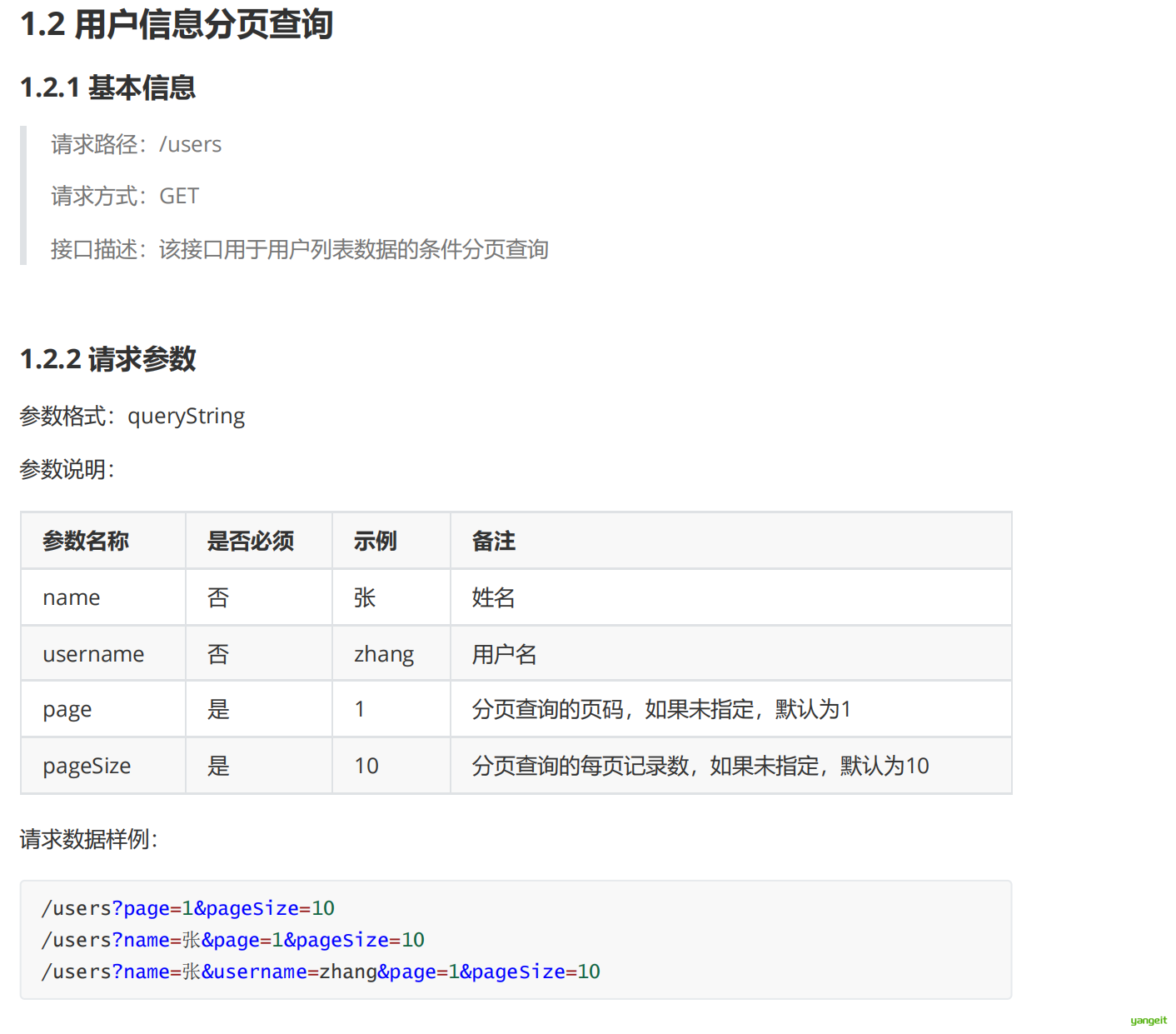
接口文档案例 👈 点击试试
总结
课堂作业
- 接口文档的作用是什么?🎤
- 接口文档和页面原型的区别是什么?❓
页面原型偏重于产品功能和用户体验的直观展示,而接口文档则专注于技术层面的前后端数据交互规范。两者在产品开发中承担不同但相辅相成的角色。
- 点击上面的接口文档案例链接,观察接口文档长啥样?体会前端和后端的对接规范。❓
4. 数据库设计
4.1 数据库表分析
数据库表分析
1.数据库设计流程
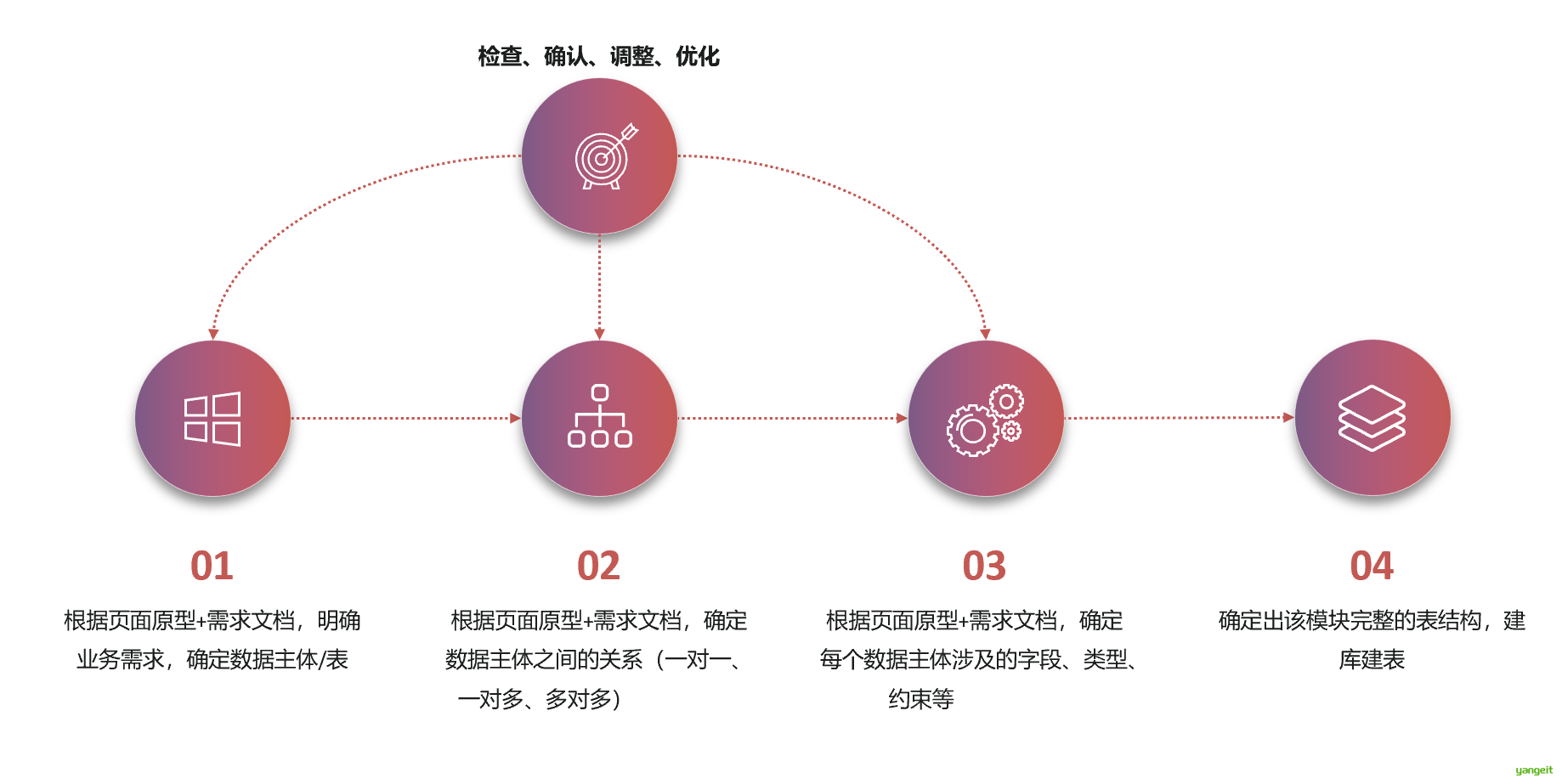
2.原型图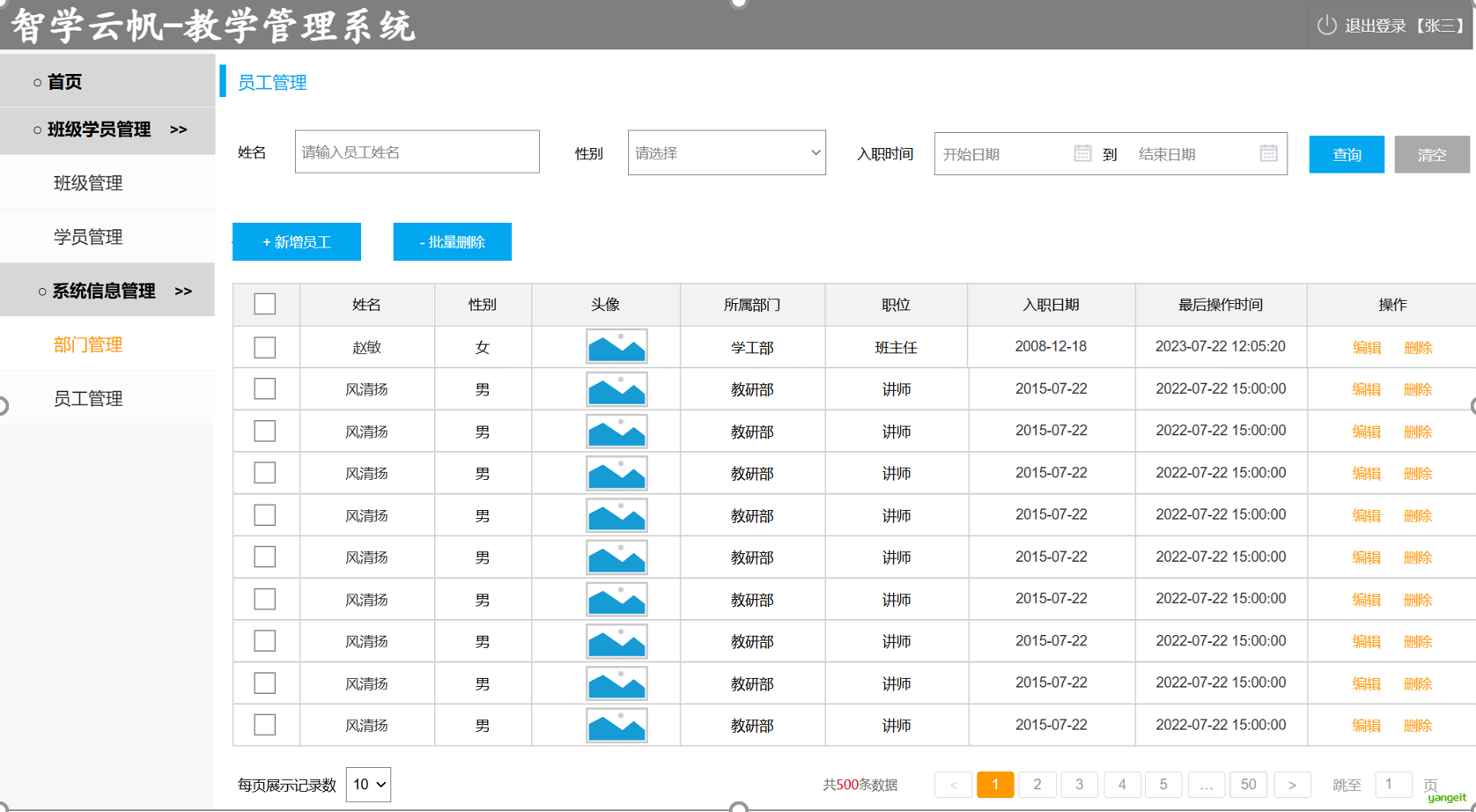
3.AI辅助数据库设计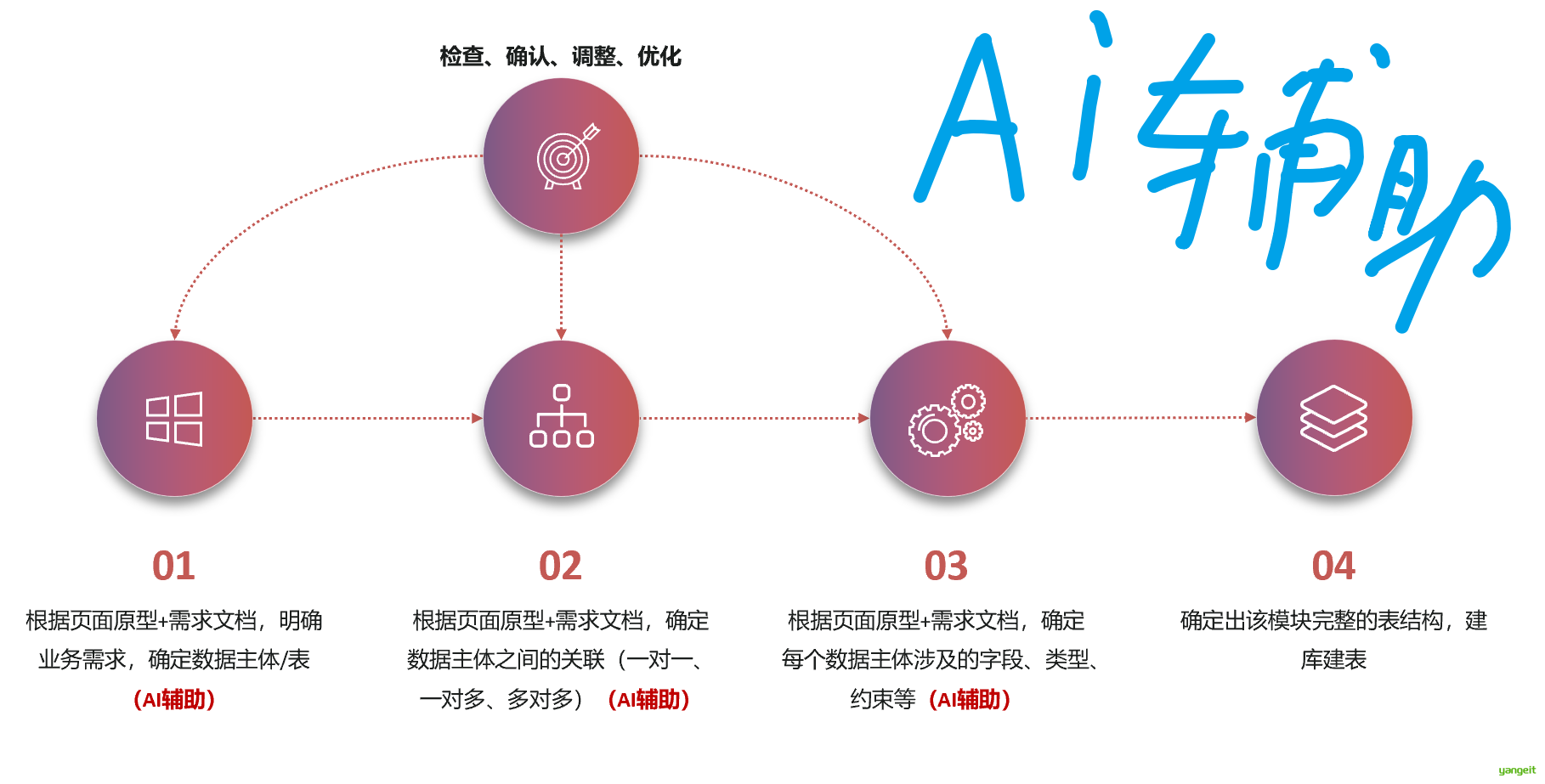
提示
实操过程中,我们可以截取页面原型图,通过AI工具进行数据库表设计,从而提升开发效率。做到所见即所得!!! 👈 👍
操作
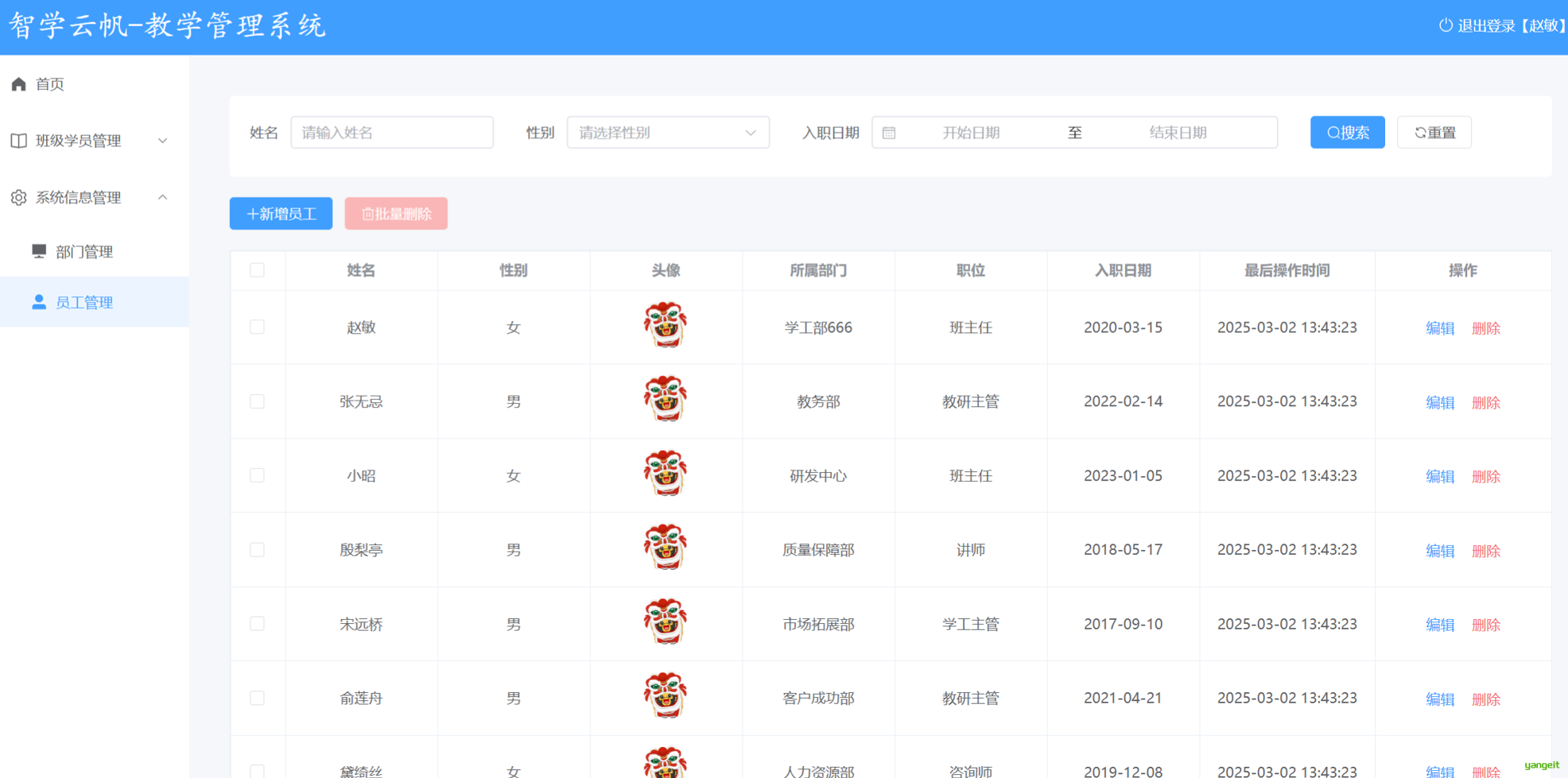
