Part02 ☀️
Part02 ☀️
课程内容
- 大模型部署
- 大模型介绍 🍐
- Ollama安装和使用 ✏️
- Chatbox ✏️
- RAG知识讲解🍐
- 创建本地知识库 ✏️
- 知识库
- Obsidian介绍和安装 ✏️
- Obsidian常规使用 ✏️
- Obsidian集成大模型和RAG功能 ✏️
- Obsidian实战操作 ✏️
1 大模型部署
1.1 大模型介绍
前言
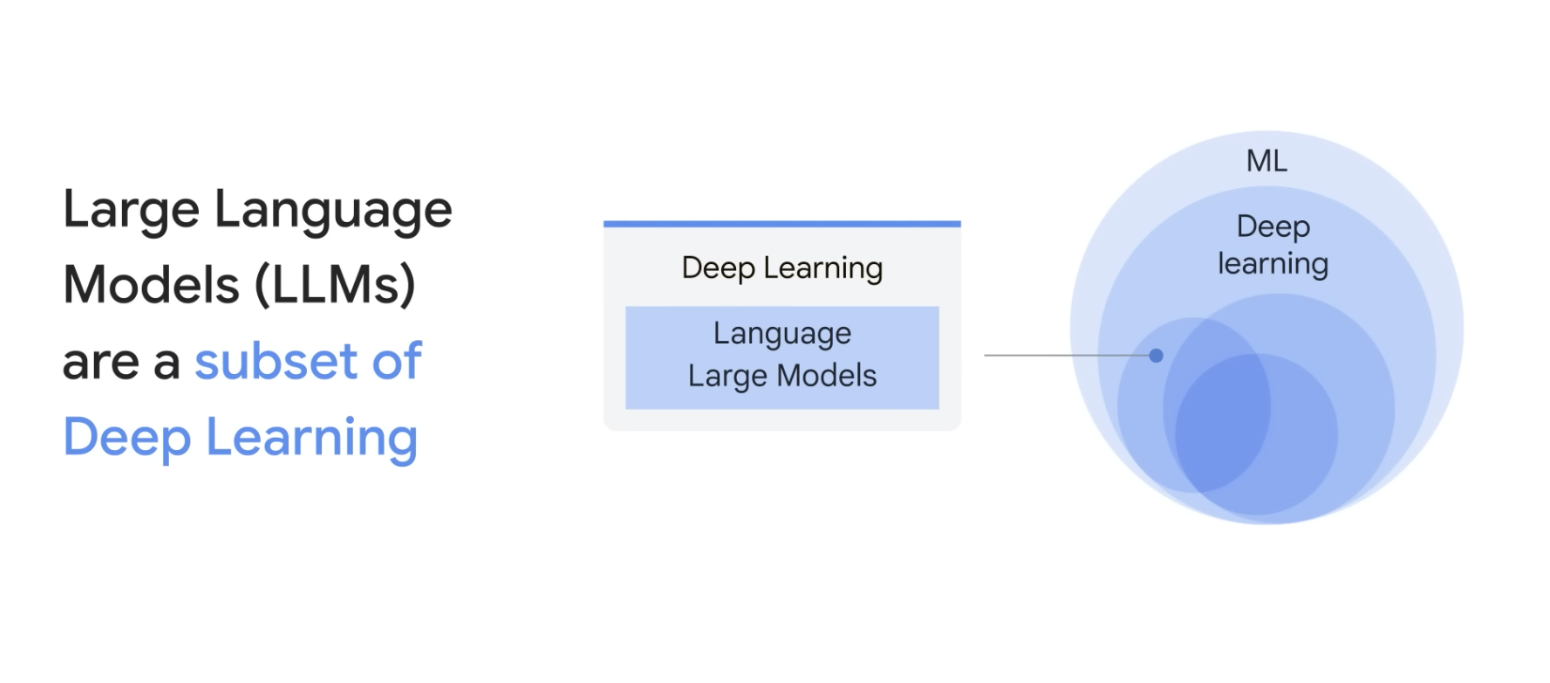
1. 什么是大模型?
大语言模型(LLM, Large Language Model) 是一种基于Transformer架构的深度学习模型,通过预训练大量文本数据,能够理解和生成人类语言。
核心特点
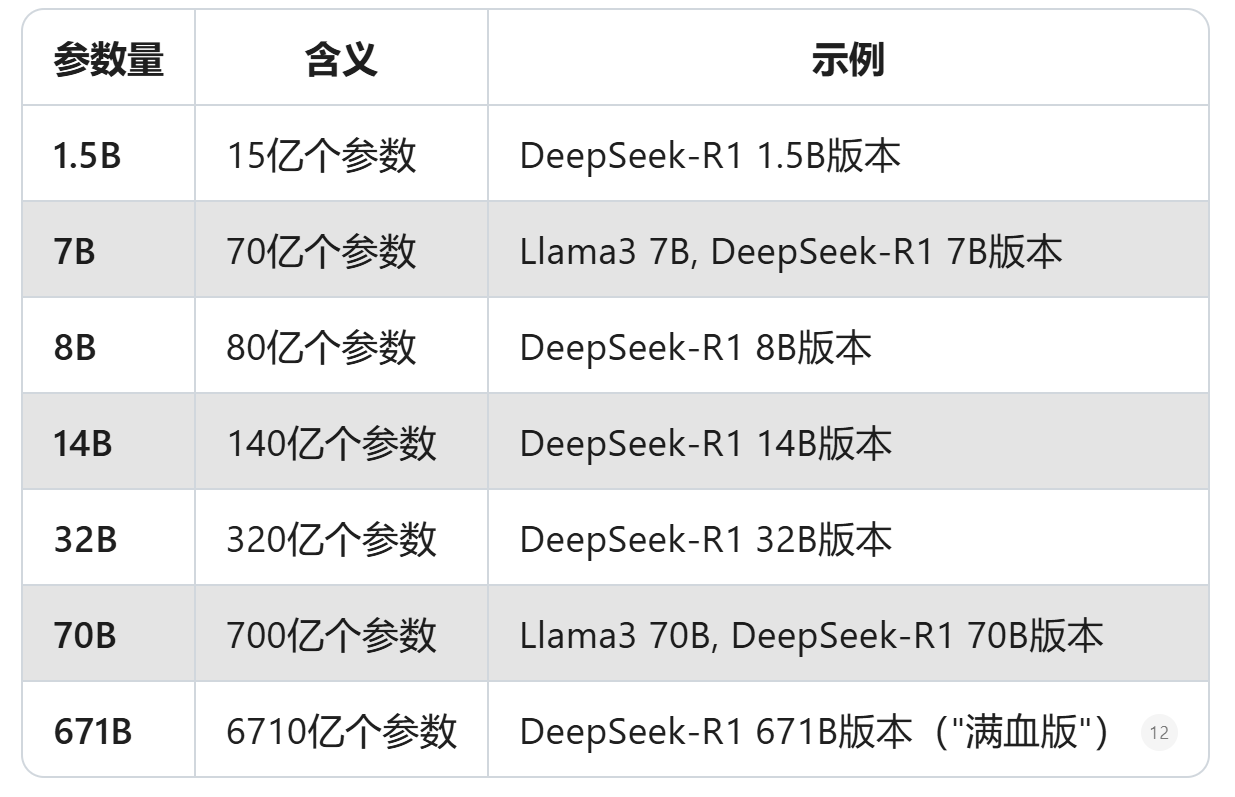
- 参数量巨大:从1.5B到671B不等
- 自监督学习:无需人工标注数据
- 多任务能力:文本生成、问答、翻译、编程等
- 上下文理解:能够理解长文本的语义

2. 参数量解析:1.5B、7B、14B...到底是什么意思?
B = Billion(十亿),这是国际通用的参数量表示方式。
参数量与性能的关系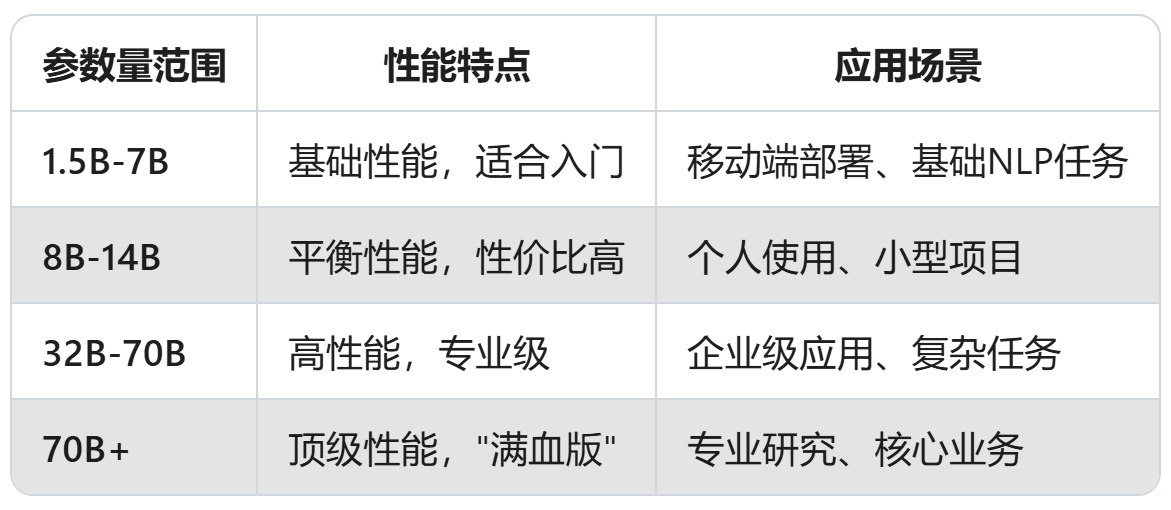
3. 主流开源大模型大盘点
🏆 Top 5 开源大模型
- Meta LLaMA 3
- 版本:8B、70B
- 特点:通过RLHF微调,性能媲美闭源模型
- 优势:开源透明,可自由定制优化
- 应用:聊天机器人、编程任务、多语言处理
2. DeepSeek-R1 : ❤️
- 版本:1.5B、7B、8B、14B、32B、70B、671B
- 特点:参数量跨度极大,从轻量级到顶级性能
- 优势:灵活选择,适应不同硬件配置
- 应用场景:从个人学习到企业级部署
3. GPT-NeoX
- 版本:GPT-NeoX-20B
- 特点:200亿参数,开源替代GPT
- 优势:高性能,代码生成能力强
4. Qwen系列 ❤️
- 版本:0.5B到72B全尺寸覆盖
- 特点:中文支持优秀,多模态能力强
- 优势:本地化适配,企业级应用成熟
4. 硬件配置要求详解
🖥️ 内存(RAM)要求
根据Ollama官方推荐:
| 模型大小 | 最低RAM要求 | 推荐RAM | 说明 |
|---|---|---|---|
| 1.5B | 4GB | 8GB | 轻量级,适合入门 |
| 7B | 8GB | 16GB | 标准配置,性价比高 |
| 13B-14B | 16GB | 32GB | 平衡性能,主流选择 |
| 32B-70B | 32GB | 64GB+ | 高性能,需要强大硬件 |
📱 其他硬件要求
- CPU:现代多核处理器(4核+)
- GPU:显存≥模型大小(如7B模型需要≥8GB显存)
- 在NPU(神经网络处理单元)上部署大模型可以显著提升推理效率,适用于自然语言处理等场景
- 存储:SSD,空间≥模型文件大小(通常几十GB)
5. 大模型核心特点与优势
🎯 核心能力综合表
| 能力维度 | 具体功能 | 特点说明 |
|---|---|---|
| 📊 多模态处理能力 | 文本生成、问答、翻译 | 基础语言理解与生成能力 |
| 代码生成与调试 | 编程辅助与错误修复能力 | |
| 图像描述生成 | 视觉内容理解与描述 | |
| 🔄 自学习能力 | 无需人工标注数据 | 自监督学习机制 |
| 持续优化学习效果 | 随使用时间提升性能 | |
| 适应不同领域知识 | 跨领域泛化能力 | |
| 🧠 上下文理解 | 长文本处理能力 | 理解复杂、长篇内容 |
| 逻辑推理能力 | 推理、分析与判断 | |
| 跨领域知识整合 | 综合多领域信息 |
📊 性能指标对比
| 模型 | 参数量 | 推理速度 | 准确性 | 资源消耗 |
|---|---|---|---|---|
| Llama3-8B | 8B | 快速 | 高 | 中等 |
