瑞吉外卖项目优化-Day02
瑞吉外卖项目优化-Day02
目标
- MySQL主从复制 🍐
- 读写分离案例 ✏️
- 项目实现读写分离 ✏️
- Nginx-概述 🍐
- Nginx-命令 ✏️
- Nginx-应用 ✏️
前言
存在的问题
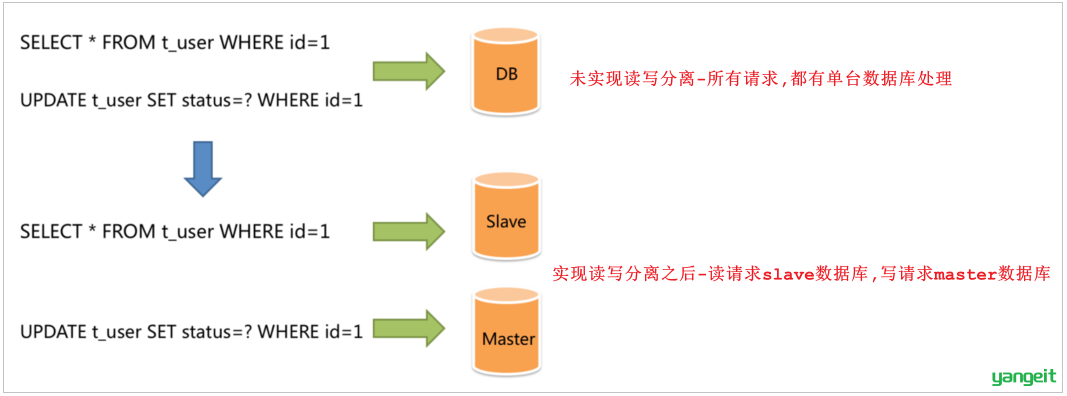
在前面基础功能实现的过程中,我们后台管理系统及移动端的用户,在进行数据访问时,都是直接操作数据库MySQL的。结构如下图:
而在当前,MySQL服务器只有一台,那么就可能会存在如下问题:
1). 读和写所有压力都由一台数据库承担,压力大
2). 数据库服务器磁盘损坏则数据丢失,单点故障
读写分离 解决方案
为了解决上述提到的两个问题,我们可以准备:
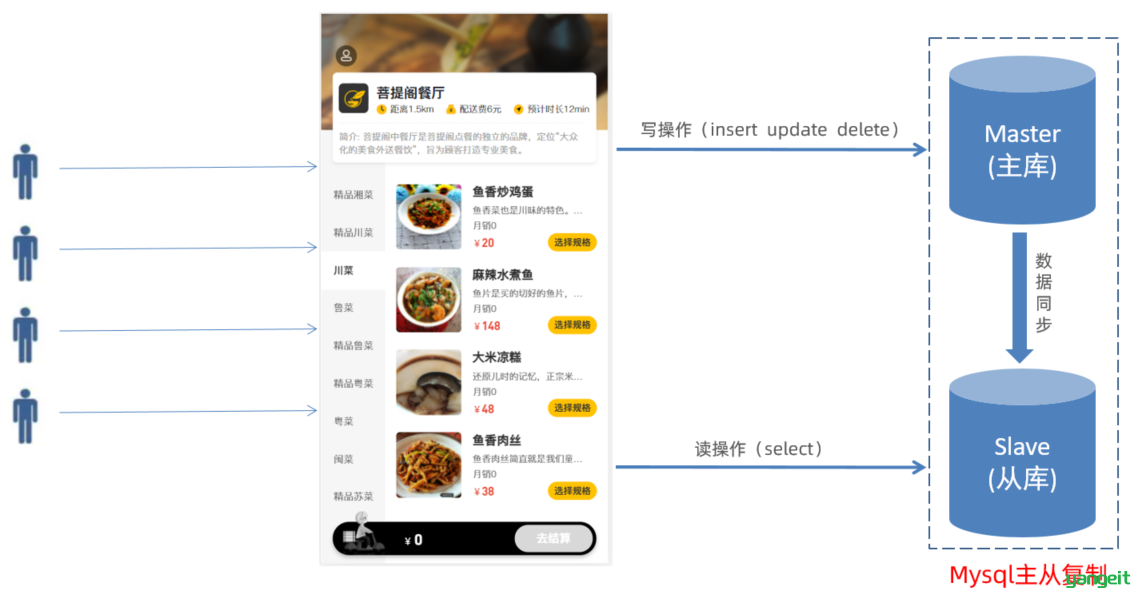
- 两台MySQL,一台主(Master)服务器,一台从(Slave)服务器,
- 主库的数据变更,需要同步到从库中(主从复制)。
- 用户在访问我们项目时
- 如果是写操作(insert、update、delete),则直接操作主库;
- 如果是读(select)操作,则直接操作从库(在这种读写分离的结构中,从库是可以有多个的),
这种结构我们称为 。
今天我们就需要实现上述的架构,来解决业务开发中所存在的问题。🎉 🎉 🎉 🎉
1. MySQL主从复制 🍐
MySQL数据库默认是支持主从复制的,不需要借助于其他的技术,我们只需要在数据库中简单的配置即可。接下来,我们就从以下的几个方面,来介绍一下主从复制:
1.1 介绍
问题
- MySQL主从复制能解决什么问题?