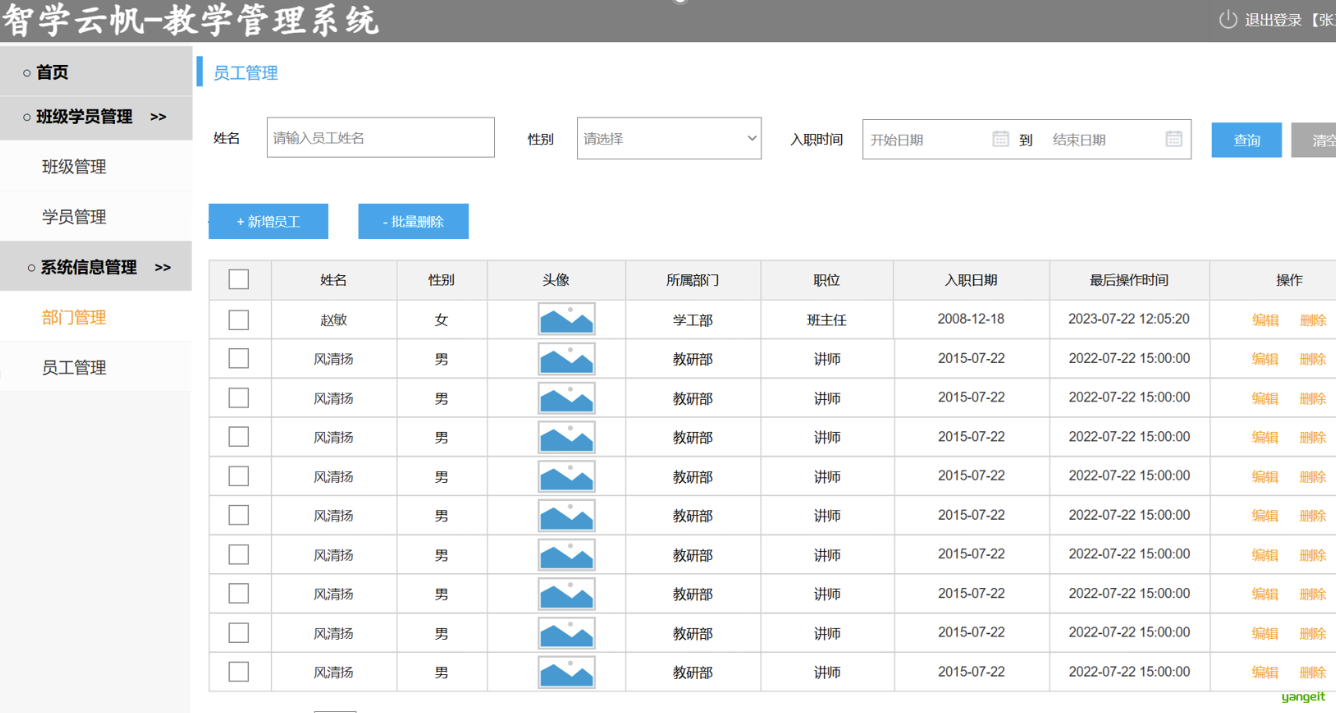
下面是从原型图截取的部分页面素材,用于设计数据库表。后面会用到这些截图
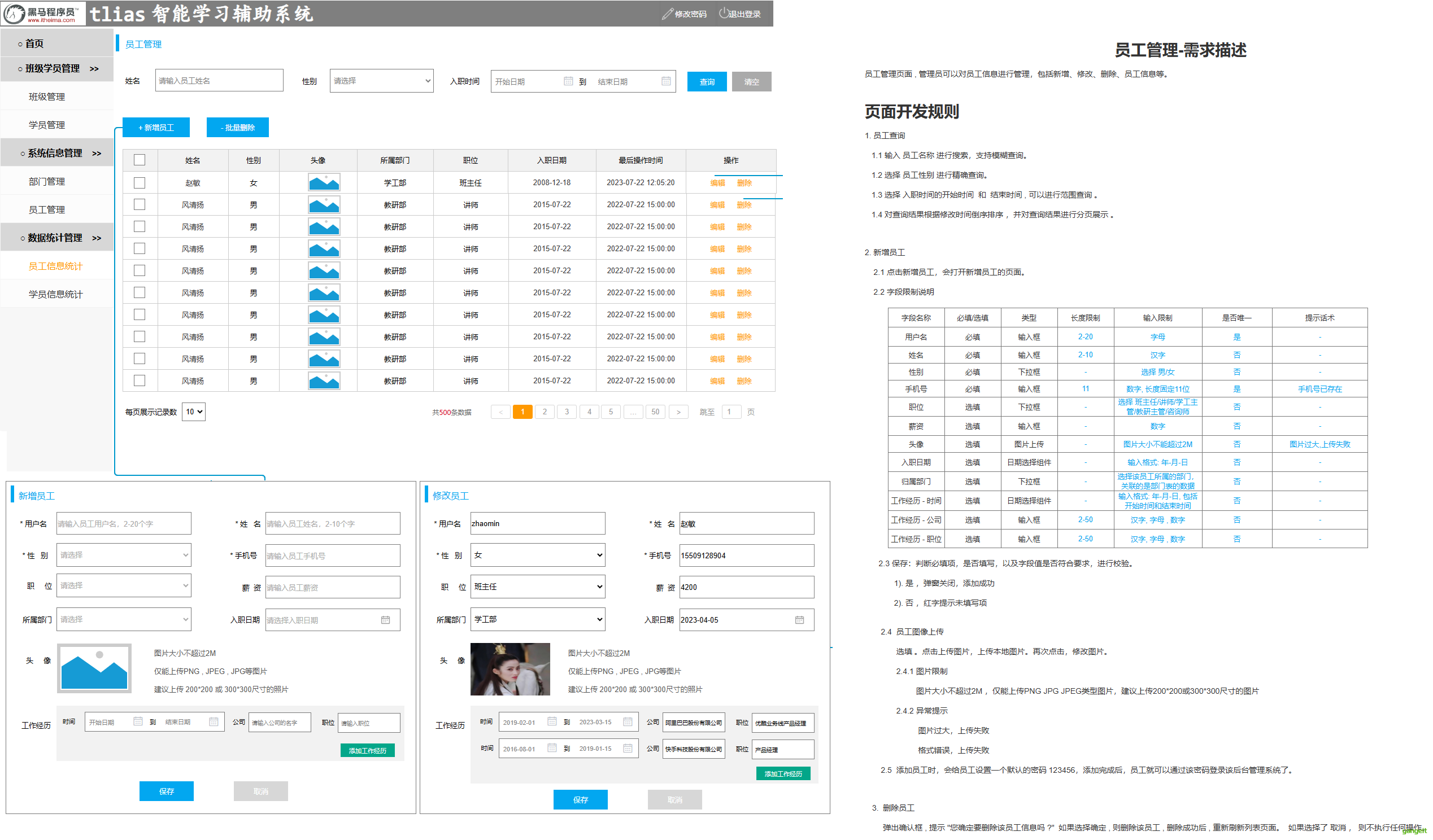
因为Deepseek每次只能输入一张照片,因此数据库表需要一张一张进行设计


1. 部门管理表设计
使用Deepseek,分析部门模块,需要几张表 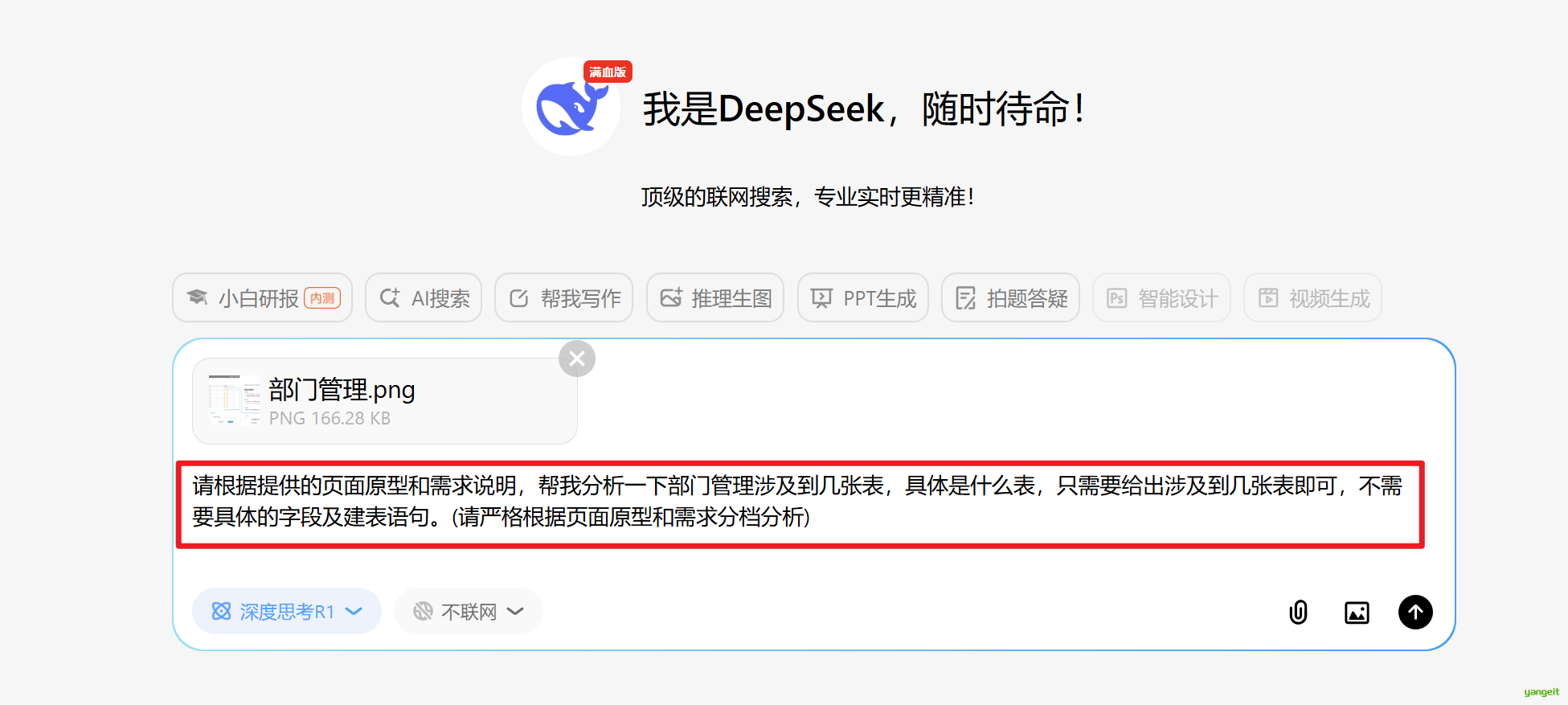
提示词如下:
请根据提供的页面原型和需求说明,帮我分析一下部门管理涉及到几张表,具体是什么表,只需要给出涉及到几张表即可,不需要具体的字段及建表语句。(请严格根据页面原型和需求分档分析)
经过Deepseek分析,结果如下: 
经过分析只涉及1张表,接下来,要跳转到页面原型图进行对照,确保分析结果正确。
2.员工管理表设计
使用Deepseek,分析员工模块,需要几张表 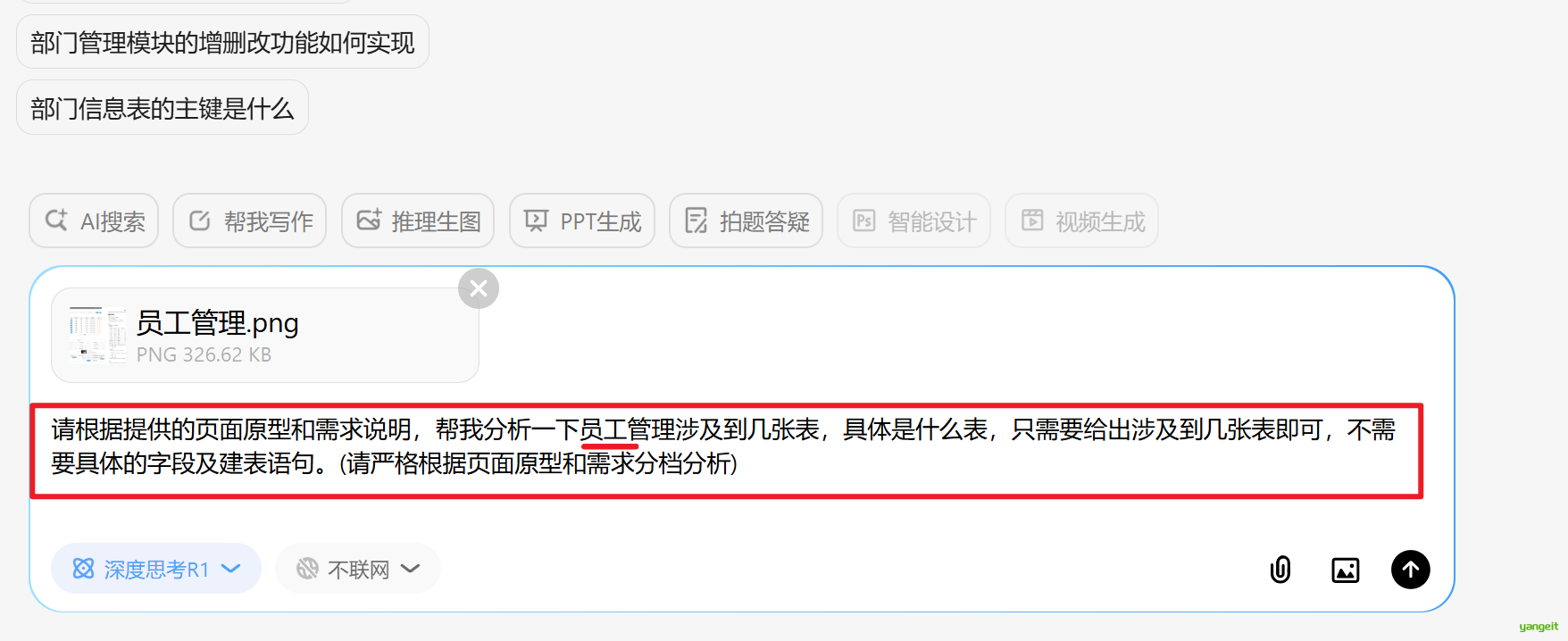
提示词如下:
请根据提供的页面原型和需求说明,帮我分析一下员工管理涉及到几张表,具体是什么表,只需要给出涉及到几张表即可,不需要具体的字段及建表语句。(请严格根据页面原型和需求分档分析)