| DeepSeek-7B | 7B | 快速 | 高 | 中等 |
| Llama3-70B | 70B | 较慢 | 极高 | 高 |
| DeepSeek-671B | 671B | 很慢 | 顶级 | 极高 |
总结
课堂作业
- 参数量含义:B = Billion(十亿),直接影响模型性能和硬件需求
- 主流模型:LLaMA 3、DeepSeek-R1、Mistral、GPT-NeoX、Qwen等
- 配置要求:内存需求与模型大小直接相关,7B模型需要8GB+内存
- 应用价值:从个人学习到企业级应用,适用场景广泛
1.2 Ollama安装和使用
Ollama安装和使用

1、基本介绍
Ollama是一个支持在Windows、Linux和MacOS上本地运行大语言模型的工具。它允许用户非常方便地运行和使用各种大语言模型,比如Qwen模型等。用户只需一行命令就可以启动模型 。
主要特点包括:
- 跨平台支持Windows、Linux、MacOS系统。
- 提供了丰富的模型库,包括Qwen、Llama等1700+大语言模型,可以在官网model library中直接下载使用。
- 支持用户上传自己的模型。用户可以将huggingface等地方的ggml格式模型导入到ollama中使用。也可以将基于pytorch等格式的模型转换为ggml格式后导入。
- 允许用户通过编写modelfile配置文件来自定义模型的推理参数,如temperature、top_p等,从而调节模型生成效果。
- 支持多GPU并行推理加速。在多卡环境下,可以设置环境变量来指定特定GPU。
总的来说,Ollama降低了普通开发者使用大语言模型的门槛,使得本地部署体验大模型变得简单易行。对于想要搭建自己的AI应用,或者针对特定任务调优模型的开发者来说,是一个非常有用的工具。它的一些特性,如允许用户自定义模型参数,对模型进行个性化适配提供了支持。
2、官网和下载链接
Ollama 下载:https://ollama.com/download
Ollama 官方主页:https://ollama.com
Ollama 官方 GitHub 源代码仓库:https://github.com/ollama/ollama/
说明:在国内下载速度很慢!!,容易出现下载失败的情况,建议使用VPN下载。
3、安装教程
1. 选择安装文件,右击管理员运行安装

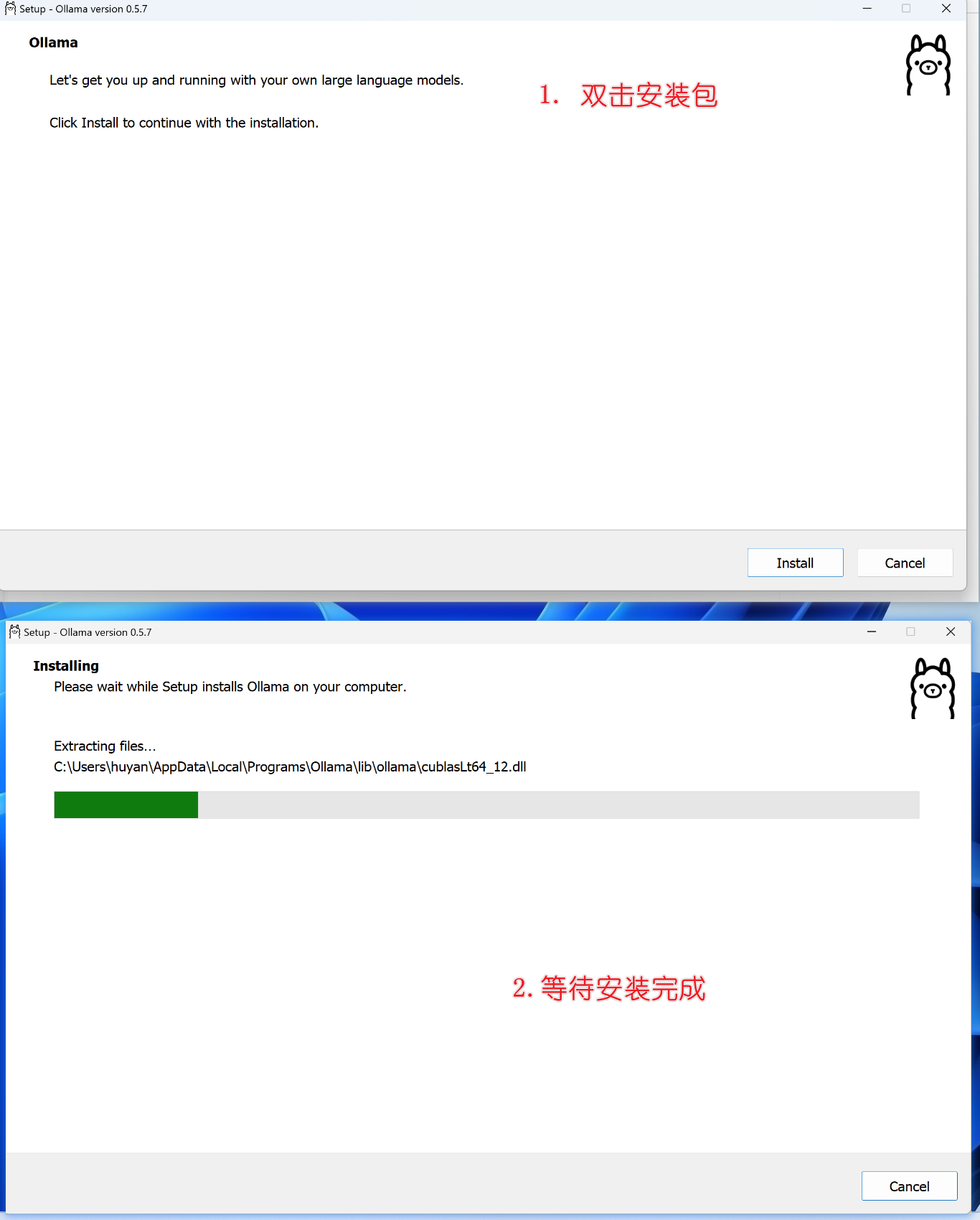
2. 在window中,默认的位置在C盘(如下👇),后期的模型下载也会在C盘,但是模型文件比较大,占用存储空间,推荐安装在其他盘。
C:\Users\用户名\AppData\Local\Programs\Ollama
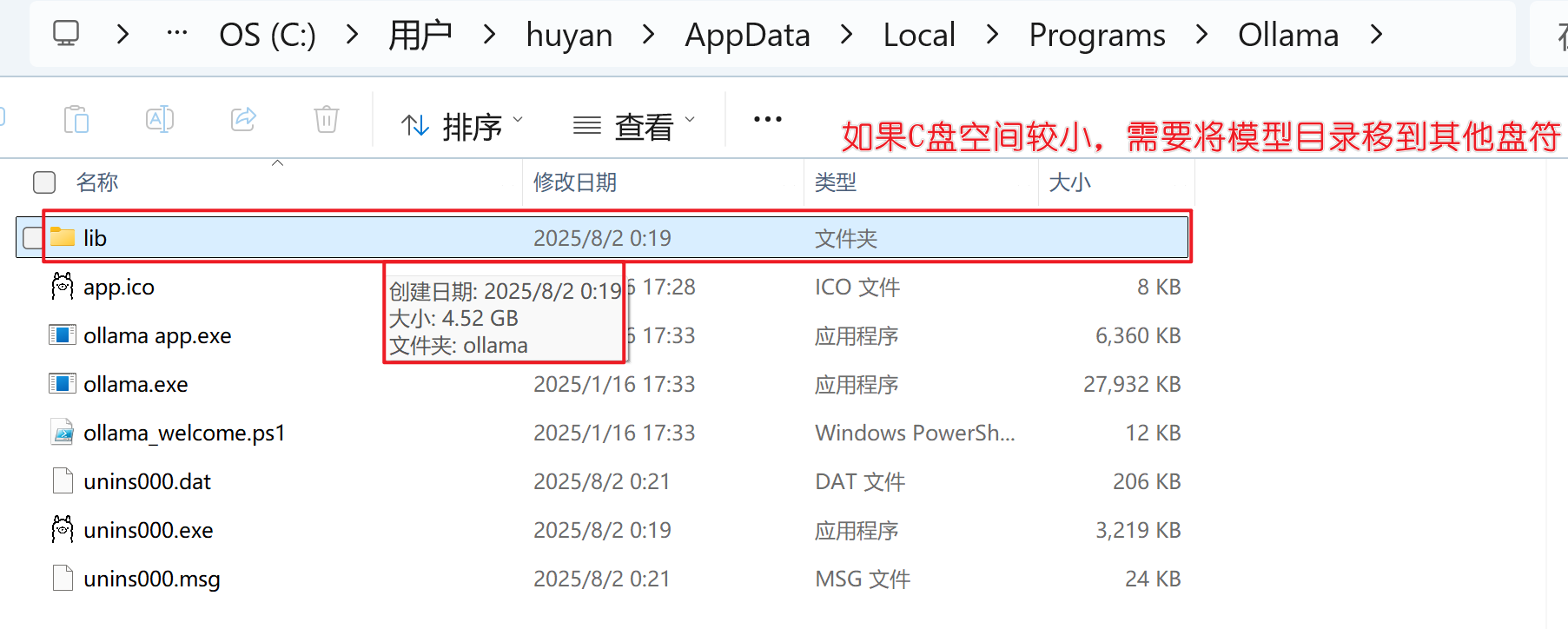
3. 配置环境变量。将模型目录配置到其他的路径如:D:\javasoftware\Ollama\models
右键我的电脑-->属性-->高级系统设置-->环境变量-->系统环境变量 -->新增-->输入OLLAMA_MODELS :D:\javasoftware\Ollama\models
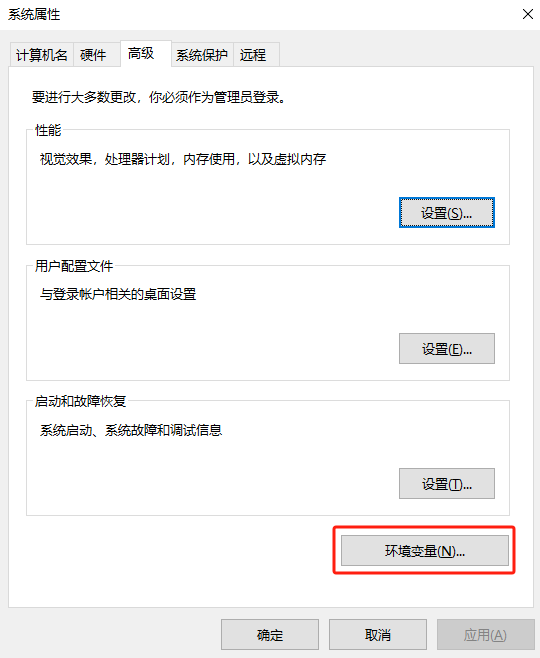
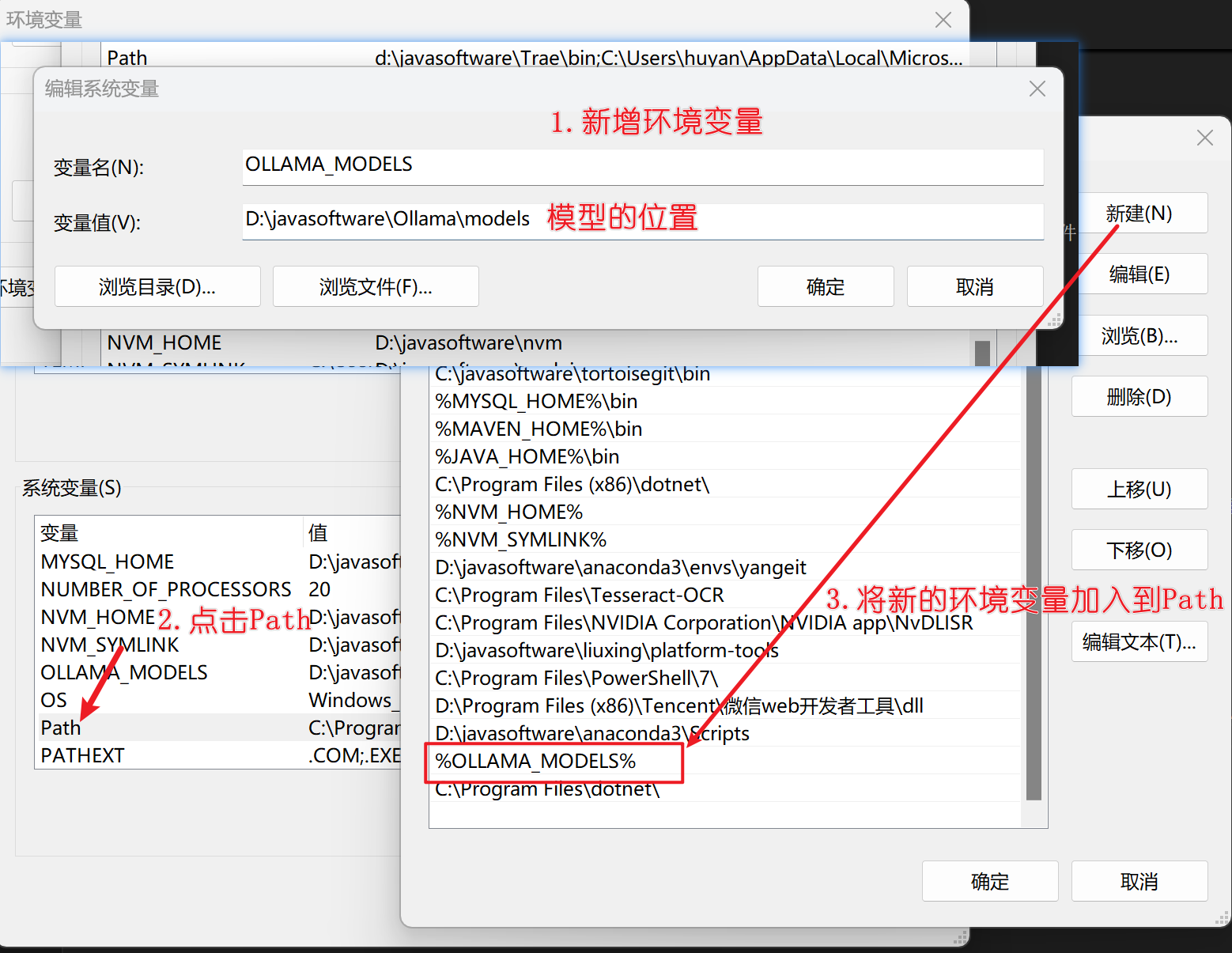 上图是配置环境变量,然后停止Ollama服务(观察右下角的任务栏是否有Ollama图标, 如果是英特尔优化版,直接关闭cmd窗口即可,如下图👇)
上图是配置环境变量,然后停止Ollama服务(观察右下角的任务栏是否有Ollama图标, 如果是英特尔优化版,直接关闭cmd窗口即可,如下图👇) 
4. Ollama指令
# 1、打开cmd窗口,启动Ollama 服务(cmd窗口不要关闭,启动后关闭则服务不启动):
ollama serve
# 可以使用ollama -v查看版本。使用-h 查看帮助命令
#2、拉取模型
ollama pull <模型名字>