MySQL主从复制是一个异步的复制过程,底层是基于Mysql数据库自带的 二进制日志 功能。就是一台或多台MySQL数据库(slave,即从库)从另一台MySQL数据库(master,即主库)进行日志的复制,然后再解析日志并应用到自身,最终实现 从库 的数据和 主库 的数据保持一致。MySQL主从复制是MySQL数据库自带功能,无需借助第三方工具。
二进制日志:
二进制日志(BINLOG) DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但是不包括数据查询语句。此日志对于灾难时的数据恢复起着极其重要的作用,MySQL的主从复制, 就是通过该实现的。
MySQL的主从复制原理如下: 🎥
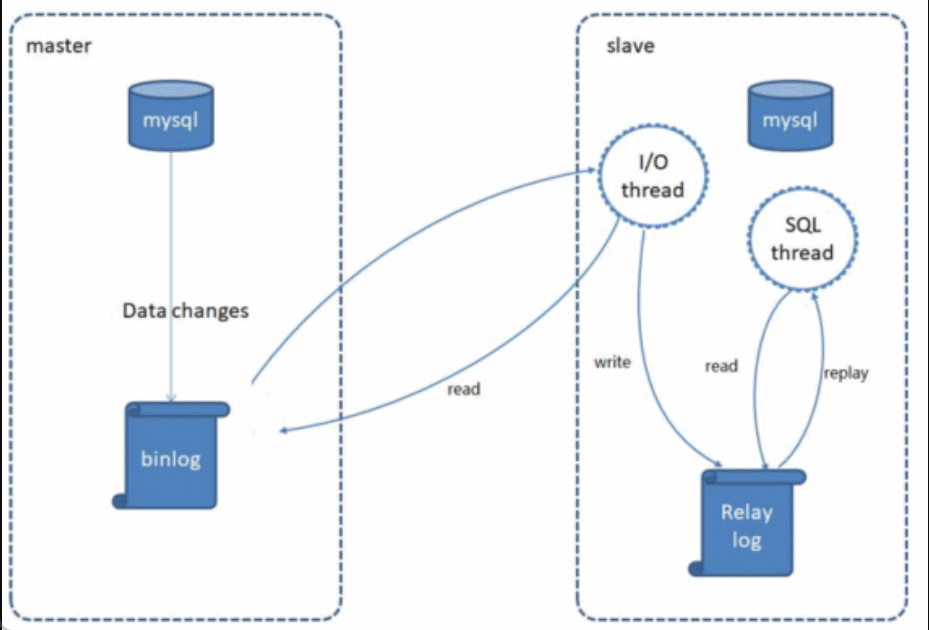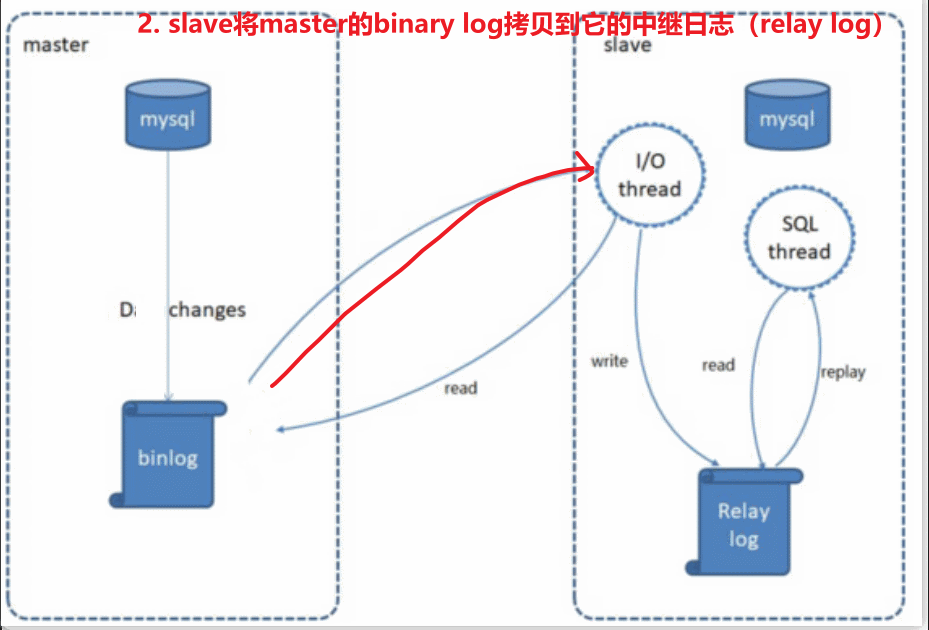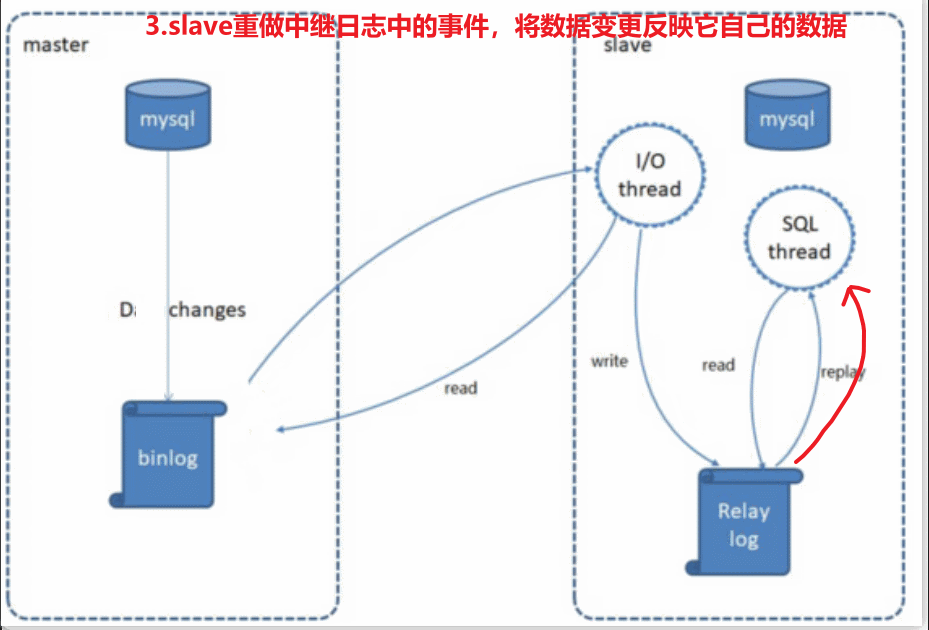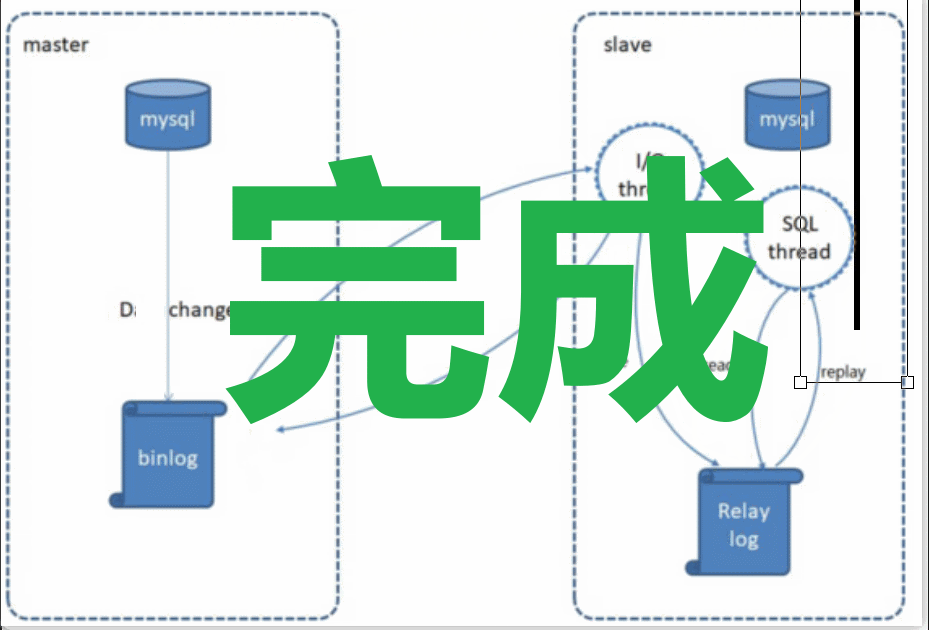
MySQL复制过程分成三步:
1). MySQL master 将数据变更写入二进制日志( binary log)
2). slave将master的binary log拷贝到它的中继日志(relay log)
3). slave重做中继日志中的事件,将数据变更反映它自己的数据
1.2 搭建 ✏️
问题
- 日志中有哪些信息?