经过Deepseek分析,结果如下: 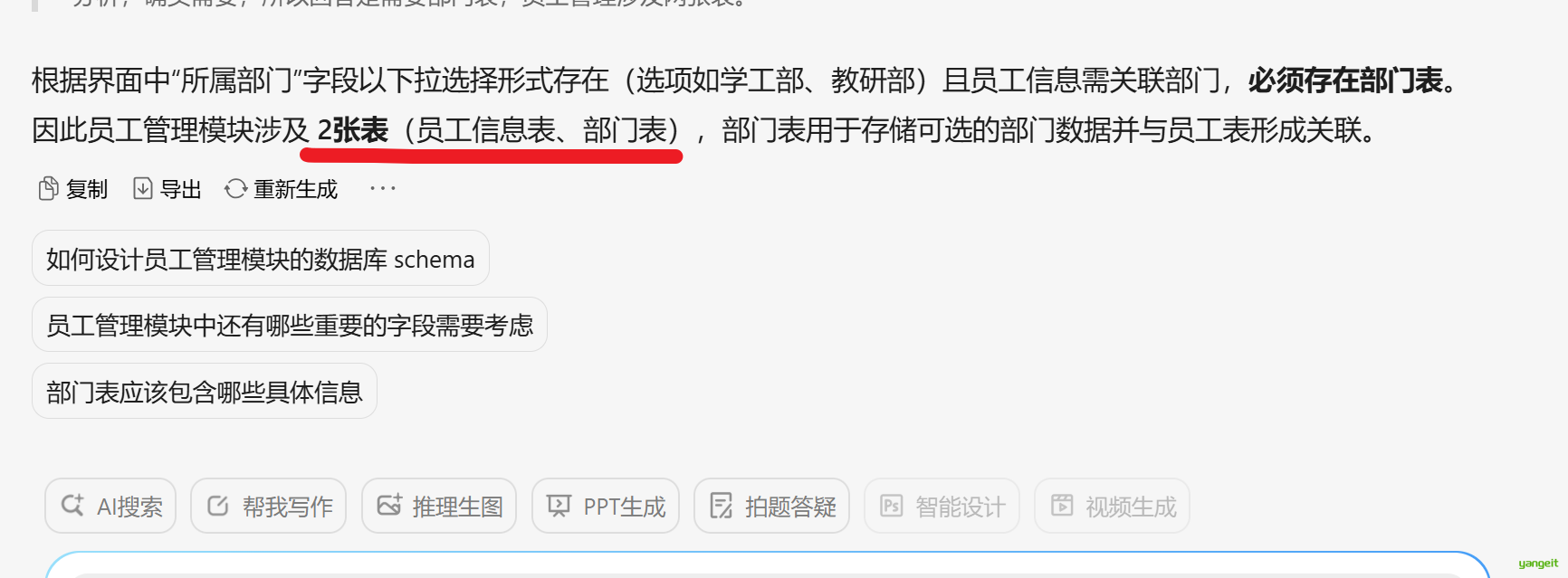
经过分析只涉及2张表,接下来,要跳转到页面原型图进行对照,确保分析结果正确。
经过和原型对照,发现AI分析并不准确,图中的工作经历没有识别出来 👇
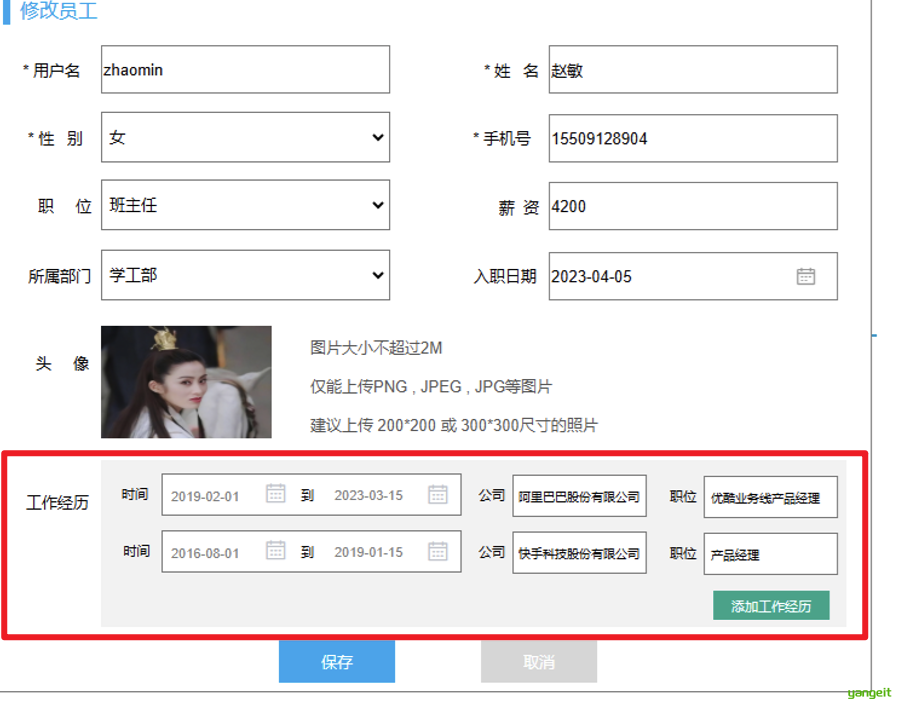
因此,需要继续问👇

提示词:👇
根据你的分析,员工管理只涉及到一张核心表就是员工表,员工表中怎么存储员工的工作经历信息呢?(请严格根据页面原型和需求分档分析)
分析存在问题,直接提出需要新增工作经历表 

3.接下来分析3张表的关系
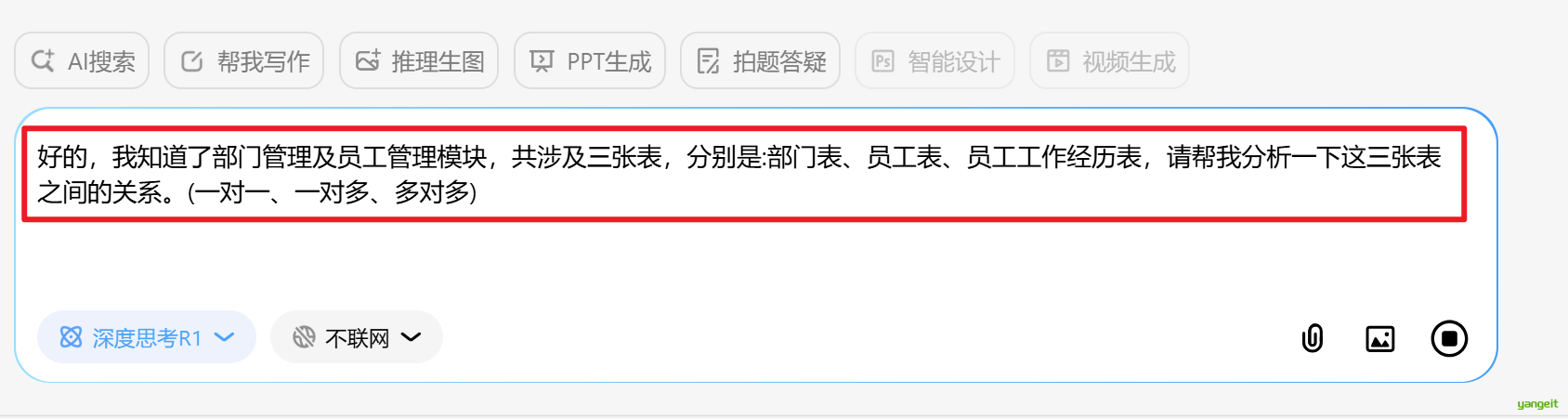
好的,我知道了部门管理及员工管理模块,共涉及三张表,分别是:部门表、员工表、员工工作经历表,请帮我分析一下这三张表之间的关系。(一对一、一对多、多对多)
分析结果如下:👇 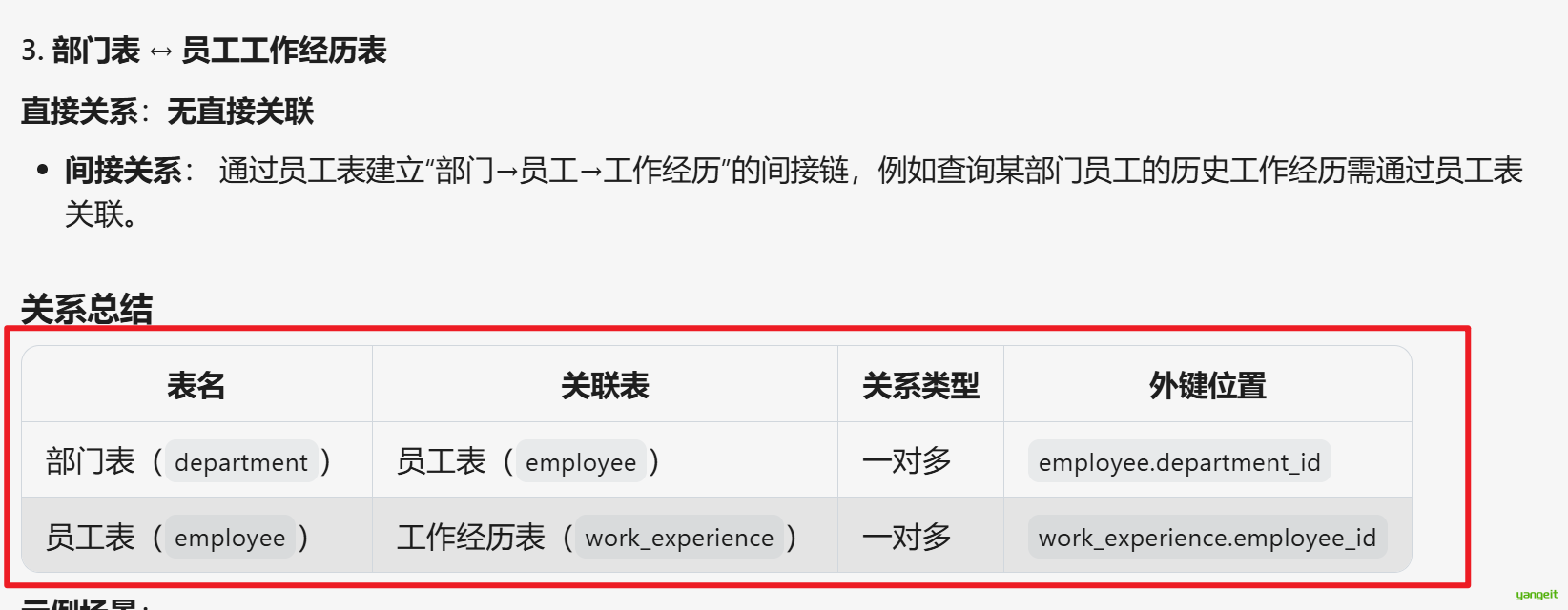