#如拉取deepseek-r1:1.5b模型:
ollama pull deepseek-r1:1.5b
#3、下载完成后,运行:ollama list 查看下载的模型列表,
ollama list
#返回下载的结果:模型名字---模型id---模型占用的大小---修改时间
NAME ID SIZE MODIFIED
bge-m3:latest 790764642607 1.2 GB 16 hours ago
deepseek-r1:7b 755ced02ce7b 4.7 GB 17 hours ago
qwen3:8b 500a1f067a9f 5.2 GB 18 hours ago
#4、启动Ollama
ollama run deepseek-r1:1.5b
#5、启动后,可以在黑窗口中输入想问的话,如:"你是谁",然后按回车键,即可得到回复。,如图7所示。
#6、如果想退出,按Ctrl+D即可,即可停止退出对话
#7、 查看正在运行的模型
ollama ps
#返回结果: 模型名字---模型id---模型占用的大小---cpu或gpu占比---运行了多久
NAME ID SIZE PROCESSOR UNTIL
deepseek-r1:7b 755ced02ce7b 6.0 GB 43%/57% CPU/GPU 2 minutes from now
#8、停止模型:
ollama stop <模型名字> #如停止deepseek-r1:7b模型:
ollama stop deepseek-r1:7b
# 可以再次执行ollama ps 查看是否停止
#9、删除模型:
ollama rm <模型名字> #如删除deepseek-r1:7b模型:
ollama rm deepseek-r1:7b
# 可以再次执行ollama list 查看是否删除
# 补充:可以在一开始就直接运行ollama run xxx ,可以直接运行某个模型并运行,如图8所示


注意,如果下载到后期速度很慢,可以Ctrl+C停止下载,然后重新运行下载指令即可,速度会快很多。如图9所示。

总结
课堂作业
安装ollama,并配置环境变量,和deepseek-r1:1.5b模型(比较小,大概1.1g),然后在黑窗口中输入问题并得到回答!microphone:
如果有时间,花点时间下载deepseek-r1:7b模型,和嵌入模型bge-m3:latest
ollama pull deepseek-r1:7b
ollama pull bge-m3
# 调用ollama list 查看下载情况
1.3 Chatbox
前言
考虑到Ollama的cmd黑窗口不方便,所以我们开发了一款Chatbox AI,方便本地部署和聊天使用
Chatbox AI 是一款 AI 客户端应用和智能助手,支持众多先进的 AI 模型和 API,可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用
Chatbox AI旨在为用户提供一个简单易用的可视化界面,让非专业技术人员也能便捷地与各种AI模型进行交互
在官网点击下载后,安装此程序,如下👇
安装后后,启动,设置关联到本地模型
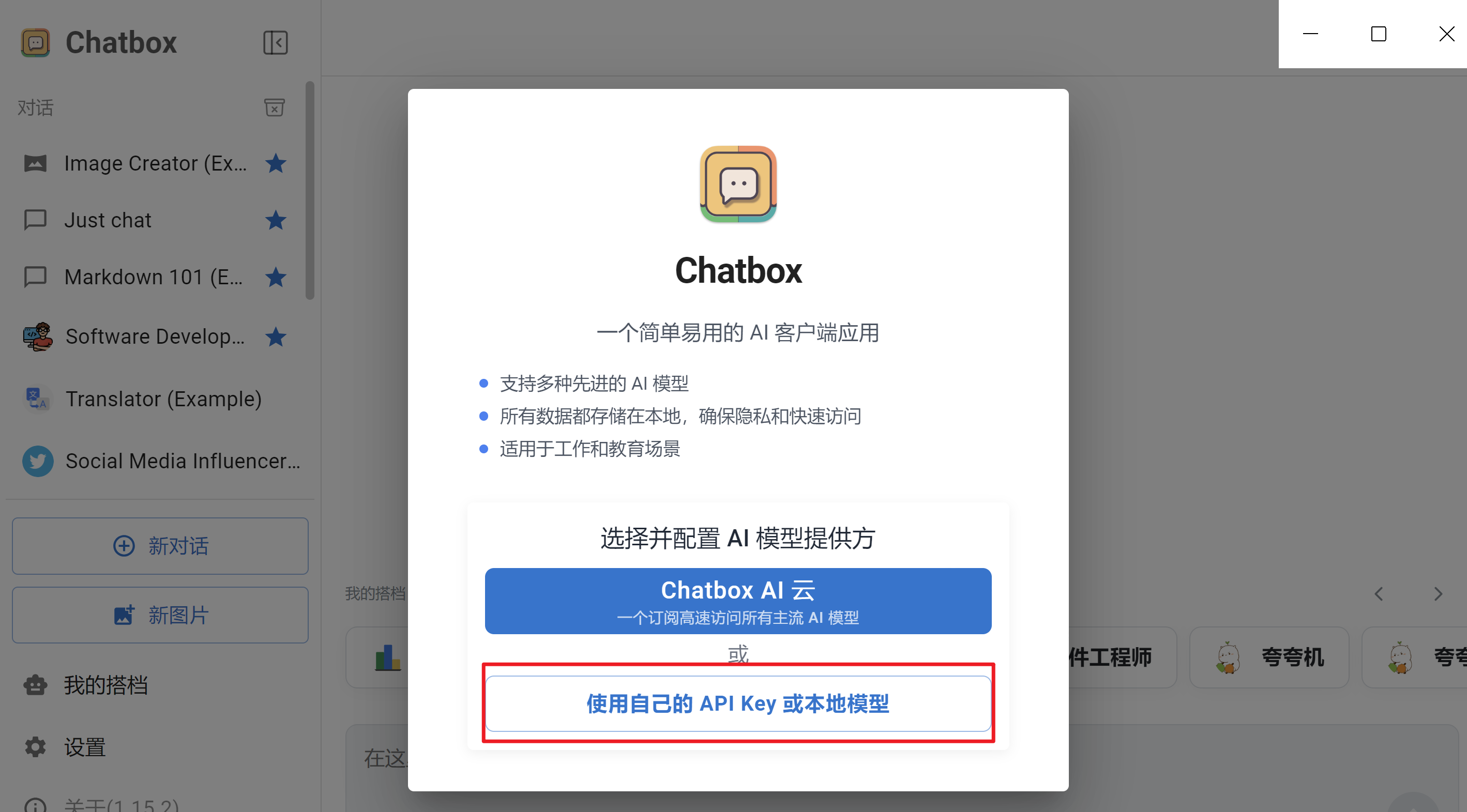
AI模型配置选择Ollama
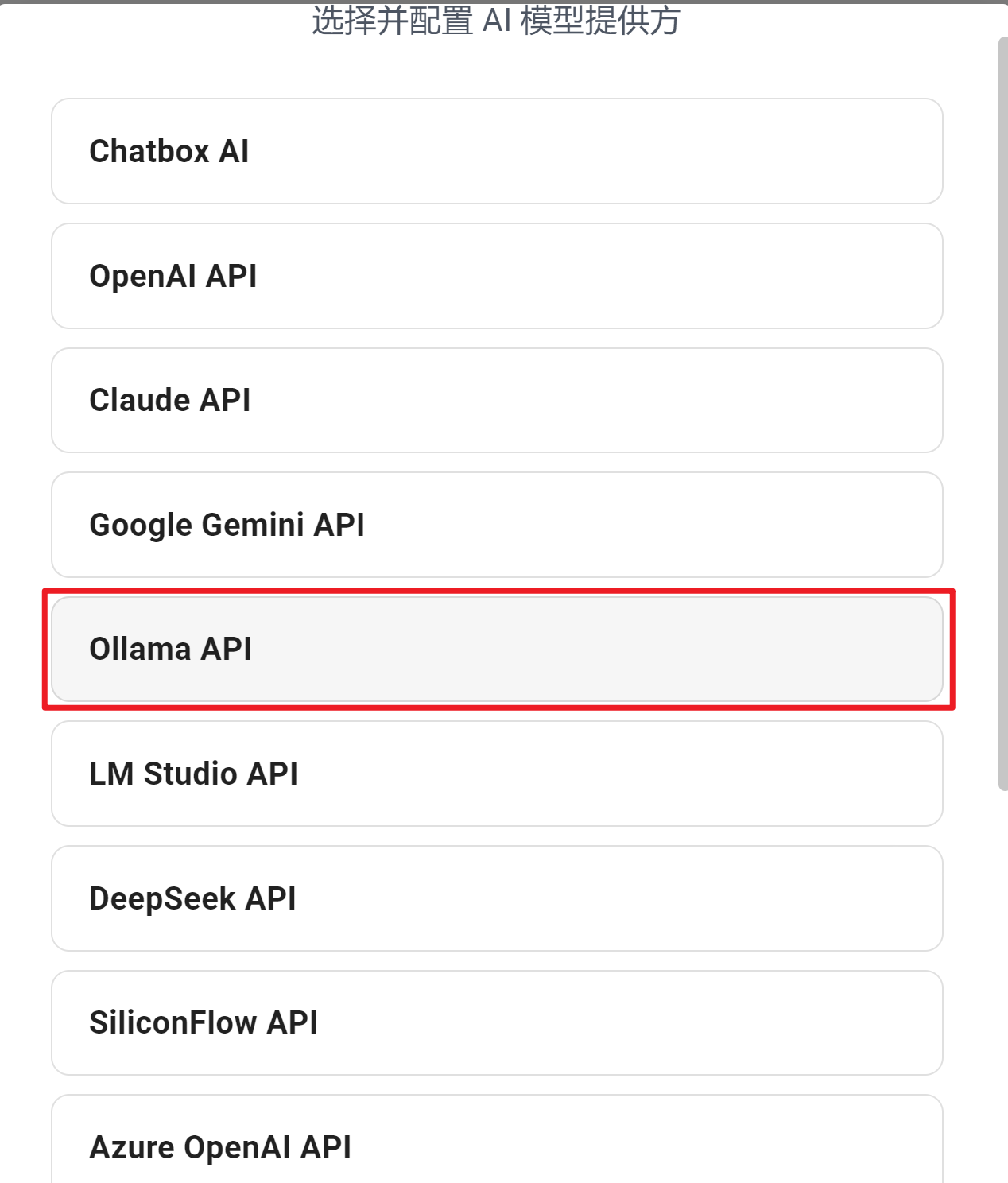
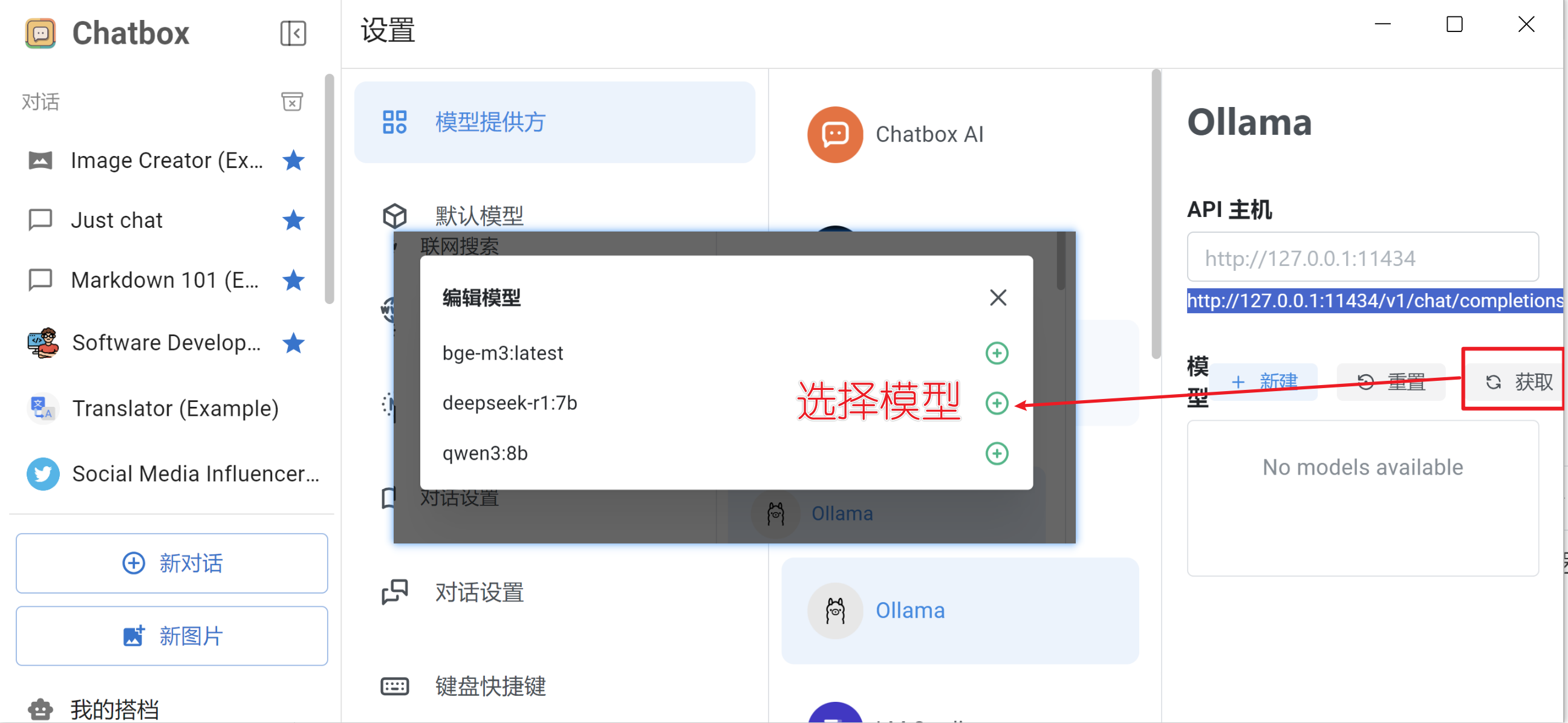
在模型列表中,选择已经启动的模型(注意 :此时需要先使用ollama运行模型)。
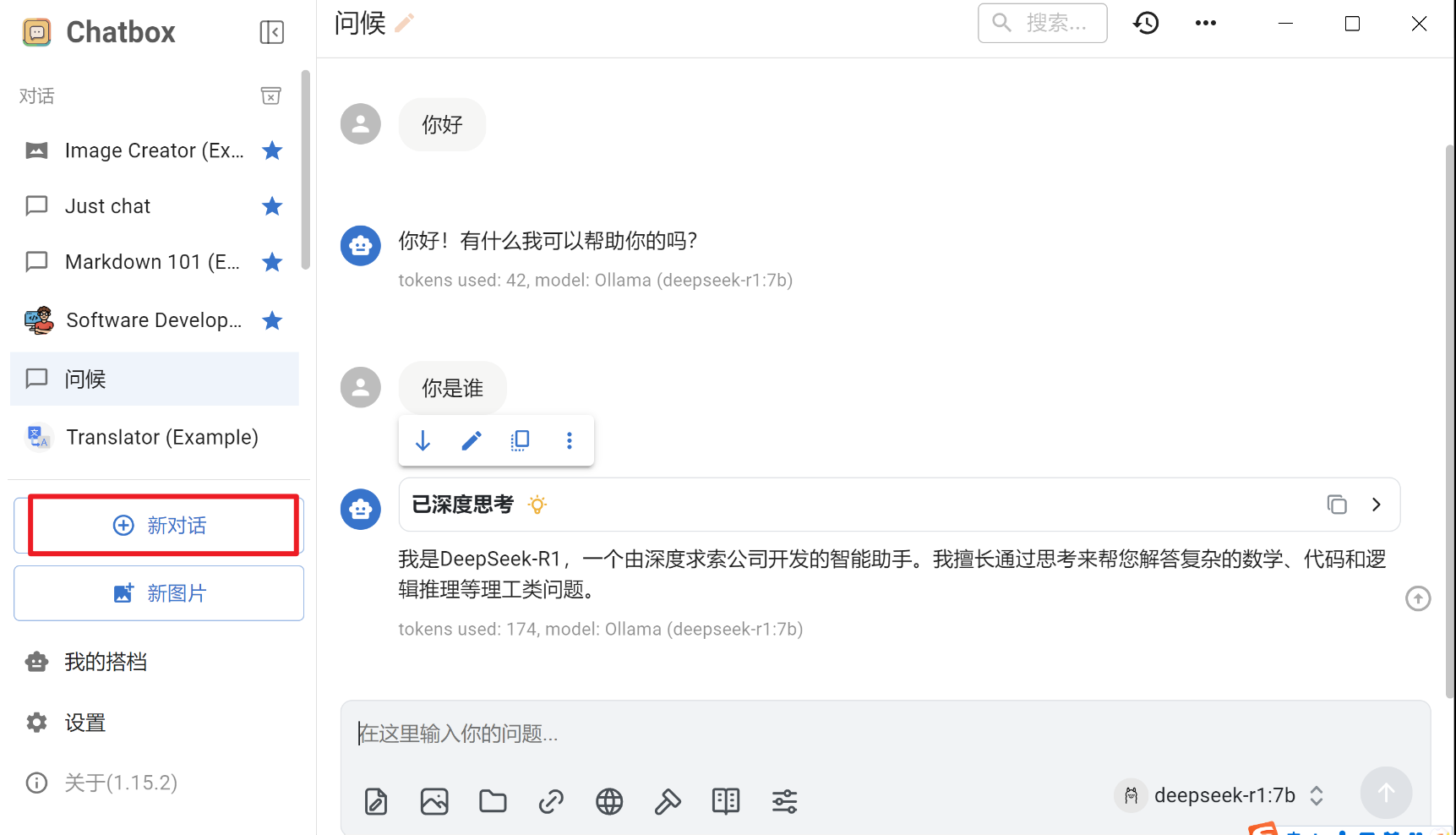
接下来就可以使用了,测试一下中文效果,测试一下英文效果
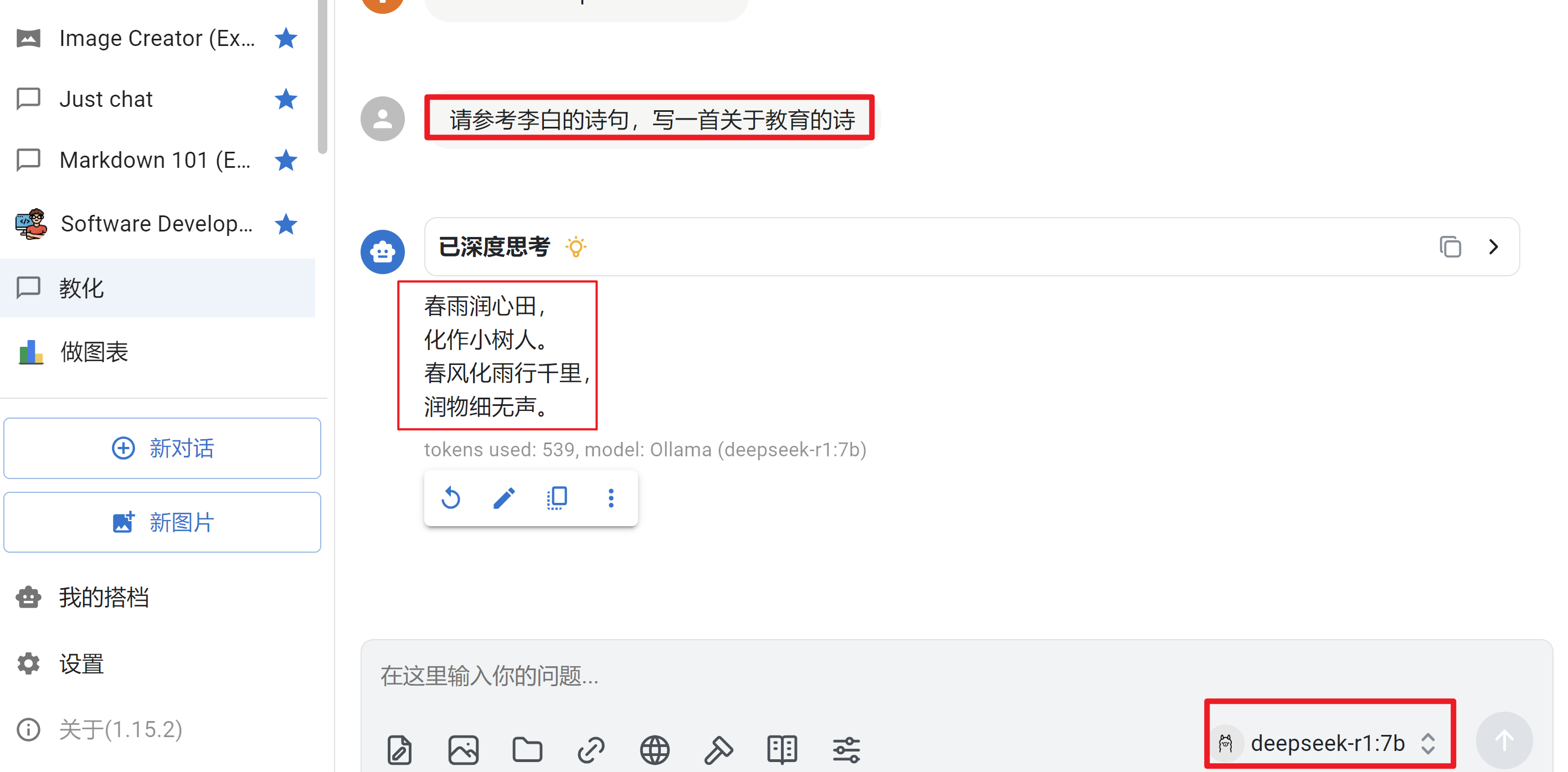
至此,可以使用Chatbox来与AI聊天了。但是交流的都是通用知识,如果需要读取私有文件的中内容,来回答问题的话,显然不足。
1.4 RAG知识讲解
前言
1 什么是RAG?