至此,数据库表关系分析就结束了,接下来,需要根据分析结果,设计数据库表。
提示
如果检查的结果不对,就需要继续提问,直到结果和原型页面能对应上为止!! AI编程就是不断和AI模型对话的过程,通过不断的对话,越来越接近真实需求。
总结
课堂作业
- 请结合页面原型和需求文档,分析一下部门和员工管理模块涉及几张表?具体是哪些表?🎤
- 使用AI编程只需要需求描述清楚就可以了,一次性就能成功,对吗?❓
- 和AI对话的过程中,如果发现分析结果不对,应该怎么处理?❓
4.1 数据库表设计
数据库表设计
上一节,我们分析了部门管理及员工管理模块,共涉及三张表,分别是:部门表、员工表、员工工作经历表,已经已经知道他们的关系了,接下来我们利用Deepseek完成建表语句的设计。
代码操作
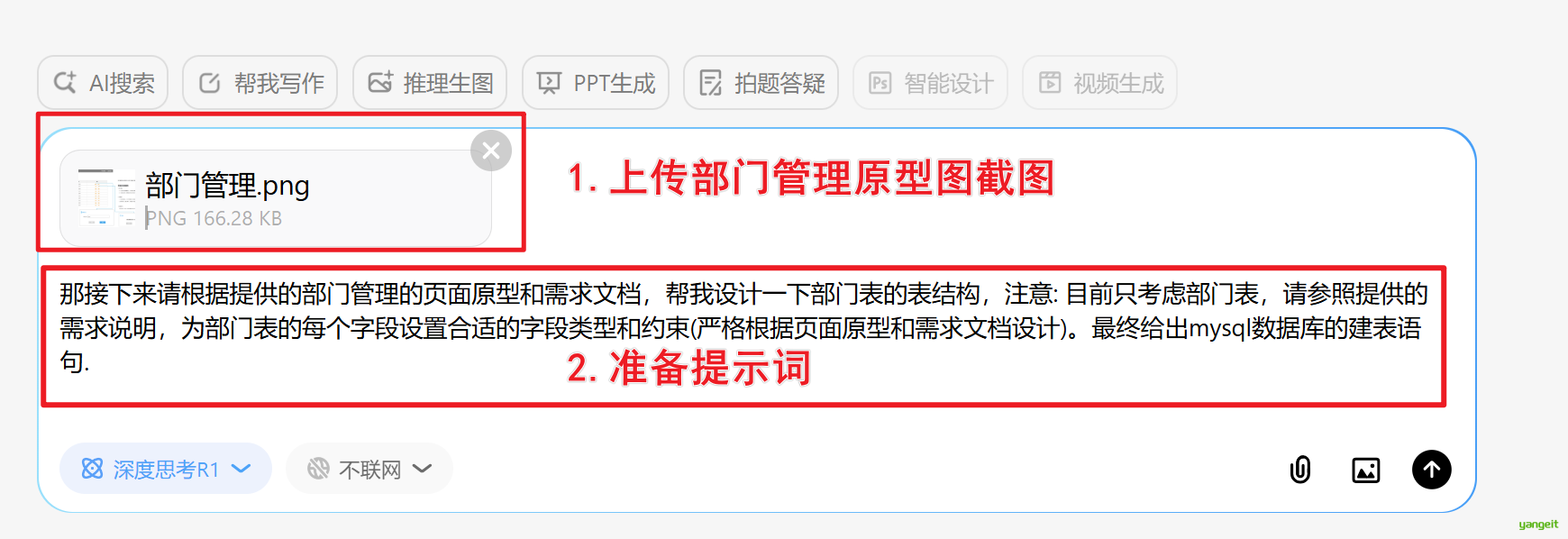
提示词
那接下来请根据提供的部门管理的页面原型和需求文档,
帮我设计一下部门表的表结构,
注意: 目前只考虑部门表,请参照提供的需求说明,
为部门表的每个字段设置合适的字段类型和约束(严格根据页面原型和需求文档设计)。
最终给出mysql数据库的建表语句.
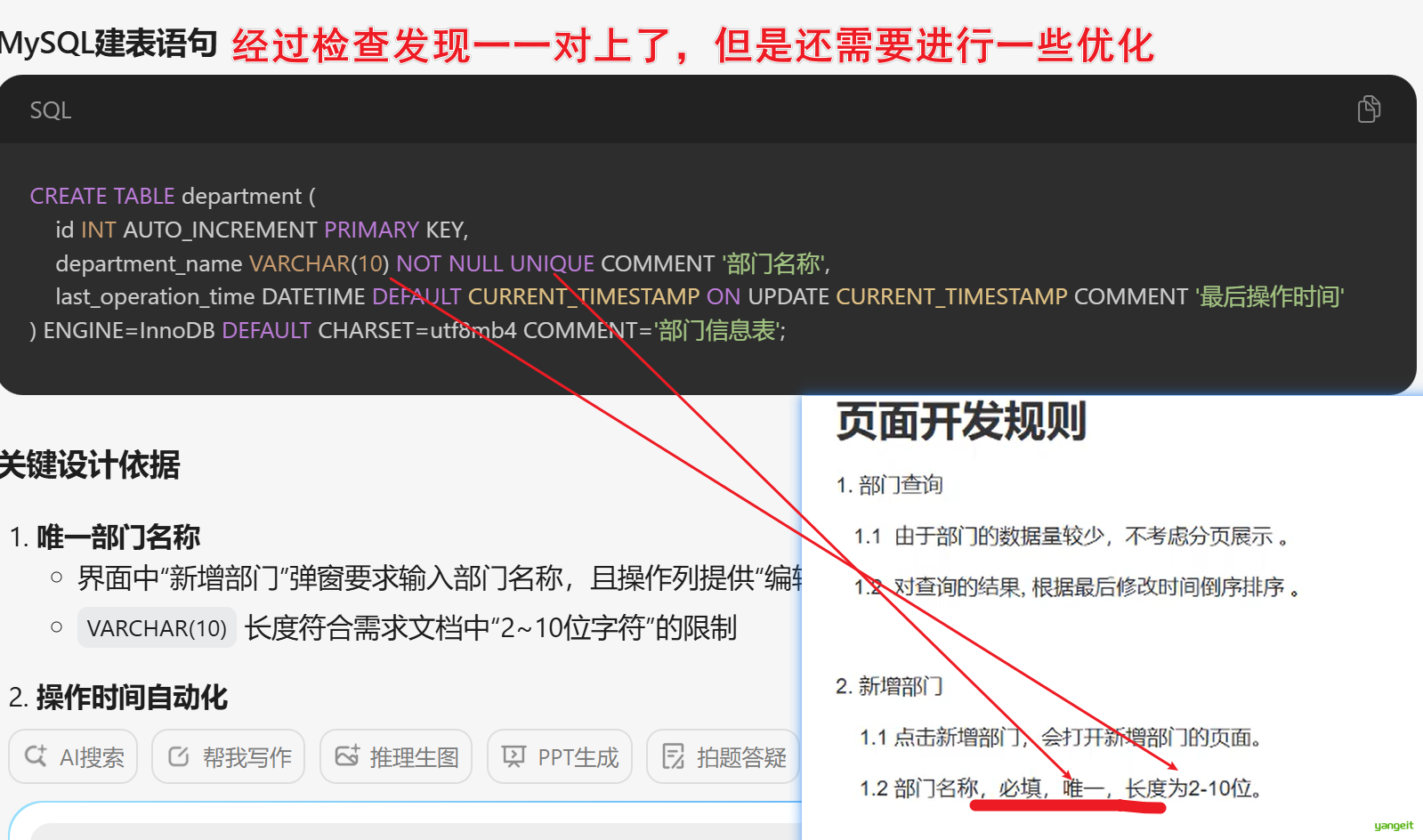
优化建表语句
部门表的建表语句,需要做以下调整
1.表名改为 dept;
2.department_name 字段名改为 name;
3.last operation time 字段名改为 update_time;
4.再增加一个字段 create time,记录创建时间的
5.时间类型设置为datetime类型
其他信息不变;
给出调整好的建表语句
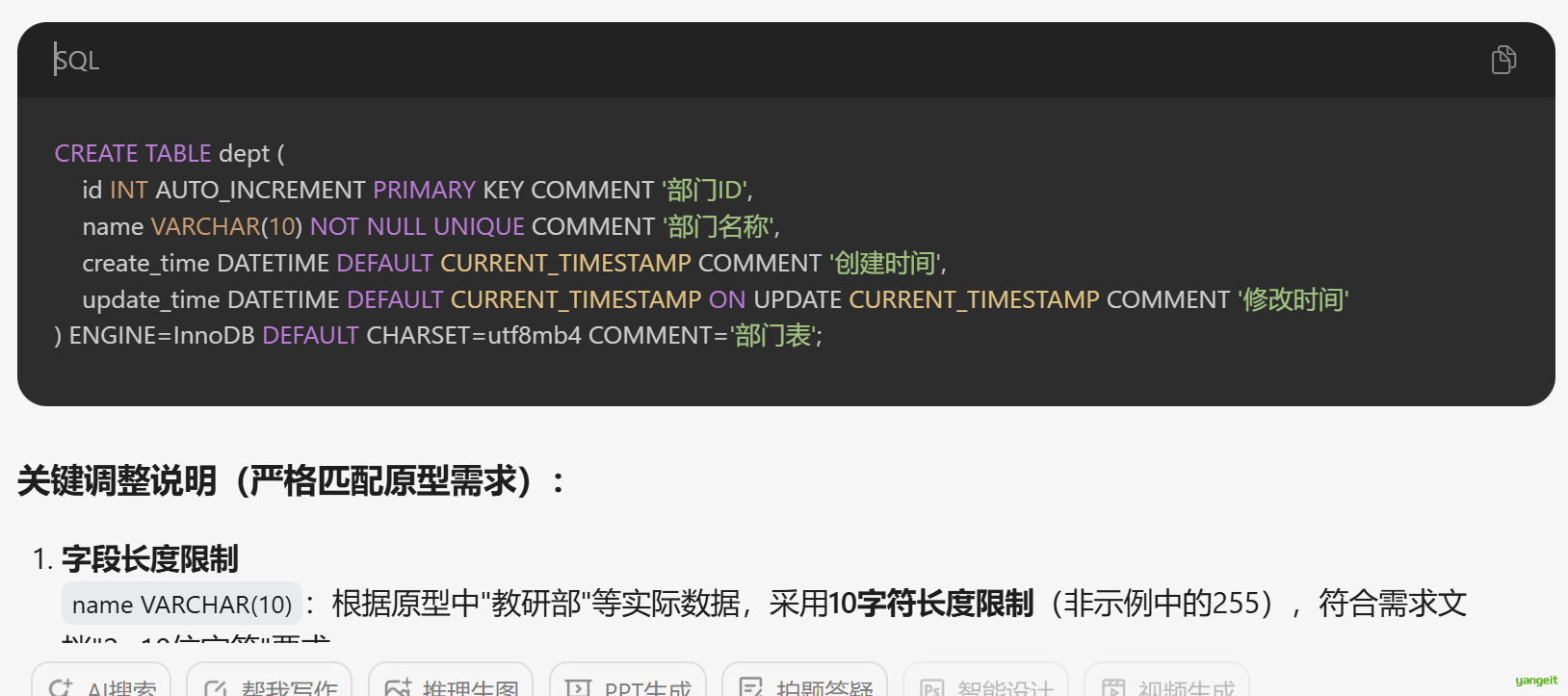
CREATE TABLE dept (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '部门ID',
name VARCHAR(10) NOT NULL UNIQUE COMMENT '部门名称',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='部门表';
至此,部门表设计完成,接下来,我们继续设计员工表。
- 接下来,我们继续设计员工表和员工经历表
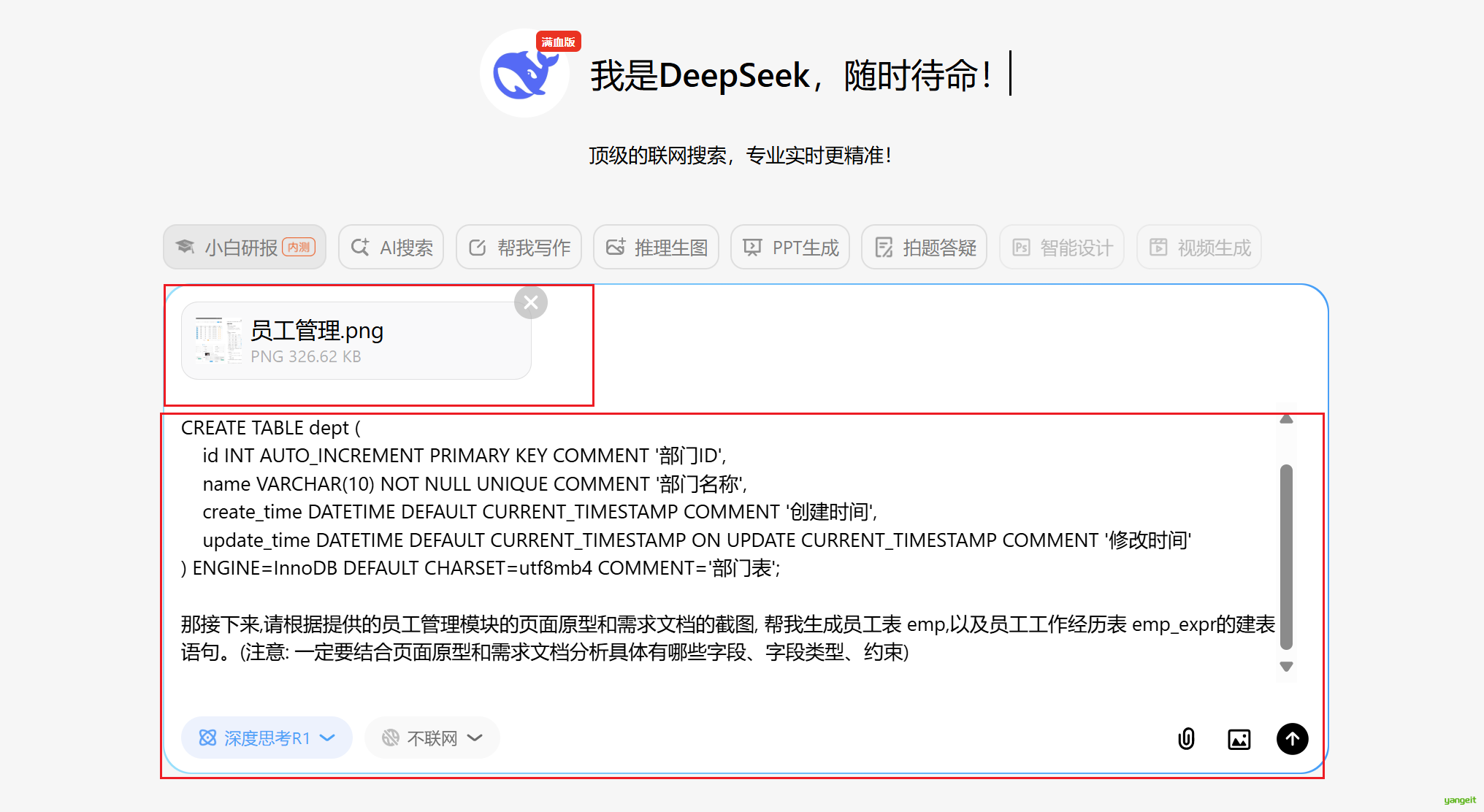
提示词如下:👇
部门表 dept的表结构已经确定了,表结构如下:
CREATE TABLE dept (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '部门ID',
name VARCHAR(10) NOT NULL UNIQUE COMMENT '部门名称',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='部门表';
那接下来,请根据提供的员工管理模块的页面原型和需求文档的截图, 帮我生成员工表 emp,以及员工工作经历表 emp_expr的建表语句。(注意: 一定要结合页面原型和需求文档分析具体有哪些字段、字段类型、约束)
2. 生成的结果和页面原型对比存在少许差距,需要继续调整
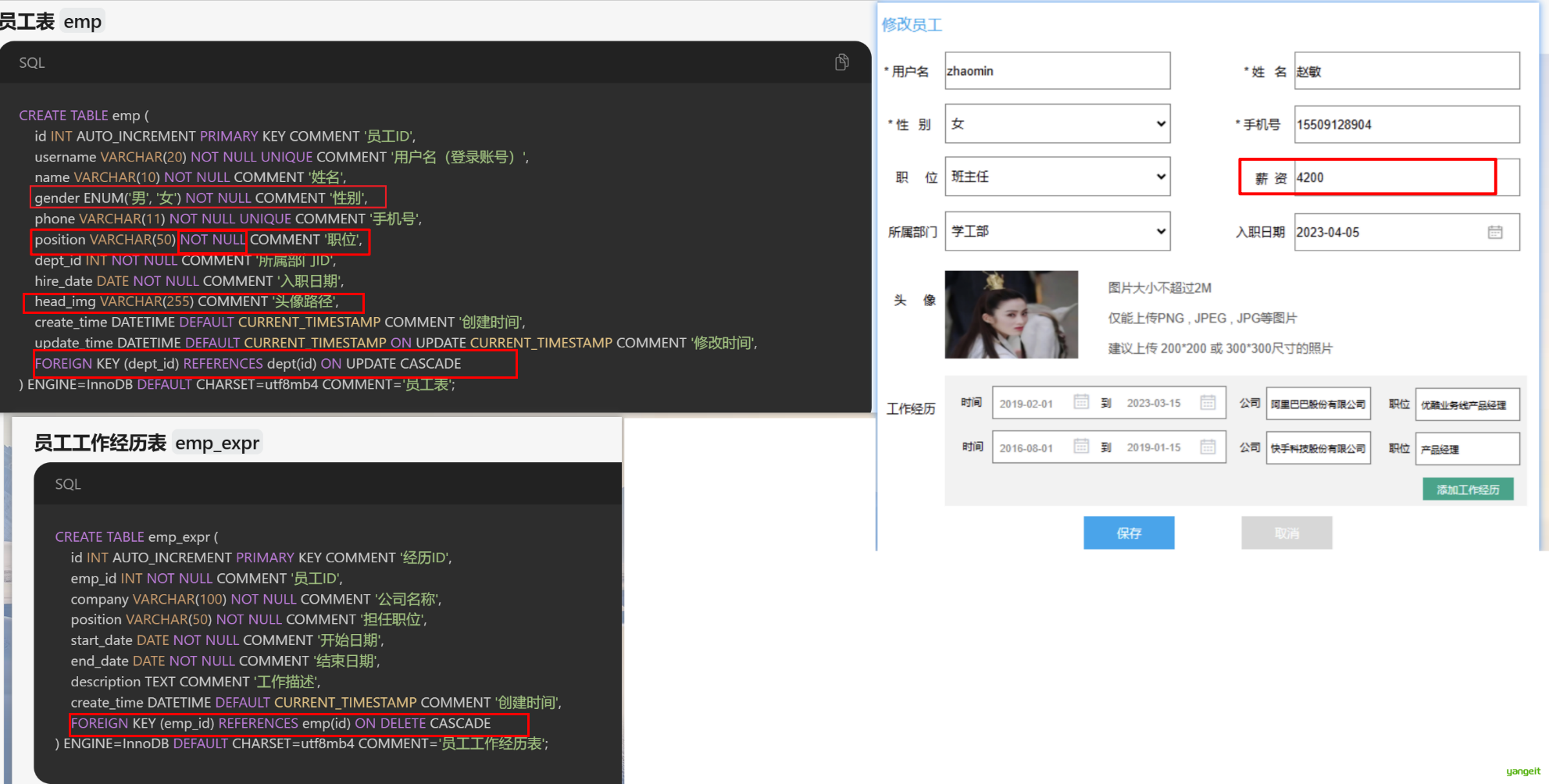
优化提示词:👇
员工表emp的建表语句,需要做以下调整:
1.主键id,类型调整为 int;
2.性别 gender 字段类型调整为 tinyint;注释改为'性别,1:男,2:女';
3.职位 position 字段类型调整为 tinyint;注释改为'职位,1:班主任,2:讲师,3:学工主管,4:教研主管,5:咨询师
4.薪资 salary 字段类型调整为 int;
5.头像 avator 字段名改为 image;去掉默认值;
6.入职日期 hire date 去掉 NOT NULL 非空约束 ;
7.所属部门 dept id 字段类型改为 int;
8.增加一个字段 create time,类型datetime,表示创建时间;
9.增加一个字段 password,类型 varchar(64)默认'123456';
10.去除掉外键约束,不要物理外键;
根据上述的描述调整这些字段(没有提到的字段,保留原样,不要调整),给出最终的建表语句。
员工工作经历表emp expr的建表语句,需要做以下调整!