RAG(Retrieval-Augmented Generation)检索增强生成是一种将信息检索与大语言模型(LLM)结合的框架。简单来说:
RAG(中文为检索增强生成) = 检索技术 + LLM 提示。
核心工作流程:
- 检索阶段:从知识库中找到与用户查询最相关的知识片段
- 生成阶段:将检索到的知识与用户问题一起输入LLM,生成最终答案
完整的RAG应用流程主要包含两个阶段:
- 数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库
- 应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
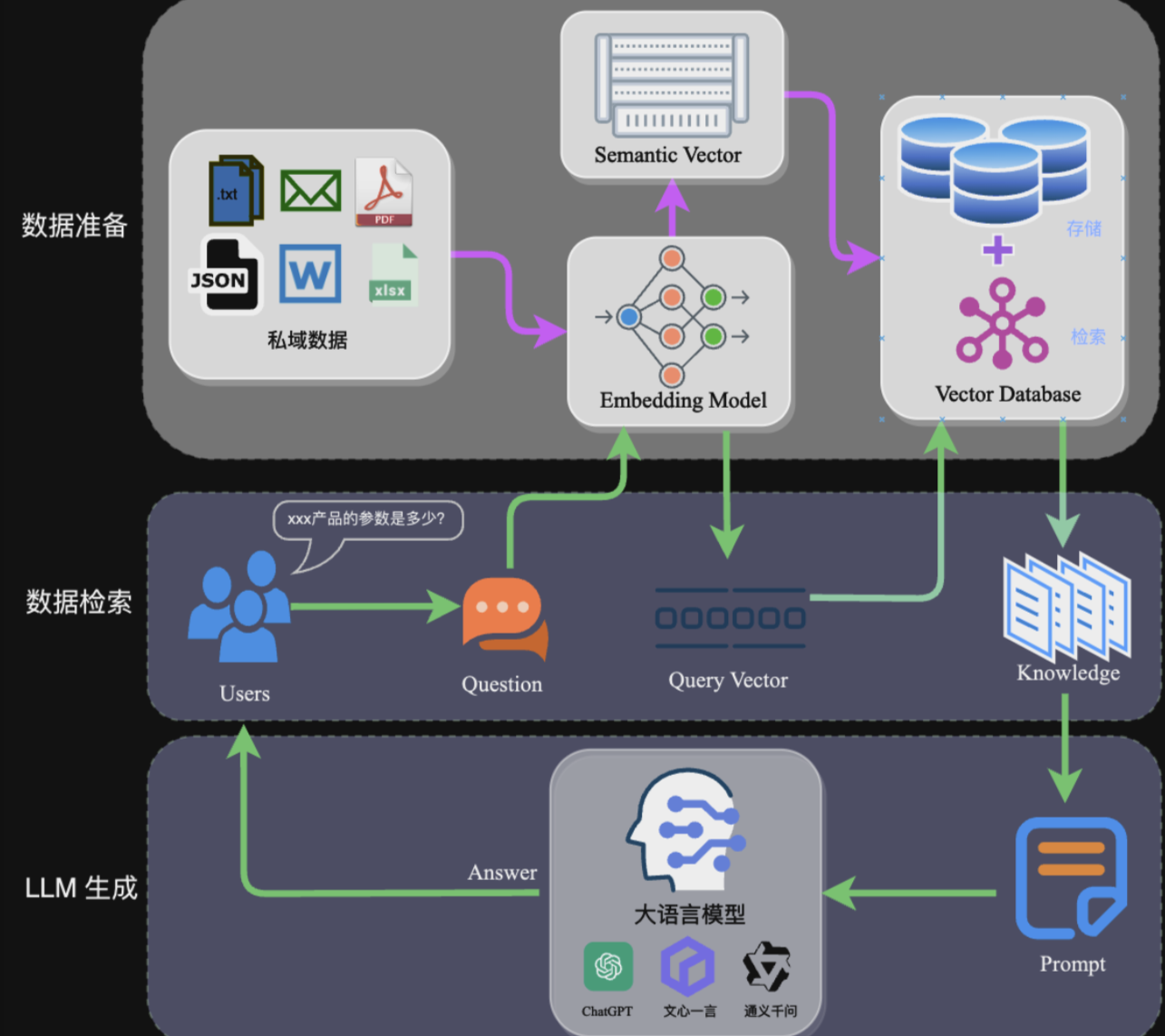
embedding Model:负责将文本向量化. vector DB:负责存储和检索多维向量
image
2 为什么需要 RAG?
LLM 的痛点:
- 知识截止时间早,无法获取最新信息
- 企业私有数据无法访问
- 容易产生"幻觉"(胡说八道)
- 数据安全和隐私问题
3 什么是BGE-M3
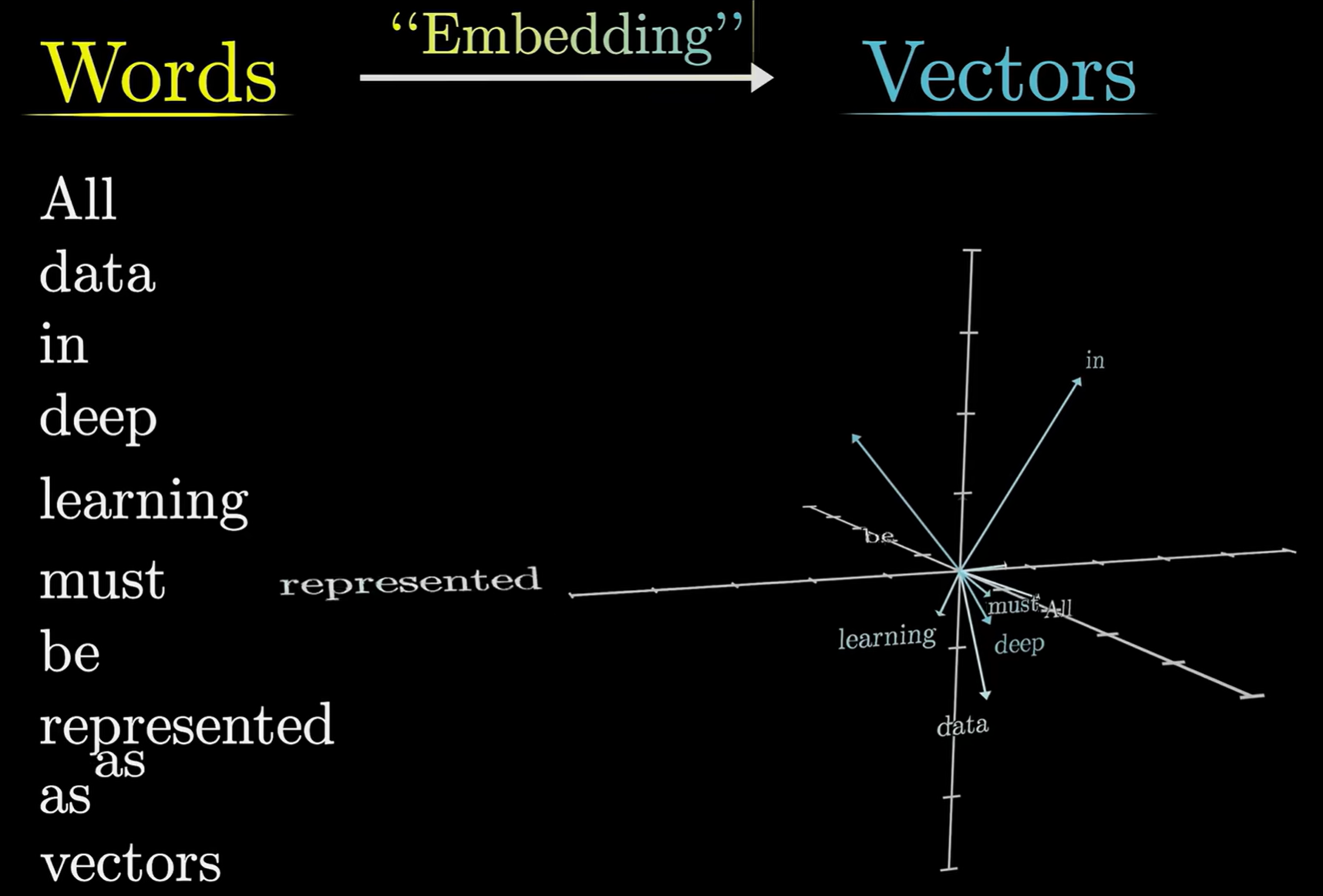
BGE-M3(BAAI General Embedding M3) 是一个强大的多功能嵌入模型,同时支持密集检索、多向量检索和稀疏检索,非常强大,它适用于多种使用场景,比如检索增强生成、知识检索问答、文本检索、分类和聚类。
- 每个模型都有文本限制,如果不分块,根本无法将完整文档信息提供给 LLM!
- 在向量数据库中,任何内容都需要先进行 Embedding,
- 分块的主要目的是:
- 减少噪音:避免将不相关信息一起向量化,
- 提高匹配精度:小块更容易找到精确匹配
- 优化存储:向量数据库处理小块更高效