1.主键 id,类型调整为 int;
2.emp id 字段类型调整为 int;
3.去除掉 company 、position、start date、end date的 NOT NULL 非空约束 ;
4:去除掉外键约束,不要物理外键;
根据上述的描述调整这些字段(没有提到的字段,保留原样,不要调整),给出最终的建表语句。
需要根据生成的结果,动态调整上述的优化提示词,确保生成的结果和页面原型一致。
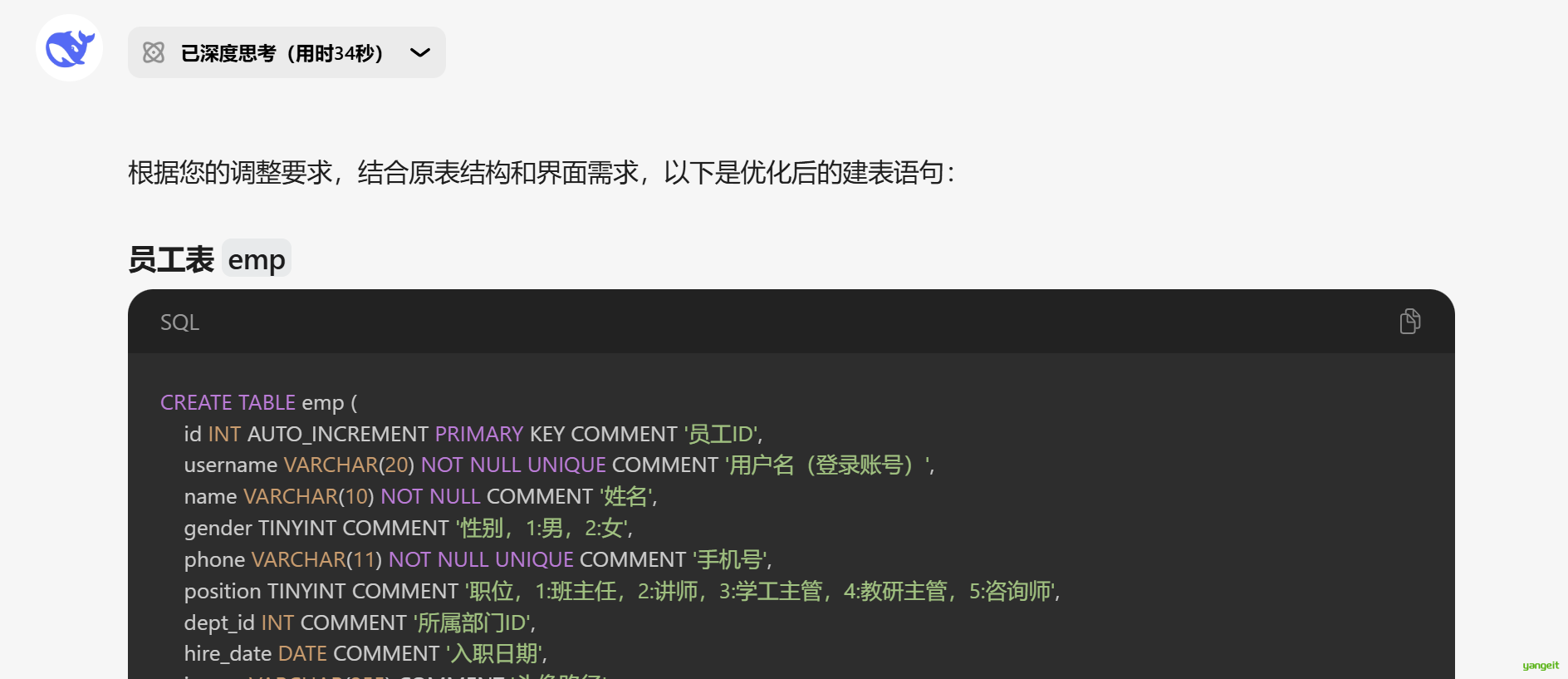
最终生成的建表语句如下:
-- 员工表
CREATE TABLE emp (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '员工ID',
username VARCHAR(20) NOT NULL UNIQUE COMMENT '用户名(登录账号)',
name VARCHAR(10) NOT NULL COMMENT '姓名',
gender TINYINT COMMENT '性别,1:男,2:女',
phone VARCHAR(11) NOT NULL UNIQUE COMMENT '手机号',
position TINYINT COMMENT '职位,1:班主任,2:讲师,3:学工主管,4:教研主管,5:咨询师',
dept_id INT COMMENT '所属部门ID',
hire_date DATE COMMENT '入职日期',
image VARCHAR(255) COMMENT '头像路径',
salary INT COMMENT '薪资',
password VARCHAR(64) DEFAULT '123456' COMMENT '密码',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='员工表';
-- 员工工作经历表
CREATE TABLE emp_expr (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '经历ID',
emp_id INT COMMENT '员工ID',
company VARCHAR(100) COMMENT '公司名称',
position VARCHAR(50) COMMENT '担任职位',
start_date DATE COMMENT '开始日期',
end_date DATE COMMENT '结束日期',
description TEXT COMMENT '工作描述',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='员工工作经历表';
建表语句生成后,将建表语句喂给Deepseek,生成测试数据,方便未来项目开发。
提示词如下:👇
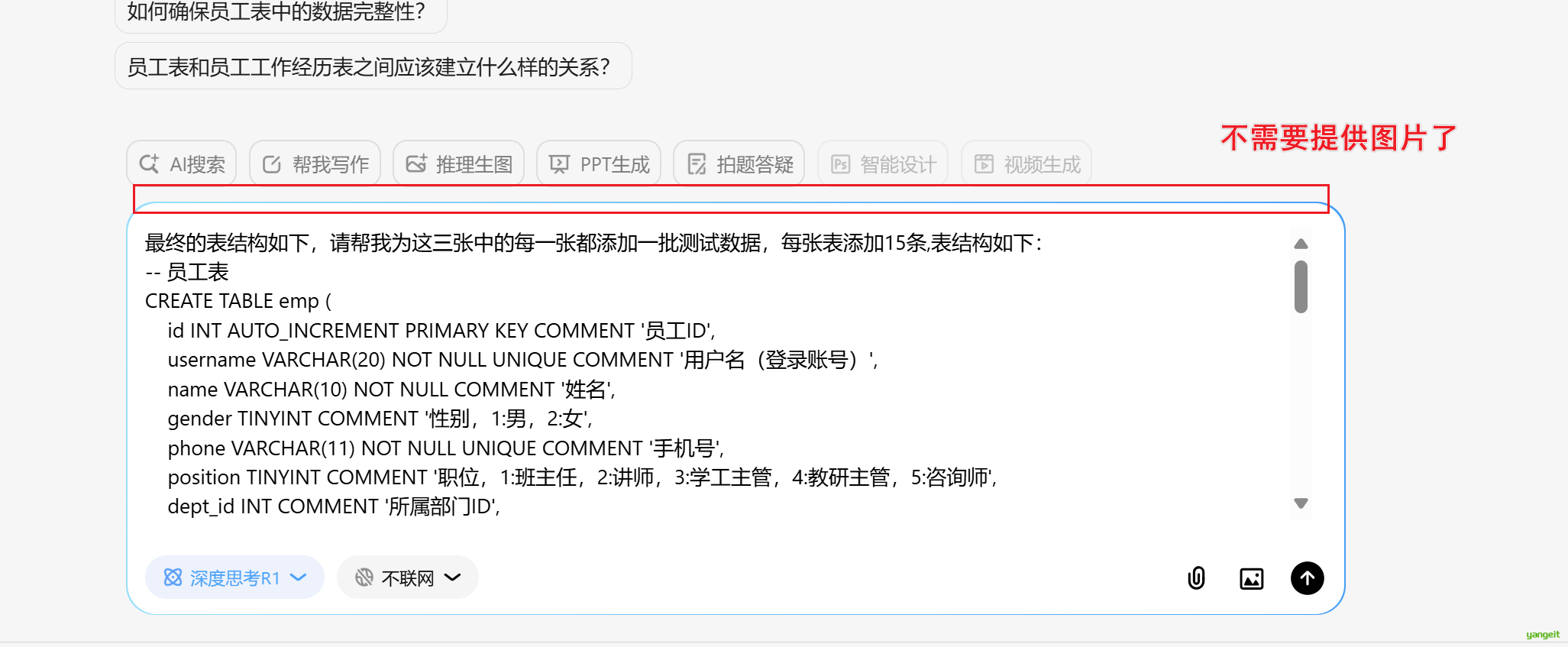
最终的表结构如下,请帮我为这三张中的每一张都添加一批测试数据,每张表添加15条,表结构如下:
-- 员工表
CREATE TABLE emp (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '员工ID',
username VARCHAR(20) NOT NULL UNIQUE COMMENT '用户名(登录账号)',
name VARCHAR(10) NOT NULL COMMENT '姓名',
gender TINYINT COMMENT '性别,1:男,2:女',
phone VARCHAR(11) NOT NULL UNIQUE COMMENT '手机号',
position TINYINT COMMENT '职位,1:班主任,2:讲师,3:学工主管,4:教研主管,5:咨询师',
dept_id INT COMMENT '所属部门ID',
hire_date DATE COMMENT '入职日期',
image VARCHAR(255) COMMENT '头像路径',
salary INT COMMENT '薪资',
password VARCHAR(64) DEFAULT '123456' COMMENT '密码',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='员工表';
-- 员工工作经历表
CREATE TABLE emp_expr (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '经历ID',
emp_id INT COMMENT '员工ID',
company VARCHAR(100) COMMENT '公司名称',
position VARCHAR(50) COMMENT '担任职位',
start_date DATE COMMENT '开始日期',
end_date DATE COMMENT '结束日期',
description TEXT COMMENT '工作描述',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='员工工作经历表';
-- 部门表
CREATE TABLE dept (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '部门ID',
name VARCHAR(10) NOT NULL UNIQUE COMMENT '部门名称',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='部门表';
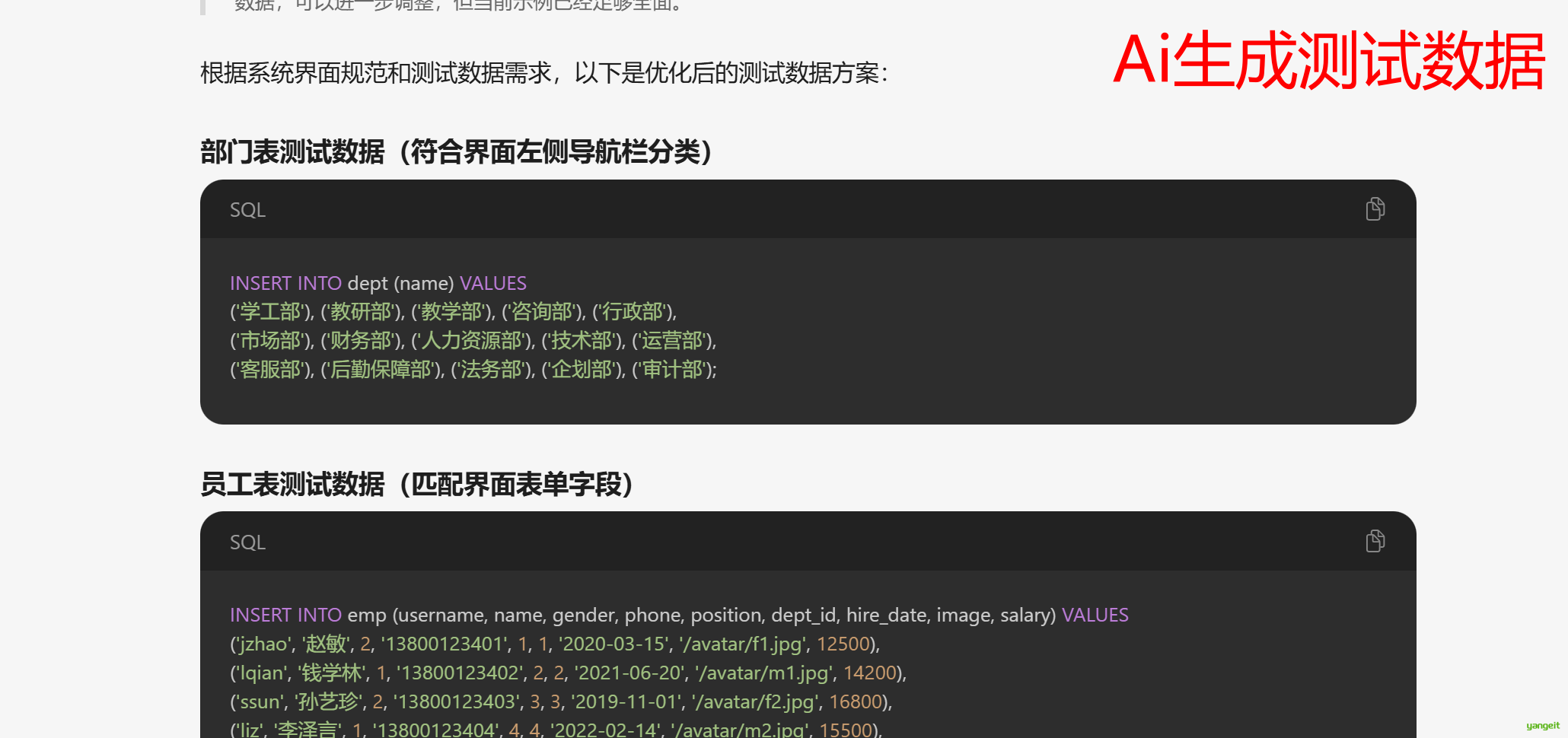
测试数据如下:
INSERT INTO dept (name) VALUES
('学工部'), ('教研部'), ('教学部'), ('咨询部'), ('行政部'),
('市场部'), ('财务部'), ('人力资源部'), ('技术部'), ('运营部'),
('客服部'), ('后勤保障部'), ('法务部'), ('企划部'), ('审计部');
INSERT INTO emp (username, name, gender, phone, position, dept_id, hire_date, image, salary) VALUES
('jzhao', '赵敏', 2, '13800123401', 1, 1, '2020-03-15', '/avatar/f1.jpg', 12500),
('lqian', '钱学林', 1, '13800123402', 2, 2, '2021-06-20', '/avatar/m1.jpg', 14200),
('ssun', '孙艺珍', 2, '13800123403', 3, 3, '2019-11-01', '/avatar/f2.jpg', 16800),
('liz', '李泽言', 1, '13800123404', 4, 4, '2022-02-14', '/avatar/m2.jpg', 15500),
('zhouy', '周雨彤', 2, '13800123405', 5, 5, '2023-01-05', '/avatar/f3.jpg', 13600),
('wujy', '吴嘉怡', 2, '13800123406', 1, 6, '2020-09-11', '/avatar/f4.jpg', 11800),
('zhengm', '郑明轩', 1, '13800123407', 2, 7, '2021-12-25', '/avatar/m3.jpg', 14700),
('fans', '范思哲', 1, '13800123408', 3, 8, '2018-05-30', '/avatar/m4.jpg', 17500),
('chenl', '陈莉莉', 2, '13800123409', 4, 9, '2022-07-18', '/avatar/f5.jpg', 16200),
('hanx', '韩雪', 2, '13800123410', 5, 10, '2023-04-09', '/avatar/f6.jpg', 14200),
('luoy', '罗云熙', 1, '13800123411', 1, 11, '2019-08-22', '/avatar/m5.jpg', 13200),
('yangm', '杨幂', 2, '13800123412', 2, 12, '2020-10-31', '/avatar/f7.jpg', 15200),