4 什么叫知识库
知识库 更加偏向于能够直接读取文档并处理大量信息资源,包括文档上传、自动抓取在线文档,然后进行文本的自动分割、向量化处理,以及实现本地检索增强生成(RAG)等功能的工具.
像是企业的"大脑",个人的"书架",AI的"知识库"——它让分散的知识变得有序、有用、有价值!
综合来说,要提高模型的准确性和私密性,可以利用RAG技术来实现,可以使用bge-m3来进行构建知识库。
1.5 创建本地知识库
创建本地知识库
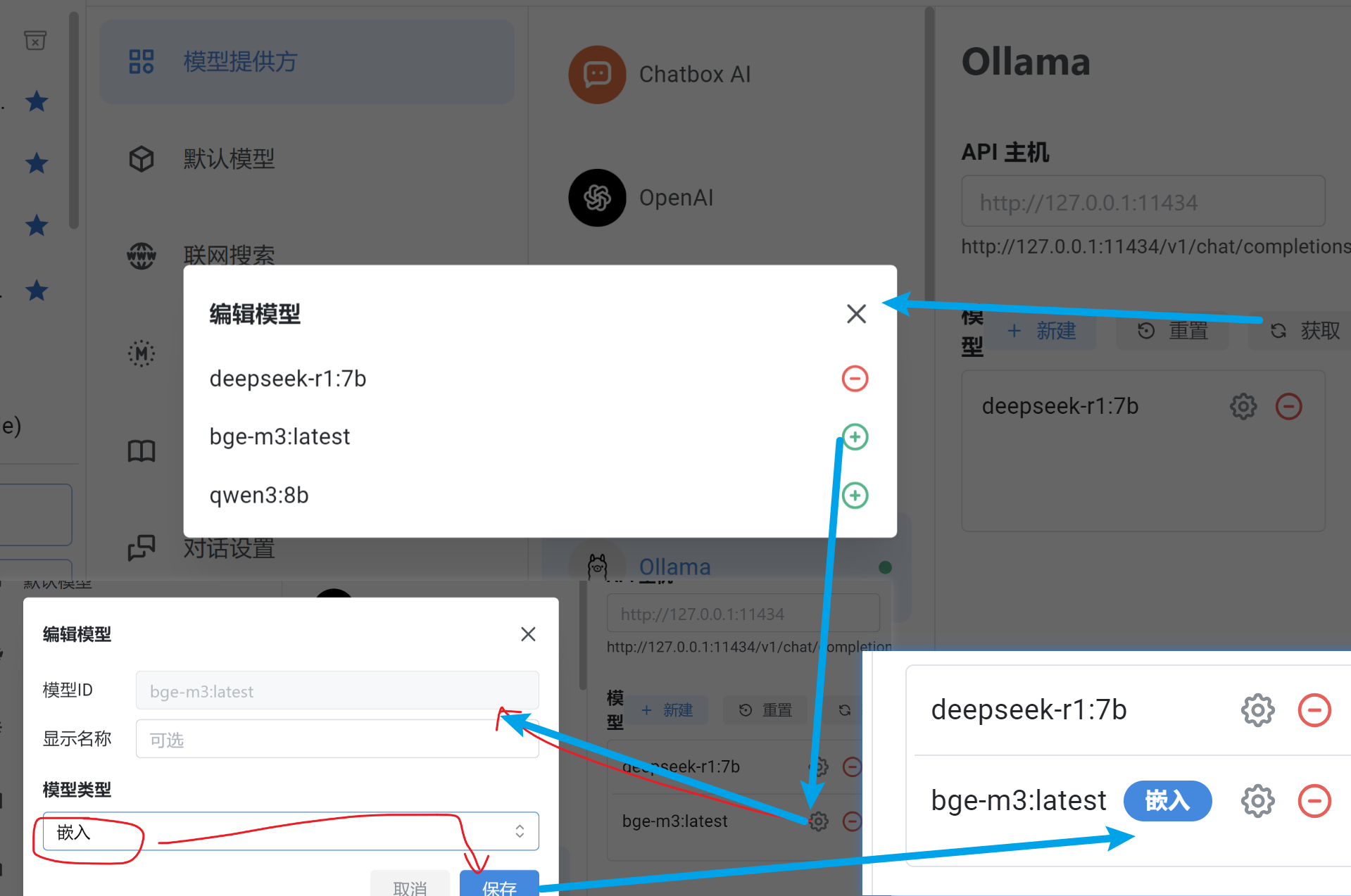
0. 在ChatBox AI 中设置页面中添加嵌入模型
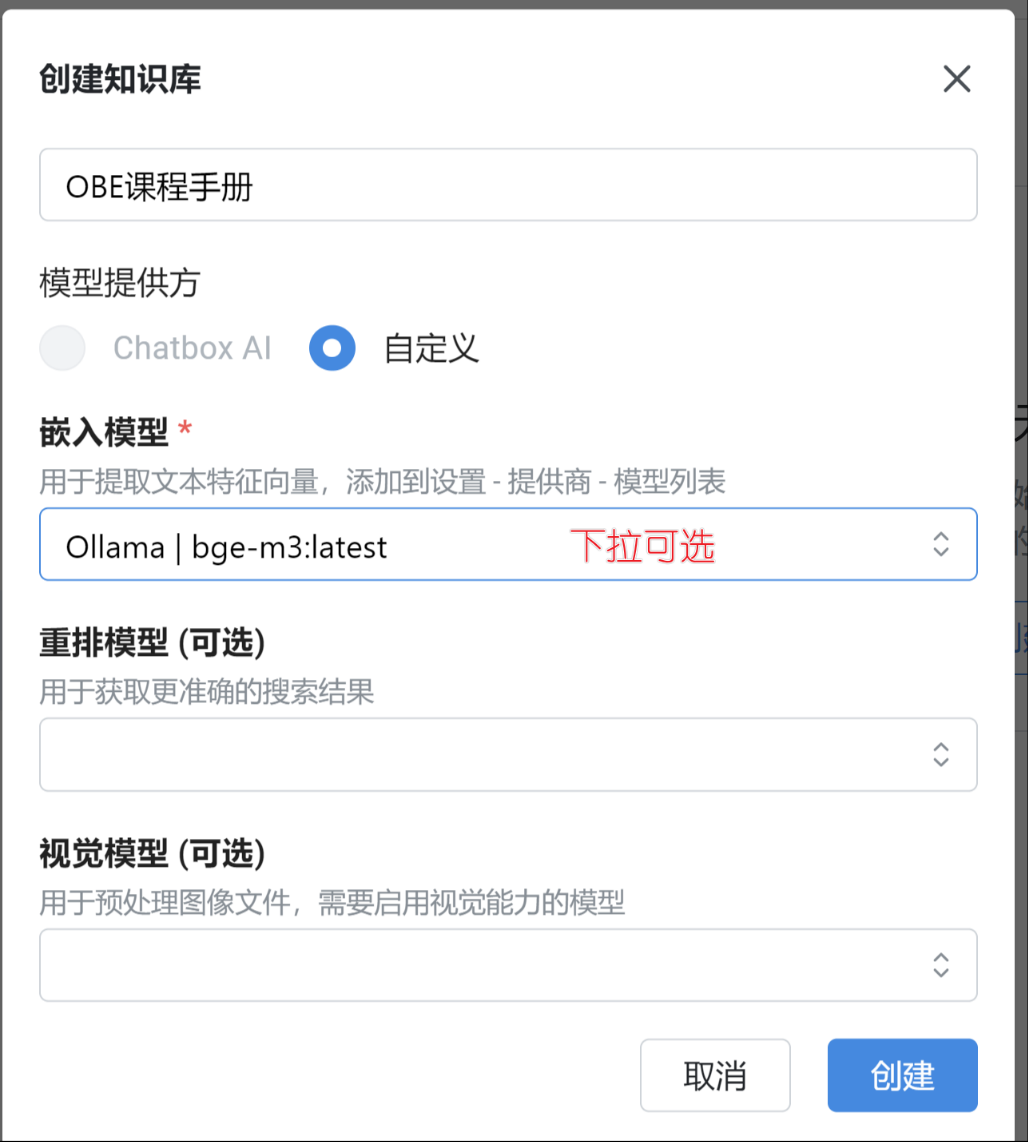
1. 创建知识库
进入设置 - 知识库 页面,点击创建知识库,输入知识库名称,并选择知识库所需要的模型
对于 Chatbox AI 付费用户,可以选择 Chatbox AI 作为知识库的模型提供方,免费用户也可以选择自己的API。
嵌入模型:用来将文档转换为向量
重排模型:可选 ,配置后可以获得更准确的搜索结果,对回答质量有一定帮助
视觉模型:可选 ,配置之后,可以往知识库里添加图片,图片中的文字会被提出来入库
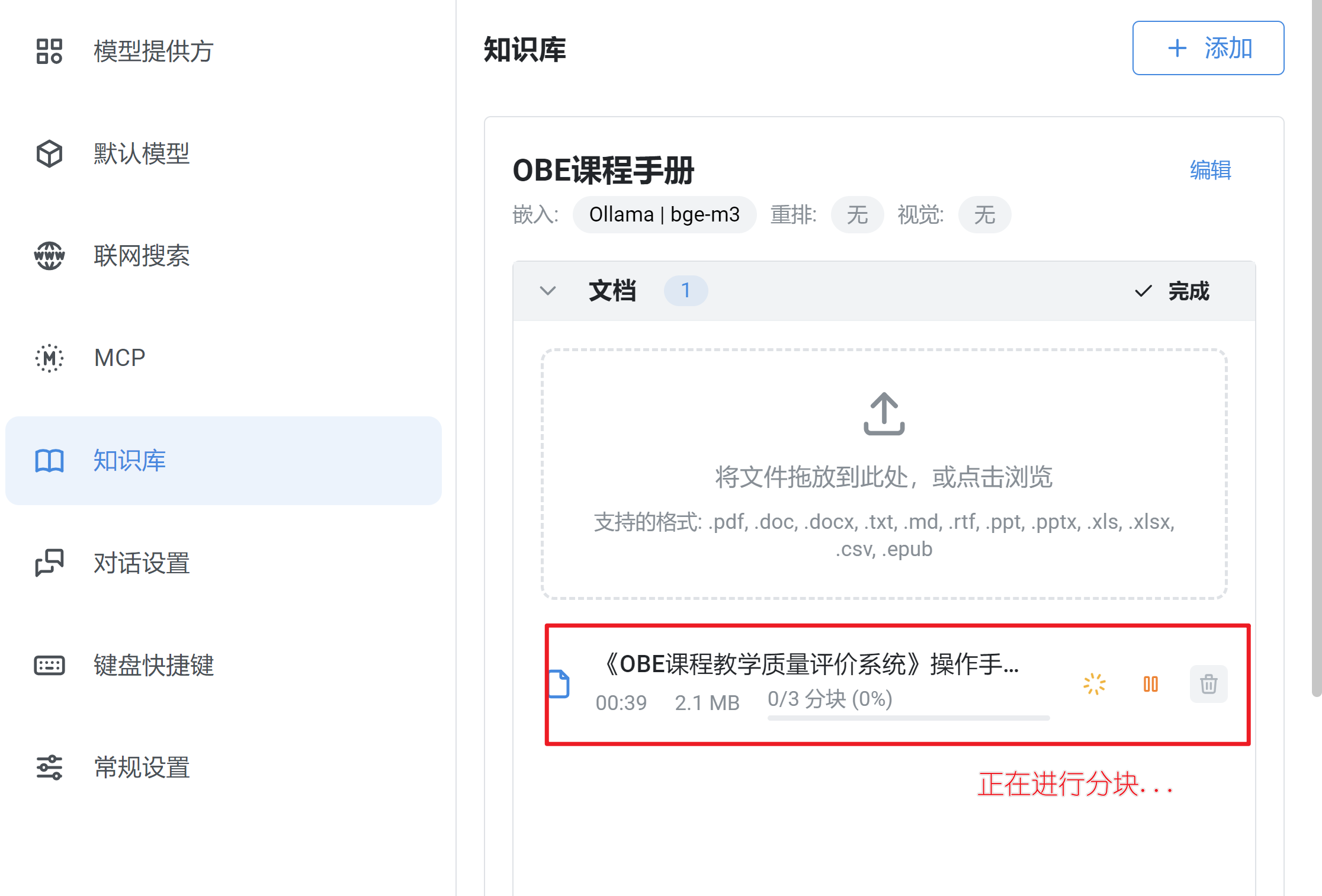
2. 往知识库添加文档
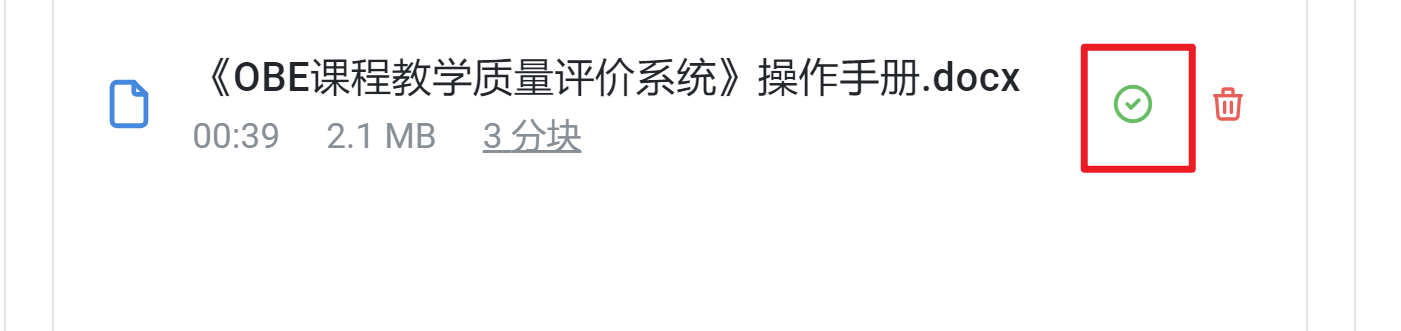
拖入或点击浏览文件,等待文件处理完成。’
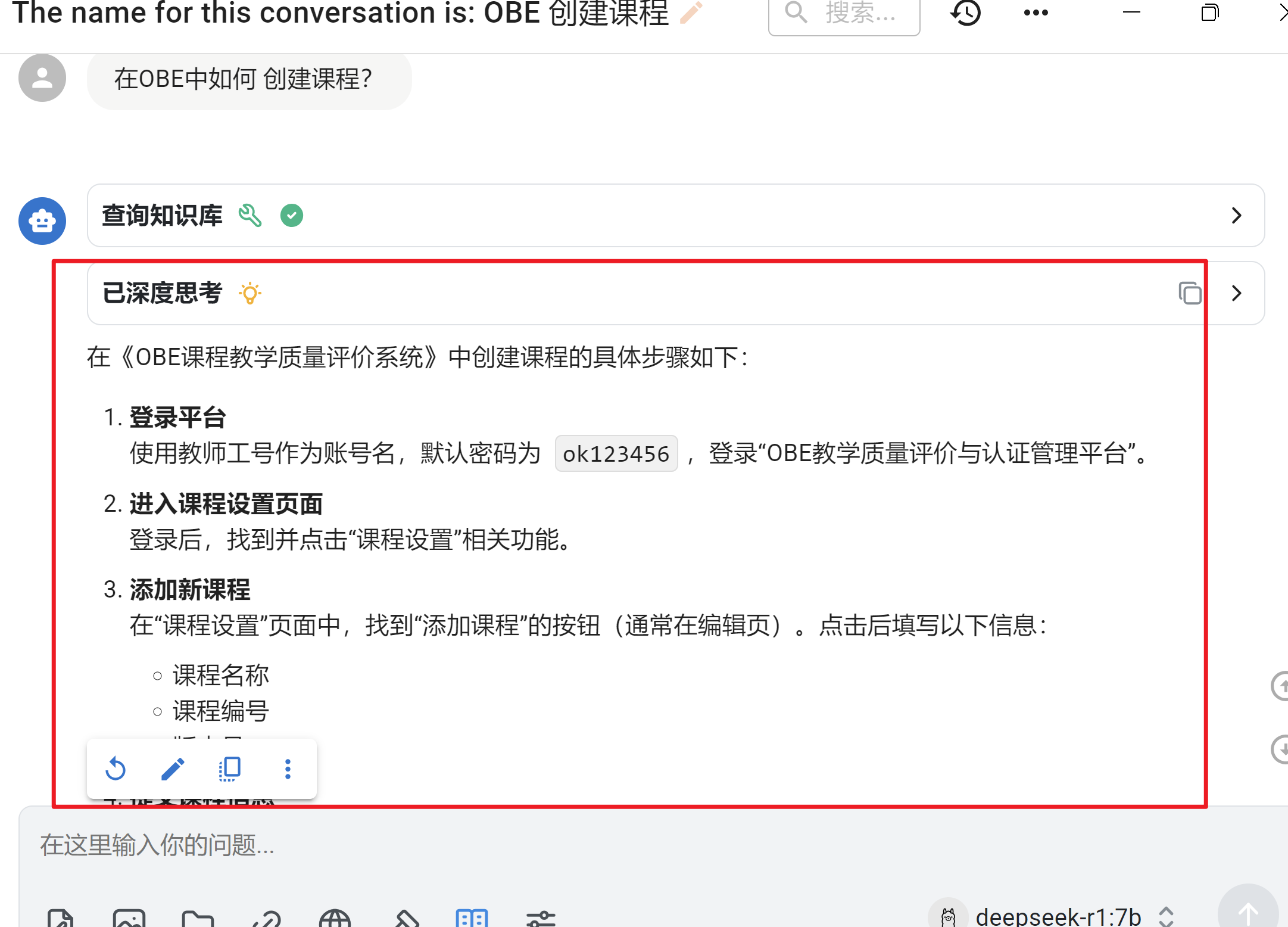
3. 对知识库进行问答
创建新对话,在输入框里的工具栏选择刚刚创建的知识库
然后就可以随意问答了
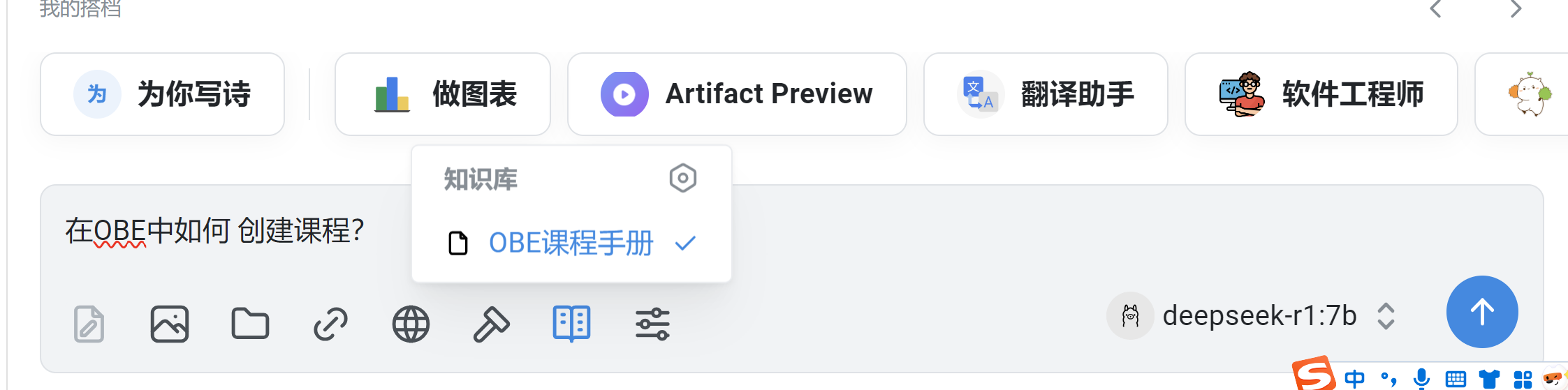
可以发现,回答的结果是根据资料返回的,不是不变乱造!!
总结
课堂作业
- 你可以根据上述教程,一起来构建属于你的特有的知识库吧!!🎤
2. 知识库
2.1 Obsidian介绍和安装
Obsidian介绍和安装
Obsidian,一款知识管理工具。
想象一下,所有你的思维、笔记和灵感都能在一个地方相互连接,形成一个井然有序的知识网络。
1. 访问官方网站
首先,打开你的浏览器并访问https://obsidian.md/。
2. 点击“下载”按钮

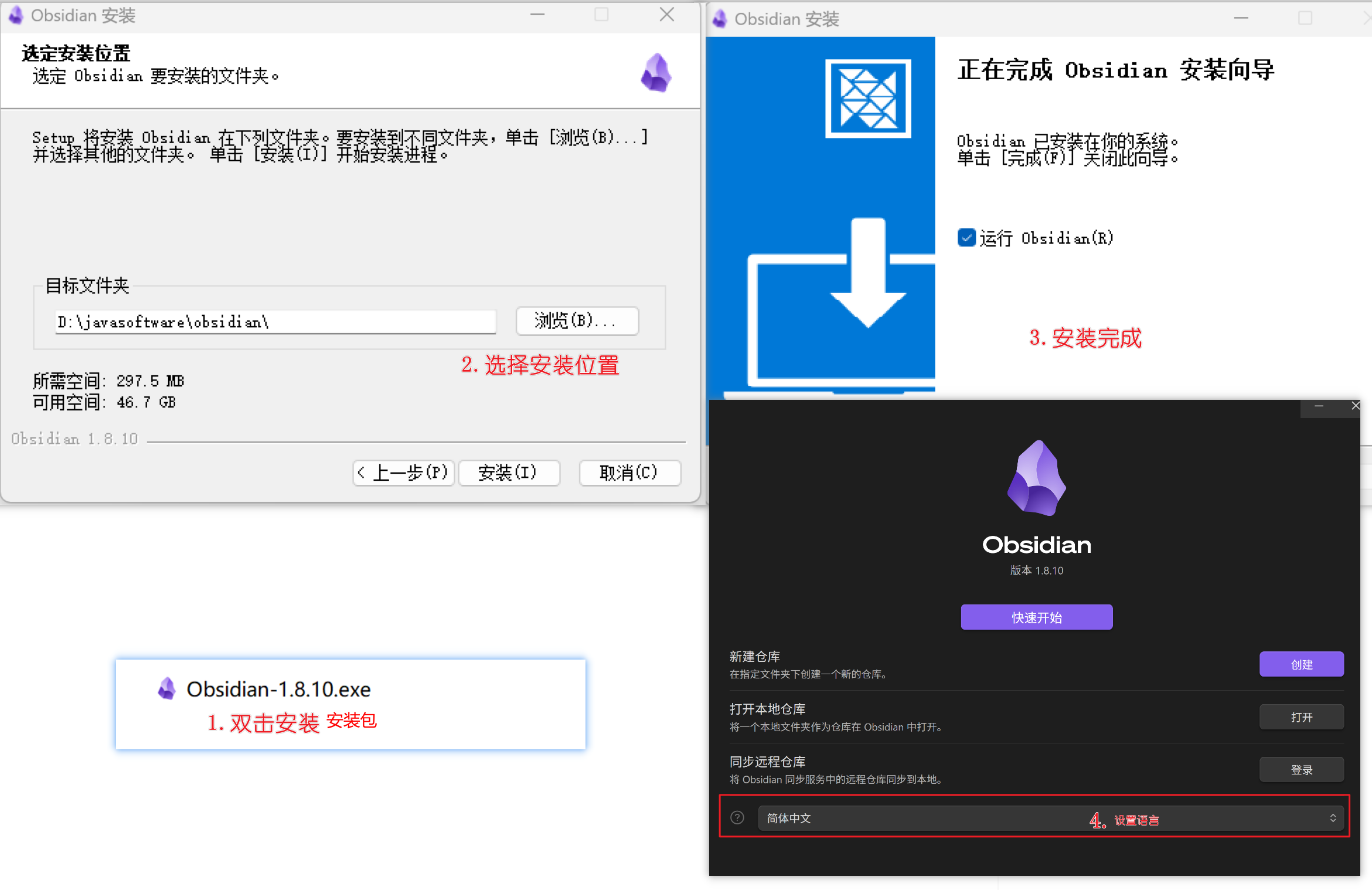
3. 点击对应系统版本进行下载,然后下一步下一步安装完成即可

4. 启动,安装完成后的启动界面,你只需要在obsidian中创建一个文档就可以了
至此,你已经成功地安装obsidian了。看似和普通软件差不多呀,有什么用呢? ❓
2.2 Obsidian常规使用
前言

Obsidian 是一款基于 Markdown 的知识管理工具,让你:
- 🔍 自由链接笔记,建立知识网络
- 📝 原生 Markdown 编辑,轻量高效
- 🎨 完全自定义,插件生态丰富
- 📁 本地存储,隐私安全
🎯 核心概念对比
| 概念 | 说明 | 例子 |
|---|---|---|
| 笔记 | Markdown文件 | 项目A.md |
| 链接 | 自动创建的双向链接 | [[项目A]] |
| 图谱 | 可视化的知识关系图 | 点击左侧面板的"图谱" |
🔗 链接演示
创建链接的几种方式:
- 手动输入:
[[项目A]] - 快捷键:选中文本后
Ctrl+K(Windows) /Cmd+K(Mac) - 右键菜单:选择"创建反向链接"
🎨 格式说明
- 使用 粗体 标题突出重点
- 表格使用
|分隔,首行定义表头 - 代码块使用 ```markdown 包裹
- 添加了装饰性的emoji和分隔线
准备笔记素材:👇
急救知识笔记素材
急救学基础知识.md
# 🏥 急救学基础知识
** #急救学 #医学基础 #学习笔记**
### 急救学核心概念
急救学是研究**突发伤病的紧急处理方法**的医学分支,主要目标是在**黄金救援时间**内稳定患者生命体征,为后续治疗创造条件。[[急救技能学习方法]] [[急救实践训练]]
### 基础知识框架
#### 1. 急救原则
- **生命优先**:确保患者生命安全
- **评估现场**:确保救援环境安全
- **快速识别**:判断伤情严重程度
- **及时求助**:呼叫专业医疗救援
#### 2. 常见急症分类
| 紧急程度 | 症状表现 | 处理原则 |
|----------|----------|----------|
| **危急** | 心跳呼吸停止、大出血、窒息 | 立即CPR、止血、通畅气道 |
| **紧急** | 意识不清、严重外伤、中毒 | 保持生命体征、防止恶化 |
| **次紧急** | 轻度外伤、扭伤、轻微中毒 | 清创消毒、固定包扎 |
#### 3. 基础生命支持
- **CPR操作**:胸外按压、人工呼吸
- **AED使用**:自动体外除颤器操作
- **气道管理**:清除异物、保持通畅
### 学习建议
- 熟记急救电话和求助流程
- 了解常见急症的识别要点
- 掌握基础生命支持技能 [[急救技能学习方法]]
急救实践训练.md
# 🏃♂️ 急救实践训练
** #急救学 #实践训练 #技能应用**
### 实践训练方案
#### 校内训练
- **实验室练习**:在医学模拟实验室练习
- **技能竞赛**:参加急救技能比赛
- **小组演练**:同学间互相练习 [[急救技能学习方法]]
#### 实地训练
- **医院实习**:急诊科跟班学习
- **社区服务**:参与社区急救培训
- **野外训练**:户外急救场景演练
#### 情景模拟训练
- **家庭急救**:模拟家庭突发伤病
- **公共场所**:模拟商场、车站等场所
- **交通事故**:模拟车祸现场急救
### 训练重点
#### 个人技能训练
- **反应速度**:快速判断和反应
- **操作精度**:准确执行急救动作
- **心理素质**:保持冷静和专注
#### 团队协作训练
- **角色分工**:明确各自职责
- **沟通协调**:有效信息传递
- **应急配合**:快速响应和配合
### 训练评估
- **技能考核**:定期技能测试
- **案例分析**:分析训练中的问题
- **持续改进**:根据反馈优化训练 [[急救考试准备]]
急救应用场景.md
# 🏥 急救应用场景
** #急救学 #应用场景 #实战演练**
### 常见急救场景
#### 1. 家庭急救
- **常见情况**:跌倒骨折、烫伤烧伤、中毒窒息
- **处理要点**:现场评估、简单处理、及时送医
- **设备准备**:家庭急救箱、常用药品 [[急救技能学习方法]]
#### 2. 公共场所
- **常见情况**:心脏骤停、外伤出血、中暑晕厥
- **处理要点**:确保安全、呼叫救援、现场急救
- **注意事项**:保护现场、避免二次伤害
#### 3. 交通事故
- **常见情况**:脊椎损伤、大出血、复合伤
- **处理要点**:避免移动、止血包扎、固定保护
- **特殊要求**:专业设备、多人配合
#### 4. 运动伤害
- **常见情况**:扭伤挫伤、骨折脱位、肌肉拉伤
- **处理要点**:RICE原则(休息、冰敷、加压、抬高)
- **预防措施**:热身运动、防护装备、适度运动
### 场景应对策略
#### 评估现场安全
- **环境评估**:确保救援环境安全
- **风险识别**:识别潜在危险因素
- **安全措施**:采取必要的安全防护
#### 快速判断伤情
- **意识判断**:检查患者意识状态
- **呼吸检查**:观察呼吸情况
- **循环评估**:检查脉搏和出血情况
#### 制定急救方案
- **优先处理**:先处理危及生命的伤情
- **分级救治**:按伤情严重程度处理
- **持续监测**:观察患者生命体征变化
### 应急准备
- **急救知识**:掌握基本急救知识
- **急救技能**:熟练操作急救技能
- **急救设备**:准备必要的急救设备和药品 [[急救考试准备]]
急救考试准备.md
# 📚 急救考试准备
** #急救学 #考试准备 #认证考核**
### 考试类型与要求
#### 基础知识考试
- **考试形式**:选择题、判断题、简答题
- **考核内容**:急救理论、法律法规、操作规范
- **分值比例**:理论占60%,实践占40% [[急救学基础知识]]
#### 技能操作考试
- **考试形式**:现场操作、情景模拟
- **考核项目**:CPR、止血包扎、骨折固定
- **评分标准**:动作规范、时间控制、效果评估
#### 综合能力考核
- **考试形式**:综合案例分析
- **考核内容**:现场评估、方案制定、团队协作
- **评分重点**:综合运用能力 [[急救实践训练]]
### 备考策略
#### 理论复习
- **重点掌握**:急救原则、操作流程、注意事项
- **记忆技巧**:制作记忆卡片、思维导图
- **模拟测试**:定期自测、查漏补缺
#### 技能练习
- **反复练习**:熟练掌握基本技能
- **时间控制**:提高操作速度和准确性
- **错误纠正**:及时发现和改正错误动作
#### 心理准备
- **信心建立**:相信自己的能力
- **压力管理**:学会调节考试焦虑
- **模拟考试**:提前适应考试环境
### 考试资源
- **官方教材**:急救学教材和手册
- **练习题库**:历年考试题库
- **模拟软件**:急救技能模拟软件 [[急救应用场景]]
急救技能学习方法.md
# 🎯 急救技能学习方法
** #急救学 #技能培训 #学习方法**
### 技能学习体系
#### 理论学习阶段
- **教材学习**:系统学习急救理论知识
- **视频学习**:观看标准操作视频
- **案例分析**:分析真实急救案例 [[急救学基础知识]]
#### 模拟训练阶段
- **技能训练**:在模拟人上练习操作
- **情景模拟**:模拟真实急救场景
- **团队协作**:多人配合急救演练
#### 实践应用阶段
- **实习观摩**:医院急诊科实习
- **社区实践**:参与社区急救培训
- **考核认证**:参加急救技能考核 [[急救实践训练]]
### 重点技能训练
#### 1. 心肺复苏
- **按压深度**:5-6厘米
- **按压频率**:100-120次/分钟
- **按压姿势**:双手叠压,肘部伸直
#### 2. 外伤处理
- **止血方法**:加压包扎、止血带
- **包扎技巧**:三角巾包扎、绷带包扎
- **伤口处理**:清洁消毒、防止感染
#### 3. 搬运技术
- **徒手搬运**:扶持法、背人法
- **器械搬运**:担架使用、脊椎固定
### 学习要点
- 注重动作标准和规范
- 强调时效性和准确性
- 培养冷静应对的能力 [[急救实践训练]]
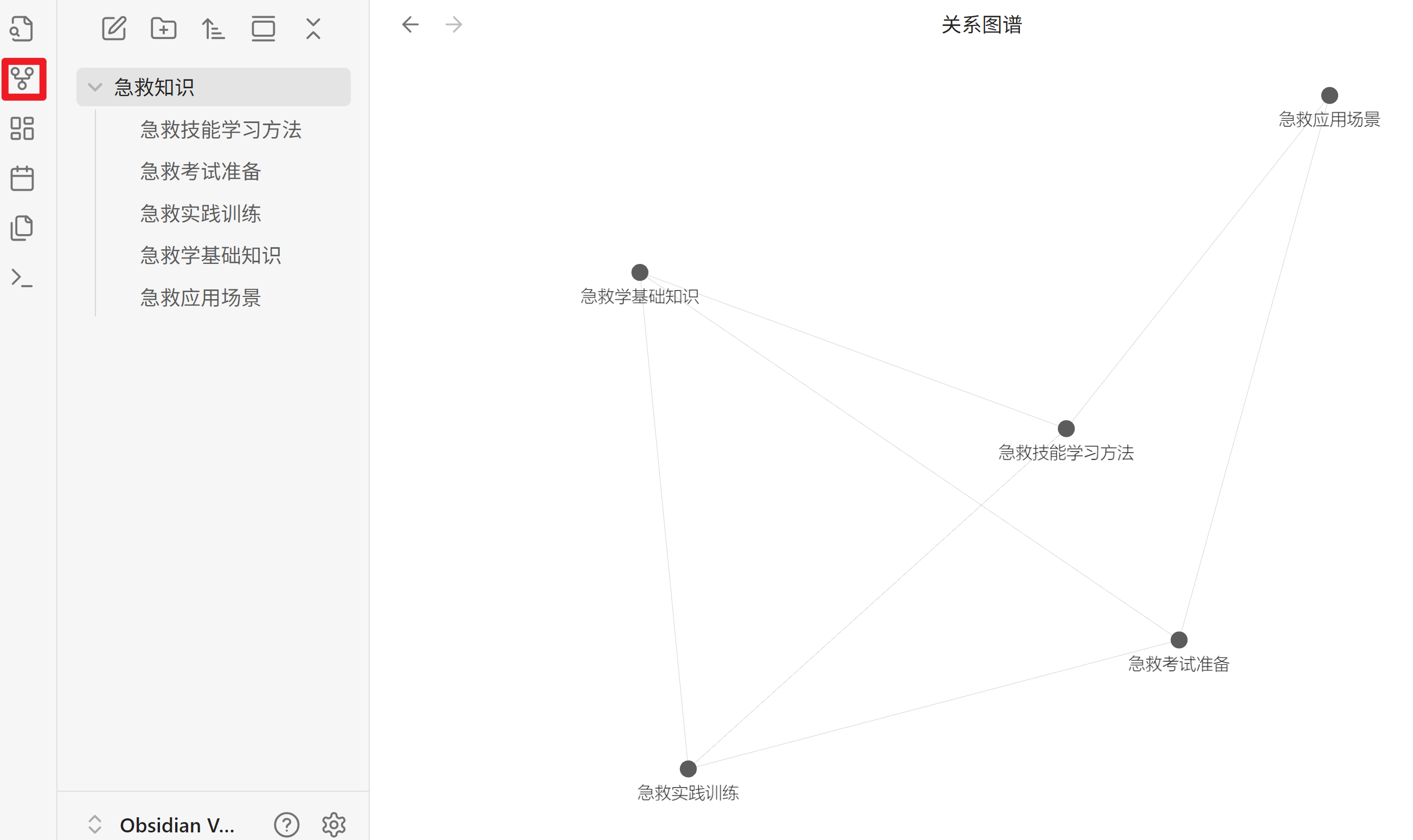
将上述的笔记粘贴到急救知识的文件夹中,点击图谱,观察效果:
2.3 Obsidian集成大模型和RAG功能
Obsidian集成大模型和RAG功能
Obsidian目前只是一个知识管理工具,说白了就是一个笔记本,可以检索,以及互相关联等等,但是如果根据现有的笔记进行创作、写文章和总结报告等等,仍然需要大量的手工工作,但是可以通过大模型和RAG进行自动创作,极大的提高了工作效率!!!
如果只是集成大模型,仅仅回答通用知识,对于你原有的私密笔记和文章并没有直接帮助,RAG则不一样,可以引用、引述你原有的笔记进行创作,可以说是非常高效了!!!
因此接下来:
- 安装Copilot插件,这个插件主要是集成大模型。
- 在Obsidian里集成大模型和嵌入模型
- 在Obsidian里利用Embedding索引,根据你的知识进行创作、搜索等!!!