('zhangsn', '张颂文', 1, '13800123413', 3, 13, '2021-03-17', '/avatar/m6.jpg', 18500),
('baob', '白百合', 2, '13800123414', 4, 14, '2022-09-05', '/avatar/f8.jpg', 16500),
('huangx', '黄晓明', 1, '13800123415', 5, 15, '2023-07-01', '/avatar/m7.jpg', 15800);
INSERT INTO emp_expr (emp_id, company, position, start_date, end_date, description) VALUES
(1, '新东方教育', '学习顾问', '2018-07-01', '2020-02-28', '负责学员课程规划与学习进度跟踪'),
(2, '中科院计算所', 'AI研究员', '2019-03-01', '2021-05-31', '参与自然语言处理项目研发'),
(3, '腾讯科技', '产品经理', '2017-09-01', '2019-10-31', '主导教育类产品全生命周期管理'),
(4, '华为技术', '云计算架构师', '2018-01-15', '2022-01-14', '设计企业级云平台解决方案'),
(5, '德勤咨询', '高级顾问', '2020-06-01', '2022-12-31', '为金融企业提供数字化转型方案'),
(6, '字节跳动', '用户运营', '2019-11-01', '2020-08-31', '策划用户增长活动提升DAU指标'),
(7, '阿里云', '解决方案专家', '2018-05-01', '2021-09-30', '输出行业云解决方案白皮书'),
(8, '百度研究院', '算法工程师', '2016-09-01', '2018-04-30', '开发推荐系统核心算法模块'),
(9, '京东零售', '数据分析师', '2020-02-01', '2022-06-30', '构建用户画像与精准营销模型'),
(10, '美团点评', '产品运营', '2019-07-01', '2023-03-31', '优化本地生活服务运营流程'),
(11, '网易教育', '课程设计师', '2017-03-01', '2019-12-31', '开发在线编程课程体系'),
(12, '拼多多', '活动策划', '2018-08-01', '2020-10-31', '策划双十一大促活动方案'),
(13, '小米科技', '硬件工程师', '2016-06-01', '2018-11-30', '参与智能家居设备研发'),
(14, '滴滴出行', '安全风控', '2019-04-01', '2021-07-31', '构建行程安全预警系统'),
(15, '快手科技', '内容运营', '2018-12-01', '2020-05-31', '管理短视频创作者生态');
4.4 数据库创建
数据库创建
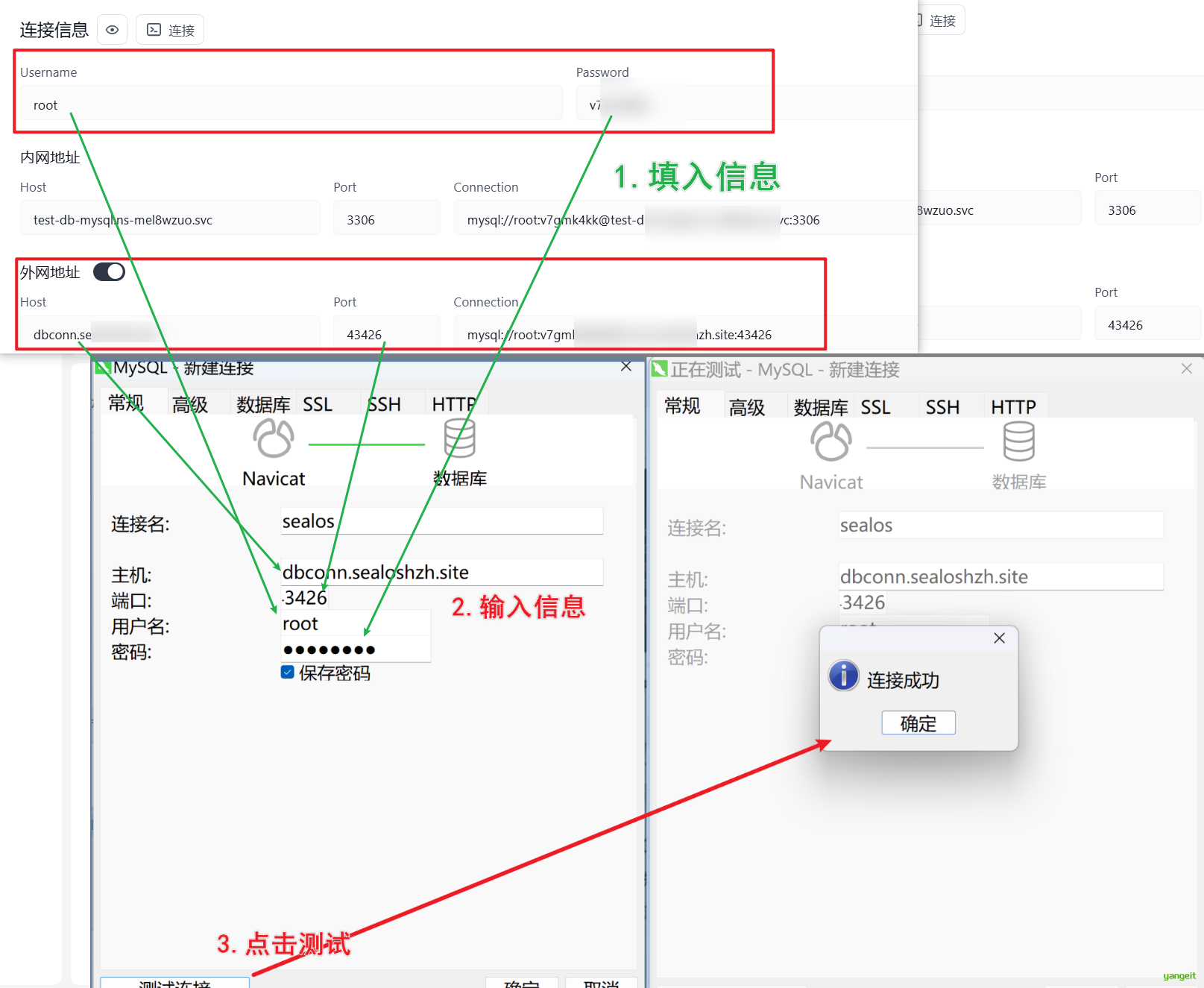
在Sealos中创建数据库,然后使用Navicat连接数据库,执行sql语句,创建表。
代码操作

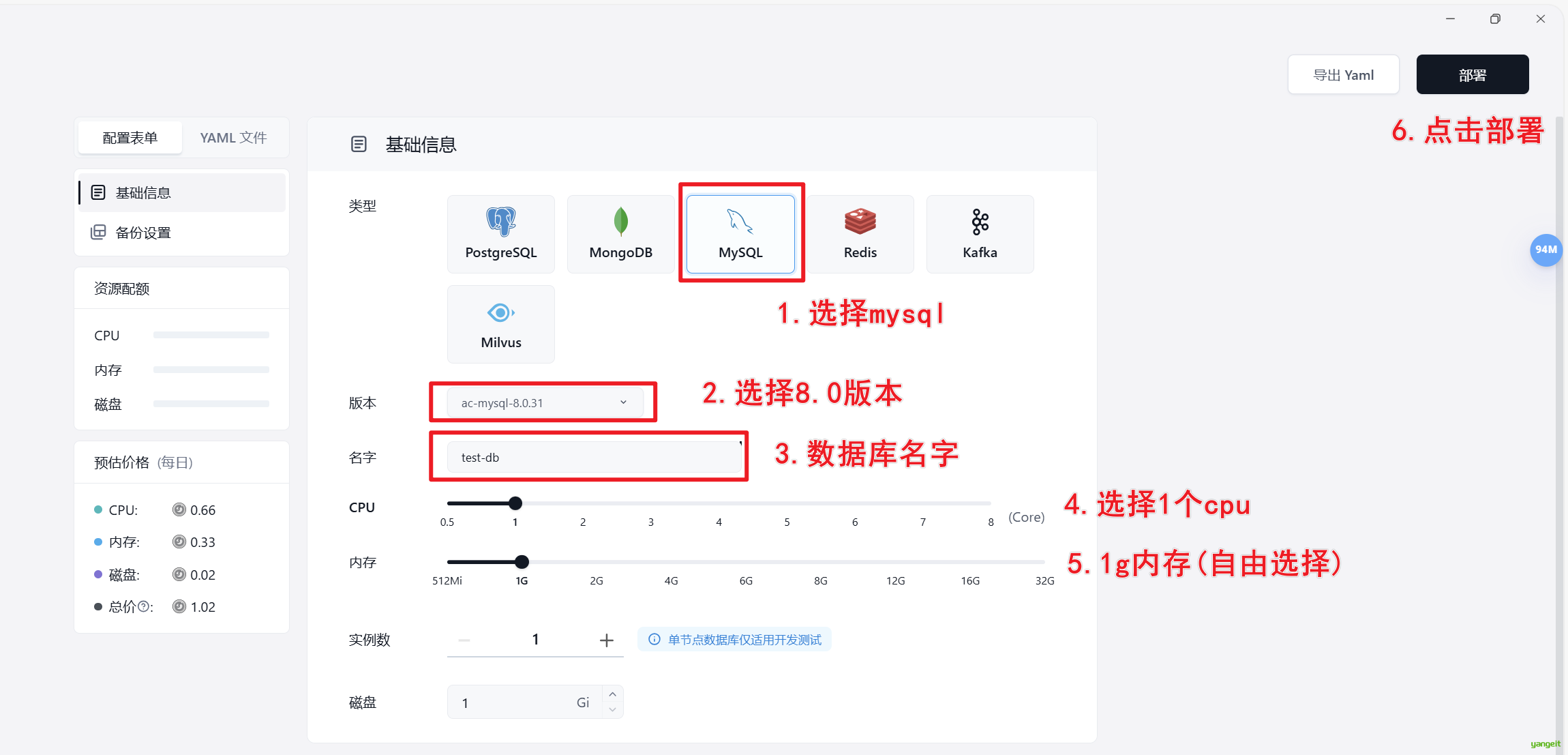
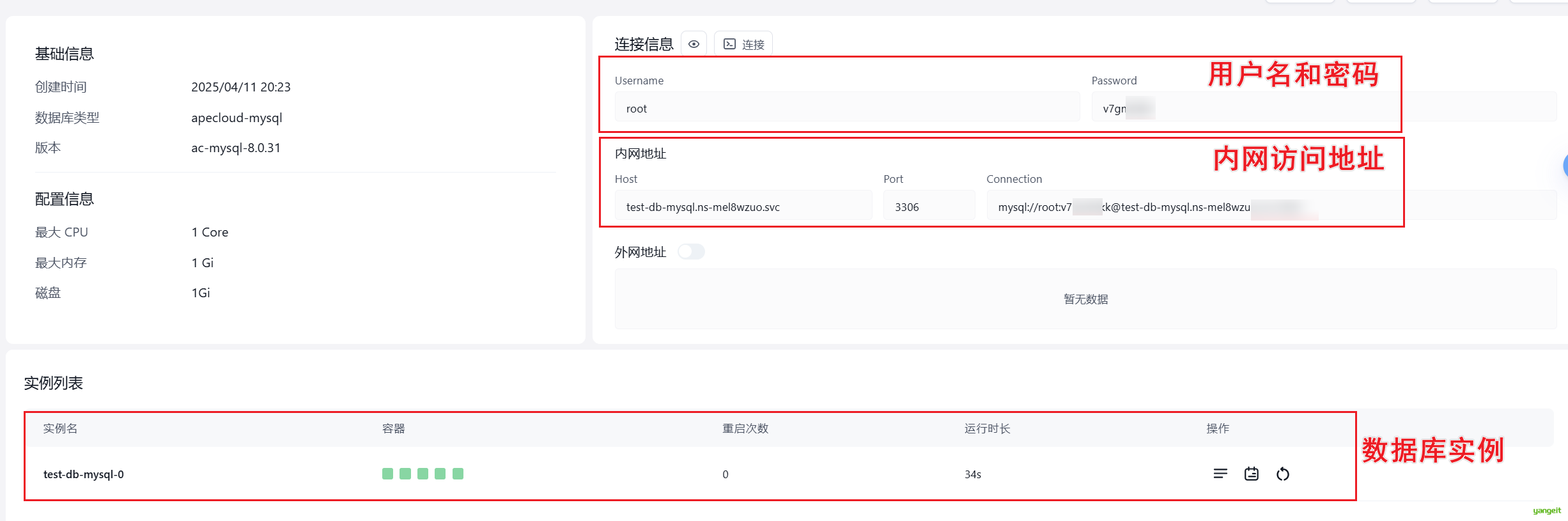

- 链接Navicat,输入数据库链接信息,测试连接是否成功。
Navicat是一款数据库管理工具,可以连接MySQL、Oracle、SQL Server等数据库,方便用户进行数据库操作。自行下载安装,百度搜索即可。
- 操作Navicat,执行sql语句,观察表和数据是否ok
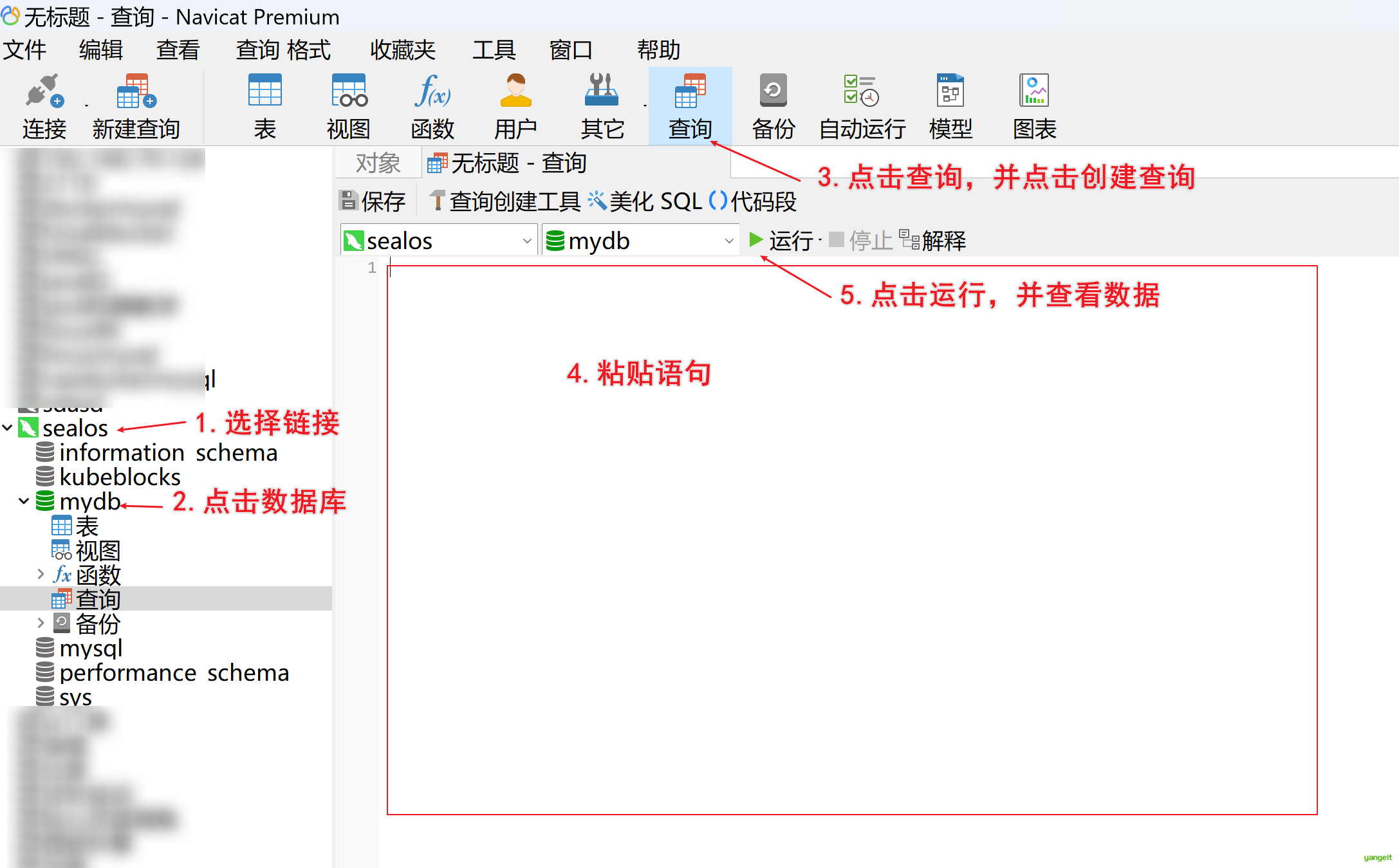
3.插入操作:👇 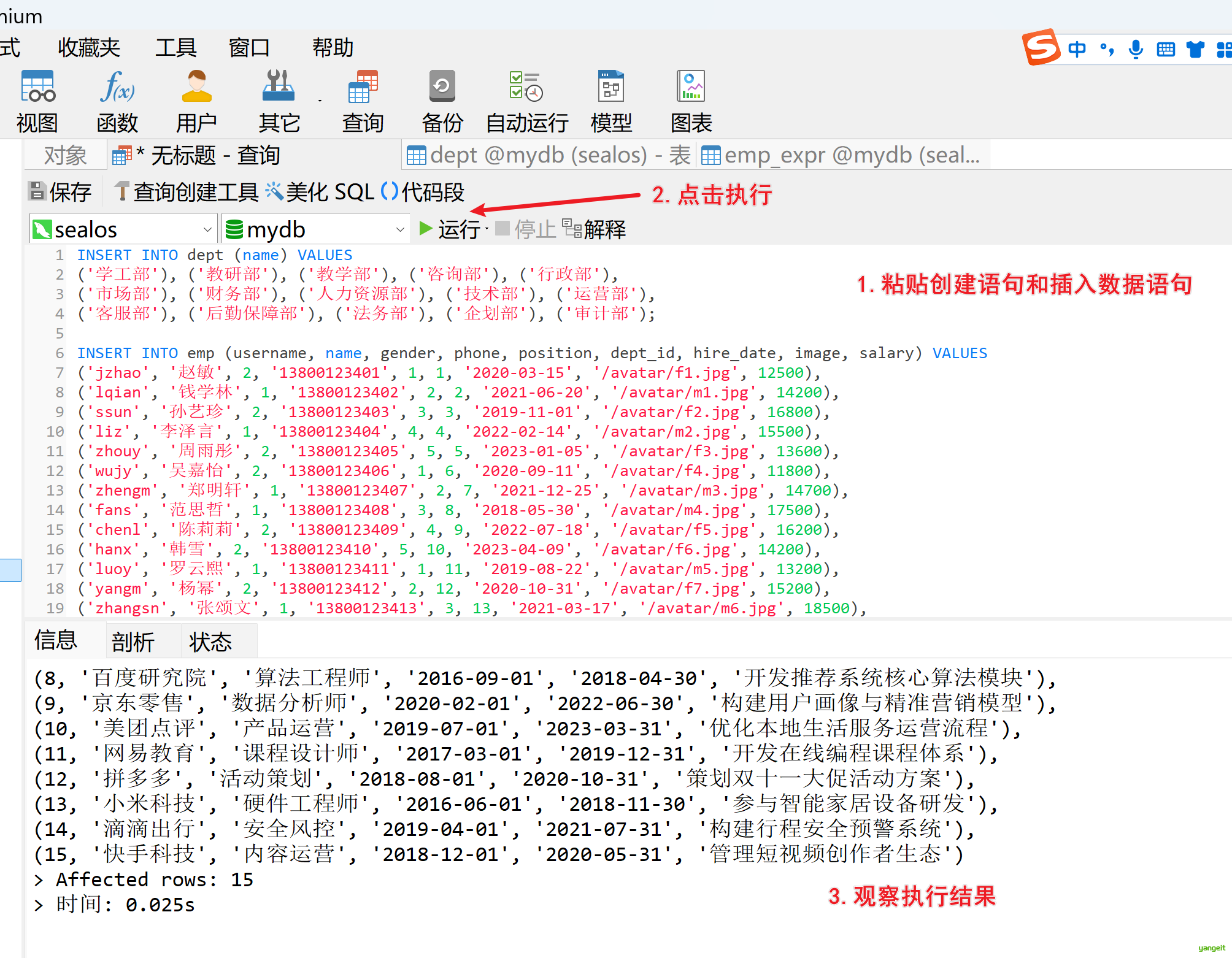
4.数据插入成功:👇 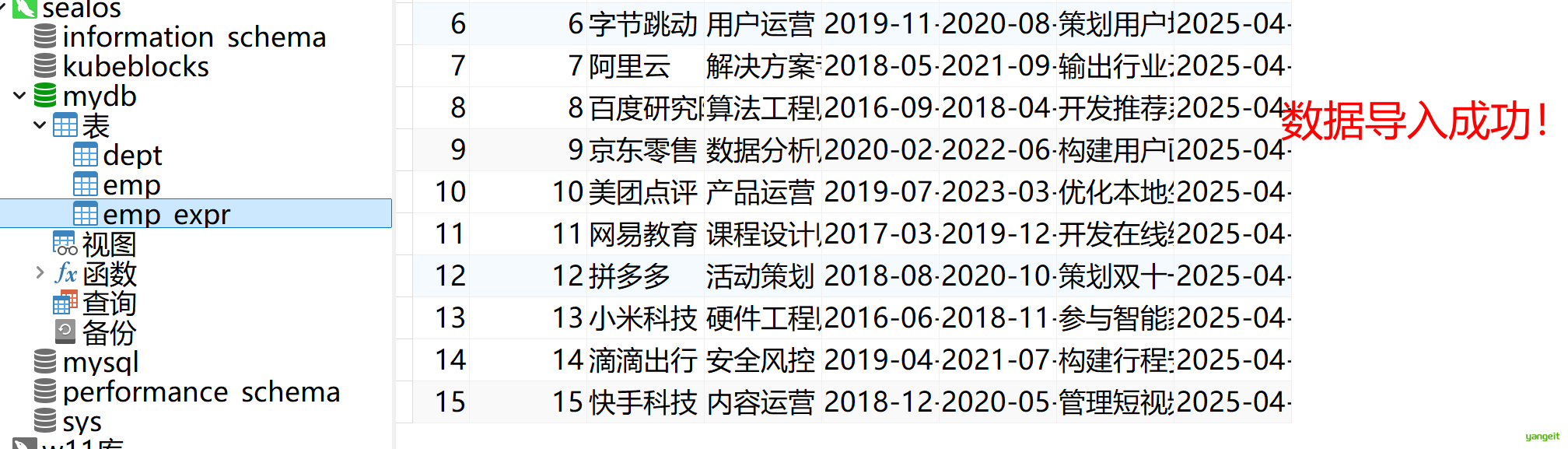
总结
课堂作业
- 参考上述操作,完成sealos云系统操作,创建数据库,并执行sql语句,创建表。🎤
注意
因为sealos是按时间收费的,所以请尽快完成操作,然后销毁数据库,以免产生不必要的费用。