1. 安装Copilot插件
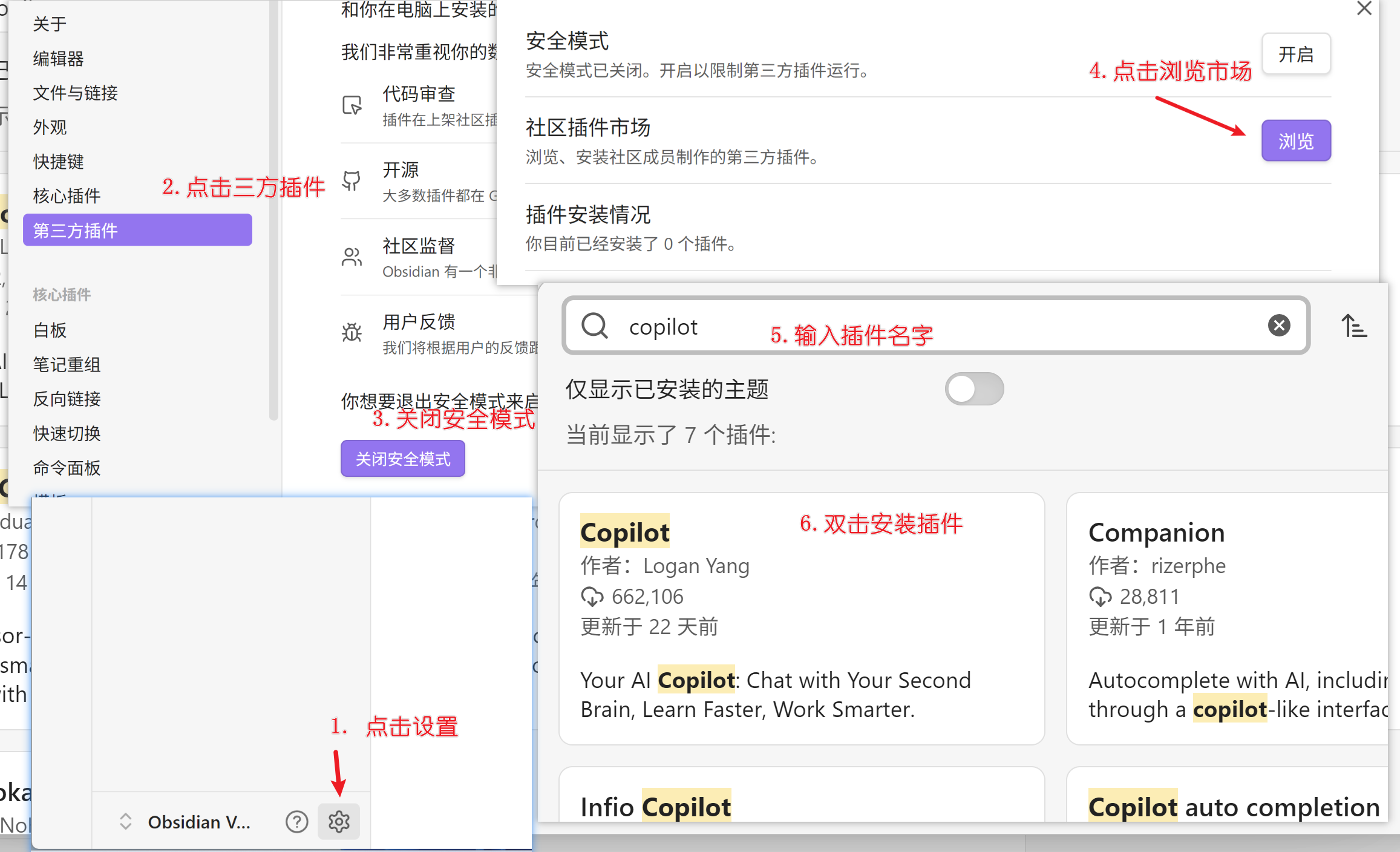
这个插件是要访问github的,但是国内速度较慢,除非使用科学工具,否则无法使用,这里提供清华大学的工具来进行加速 
下载这个工具,直接打开运行即可,地址:https://cloud.tsinghua.edu.cn/d/df482a15afb64dfeaff8/
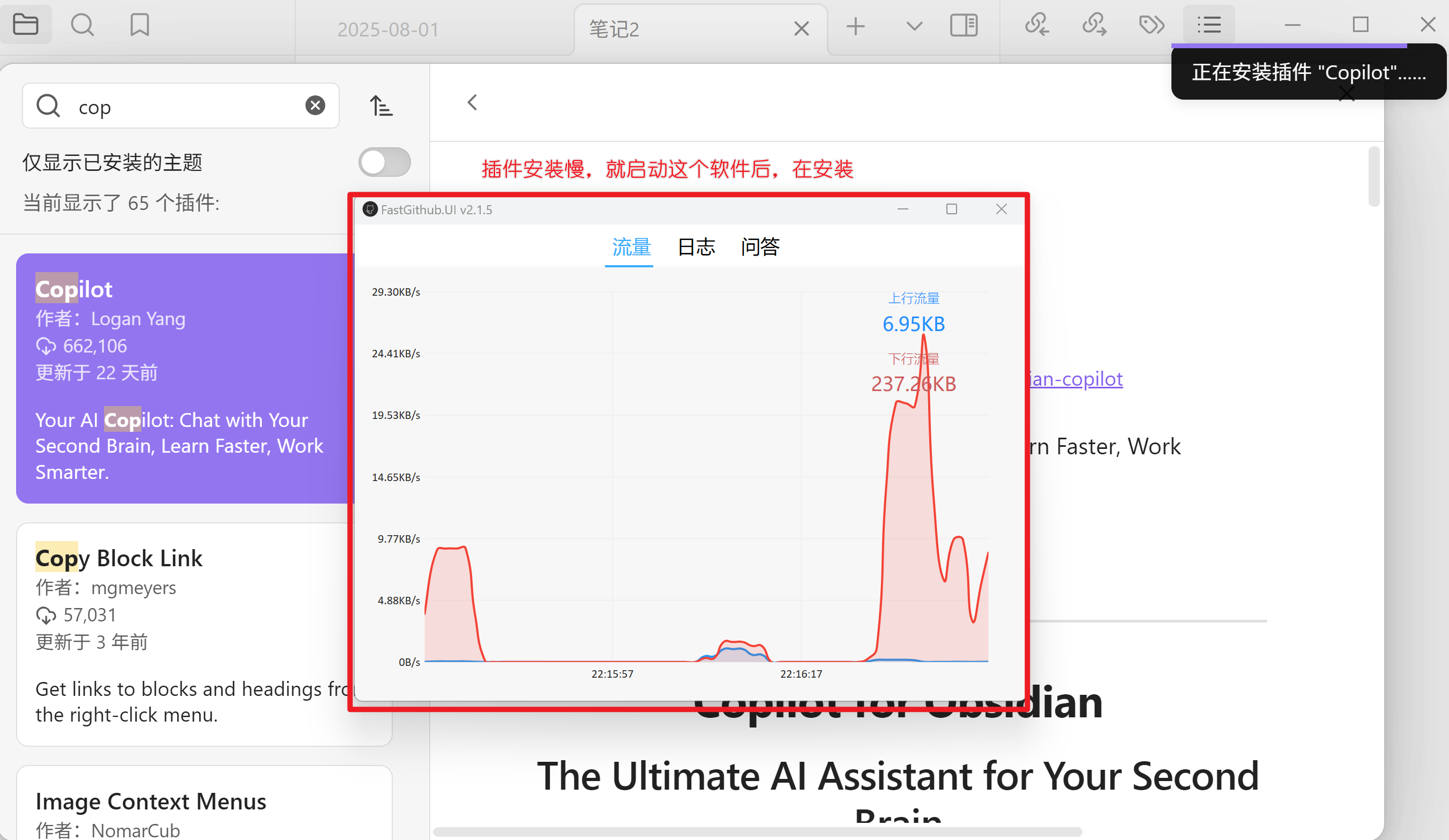
先关闭Obsidian软件,然后启动清华大学提供的这个工具,然后在启动Obsidian,安装Copilot插件,如下图
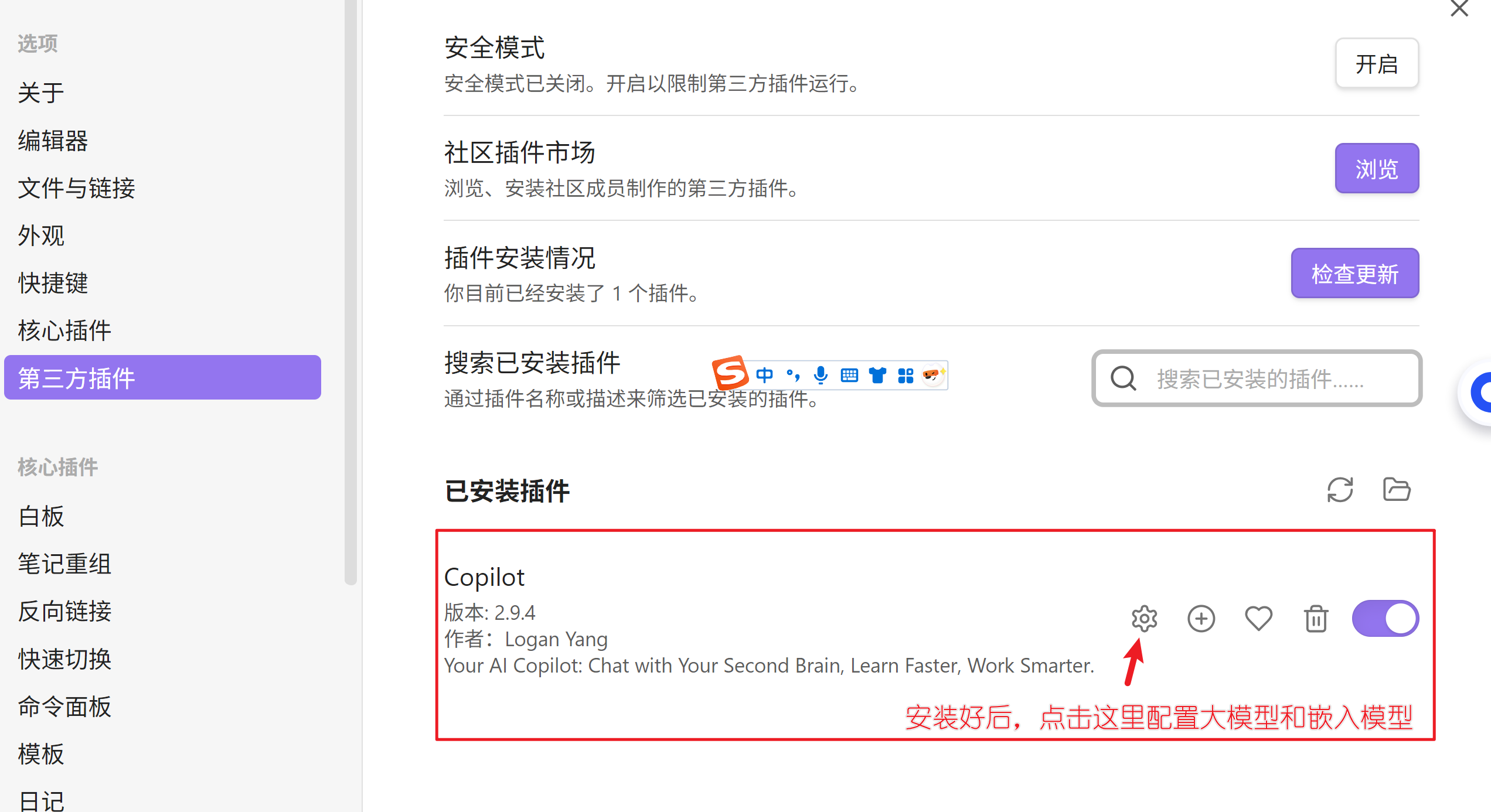
插件完成后,开始配置大模型和嵌入模型(注意Ollama启动模型和安装嵌入模型)
2. 在Copilot上配置大模型和嵌入模型
2.1 配置大模型 先把Models下的模型全部取消勾选,然后添加自定义模型 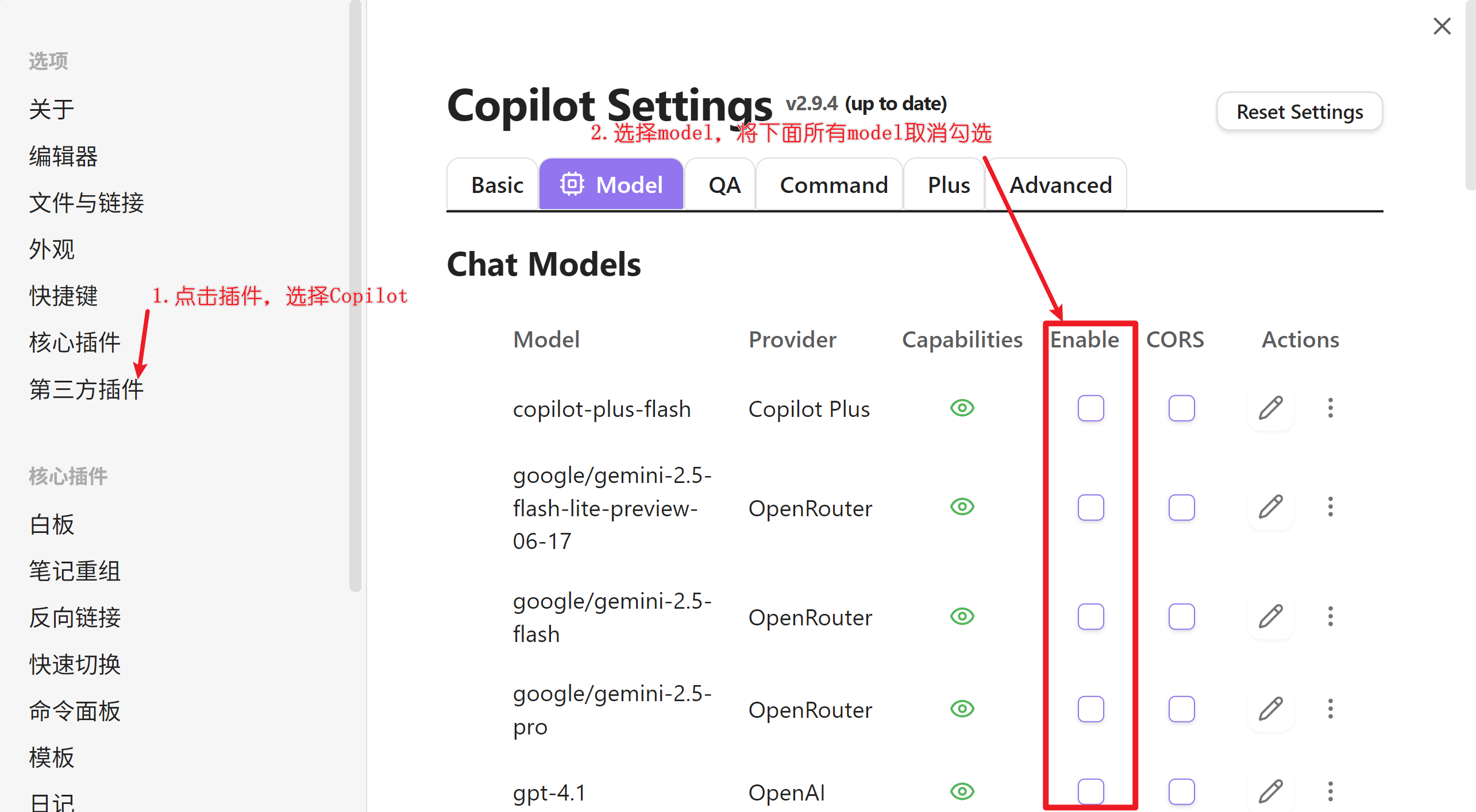
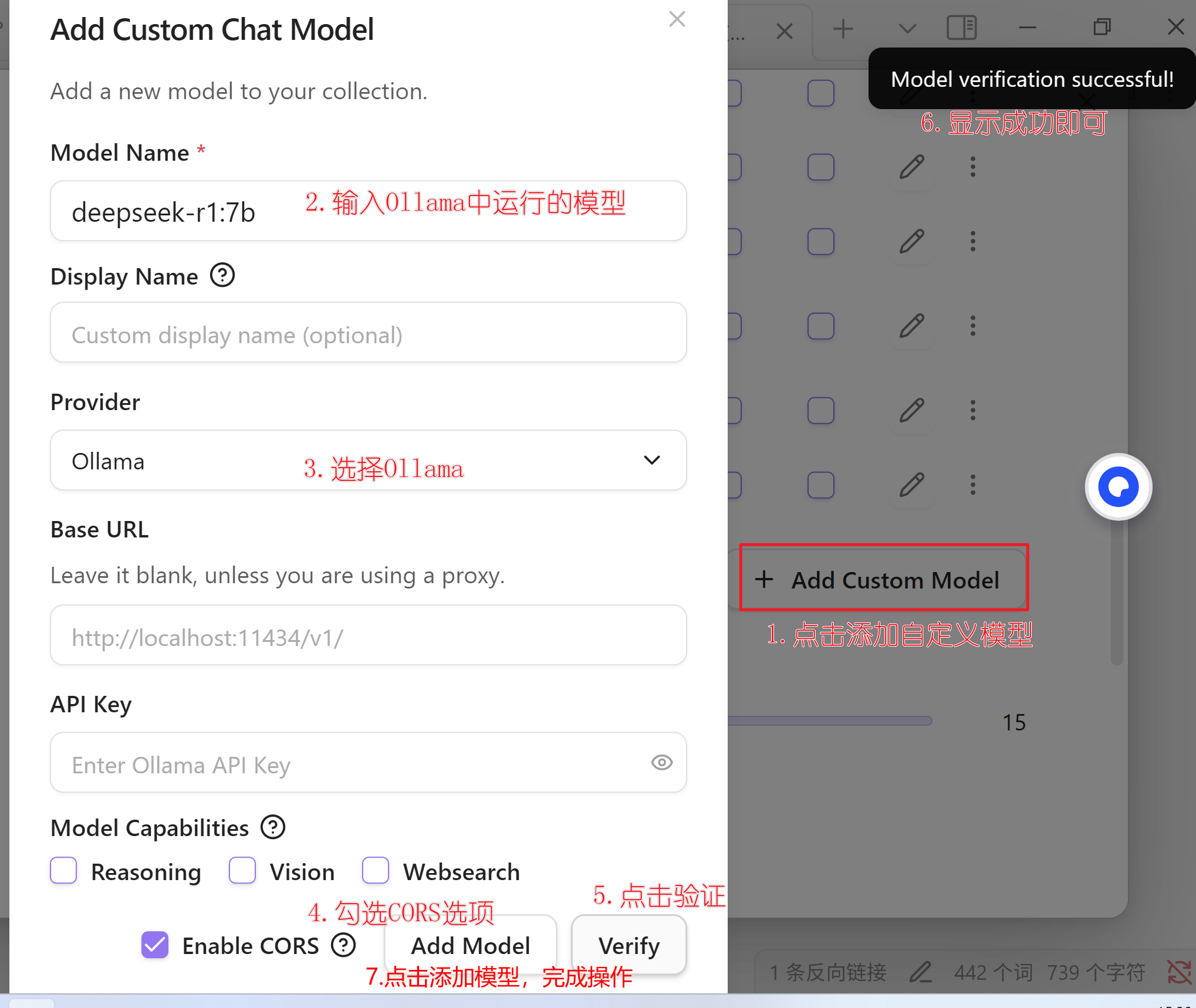
2.2 配置嵌入模型
在Models最下方的 Embedding Models 中,取消其他的模型,点击添加自定义模型,输入bge-m3 ,选择Ollama,点击Verify,成功后,点击保存即可 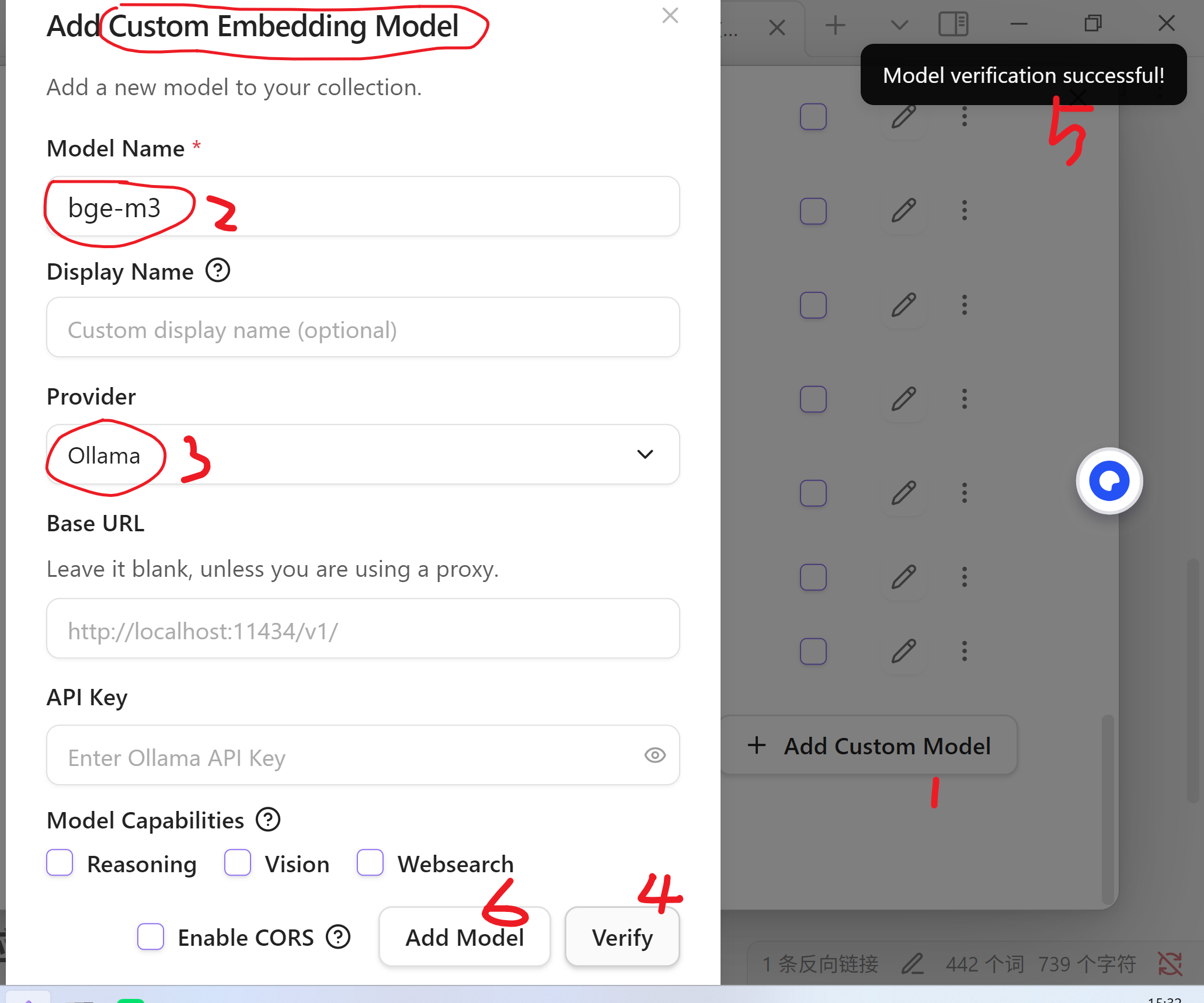
3. 观察对话框,是否可以正常对话
好了,配置好大模型和嵌入模型之后,看看能否正常工作,打开Obsidian,选择左侧的插件按钮,弹出对话栏目
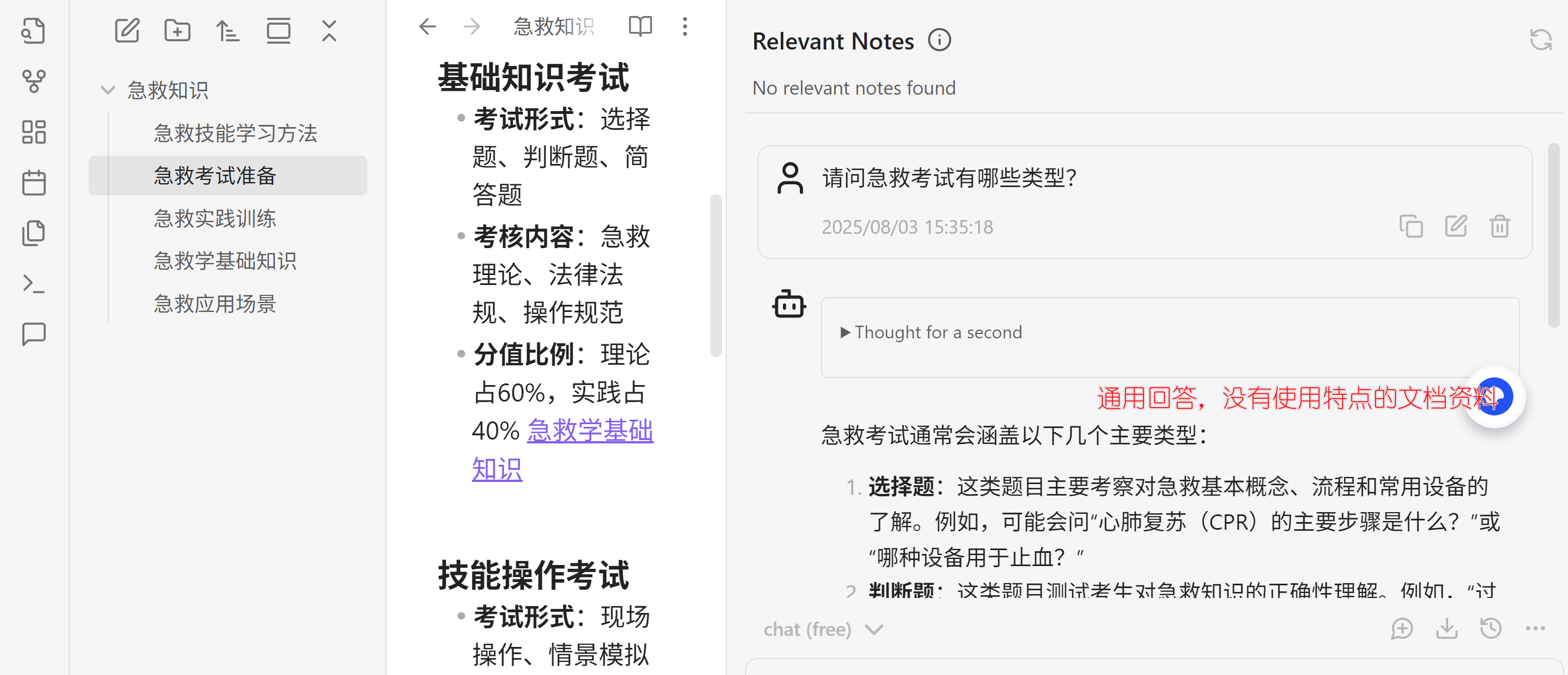
2.4 Obsidian实战操作
前言
上一节中,我们已经完成Obsidian配置大模型和嵌入模型,本节就通过一个简单的例子来验证一下效果,并且生成一些新的笔记!!! 同时,也可以从嵌入模型的结果中抽取一些新的知识点进行添加!!!
开始吧!!!
根据我原有的笔记,分析写作习惯,给我生成私人订制的写作建议!!
根据我{急救知识}所有的笔记,分析并学习我的写作习惯、逻辑思路和视频风格告诉我有那些值得改进的地方,
并为我生成一份私人定制的写作建议
{ } 括号中的是文件夹 [[ ]] 方括号中是笔记
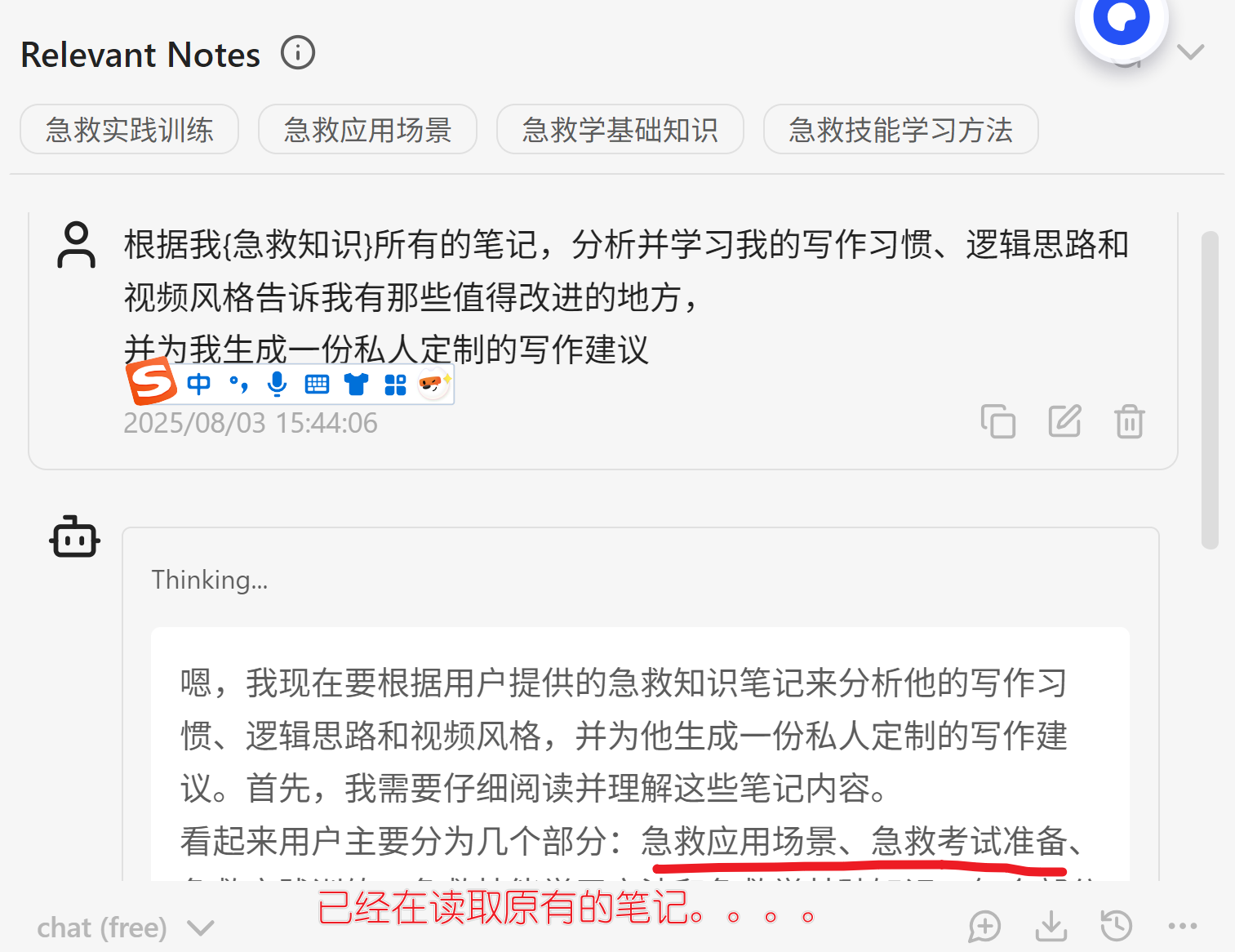
似乎平常使用在线的豆包,deepseek,元宝都有这样的功能,但是在Obsidian加持本地模型,做到了私人订制!!