1.2.1 准备工作
准备2台虚拟机的gif动画教程:🎥
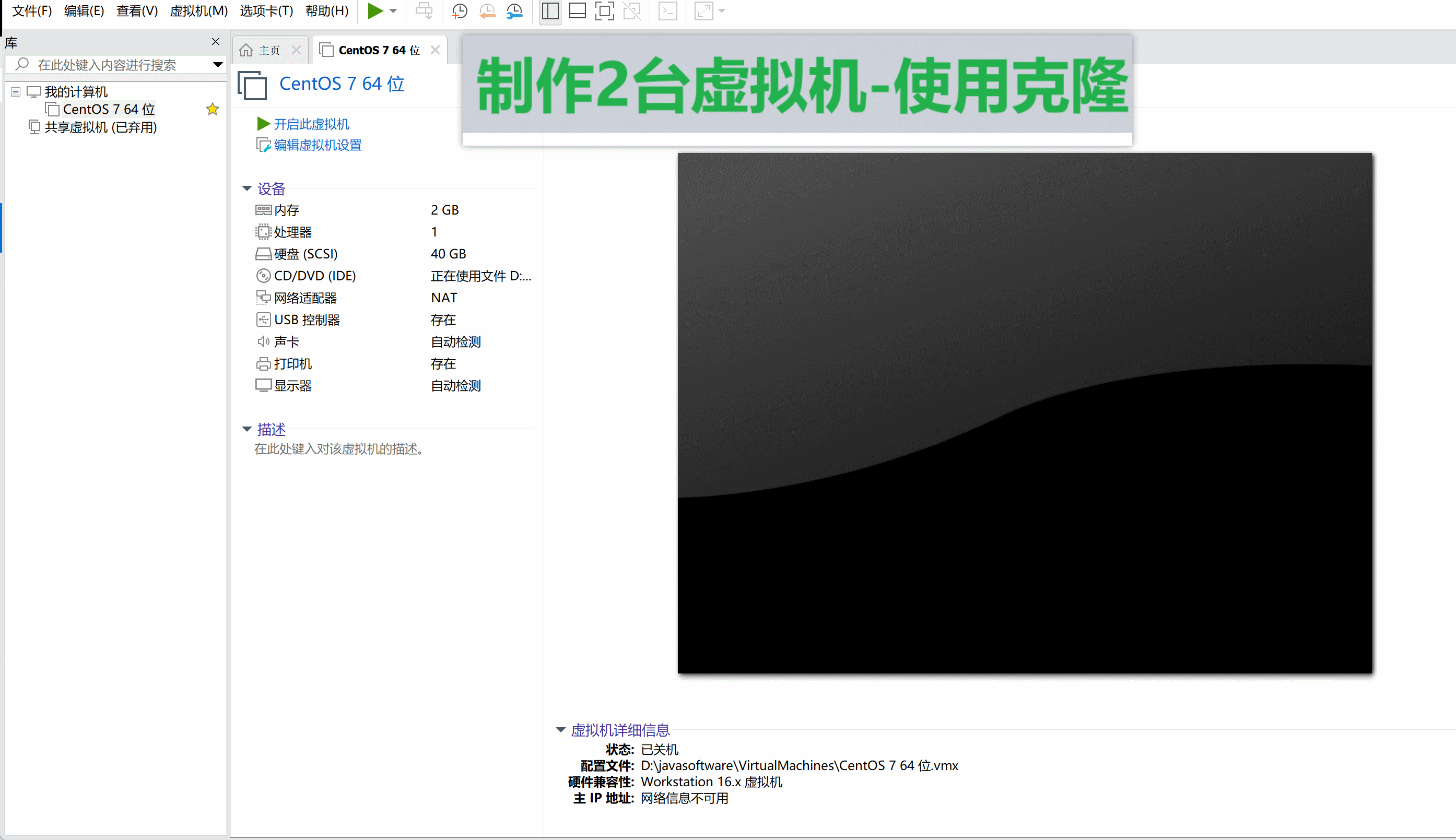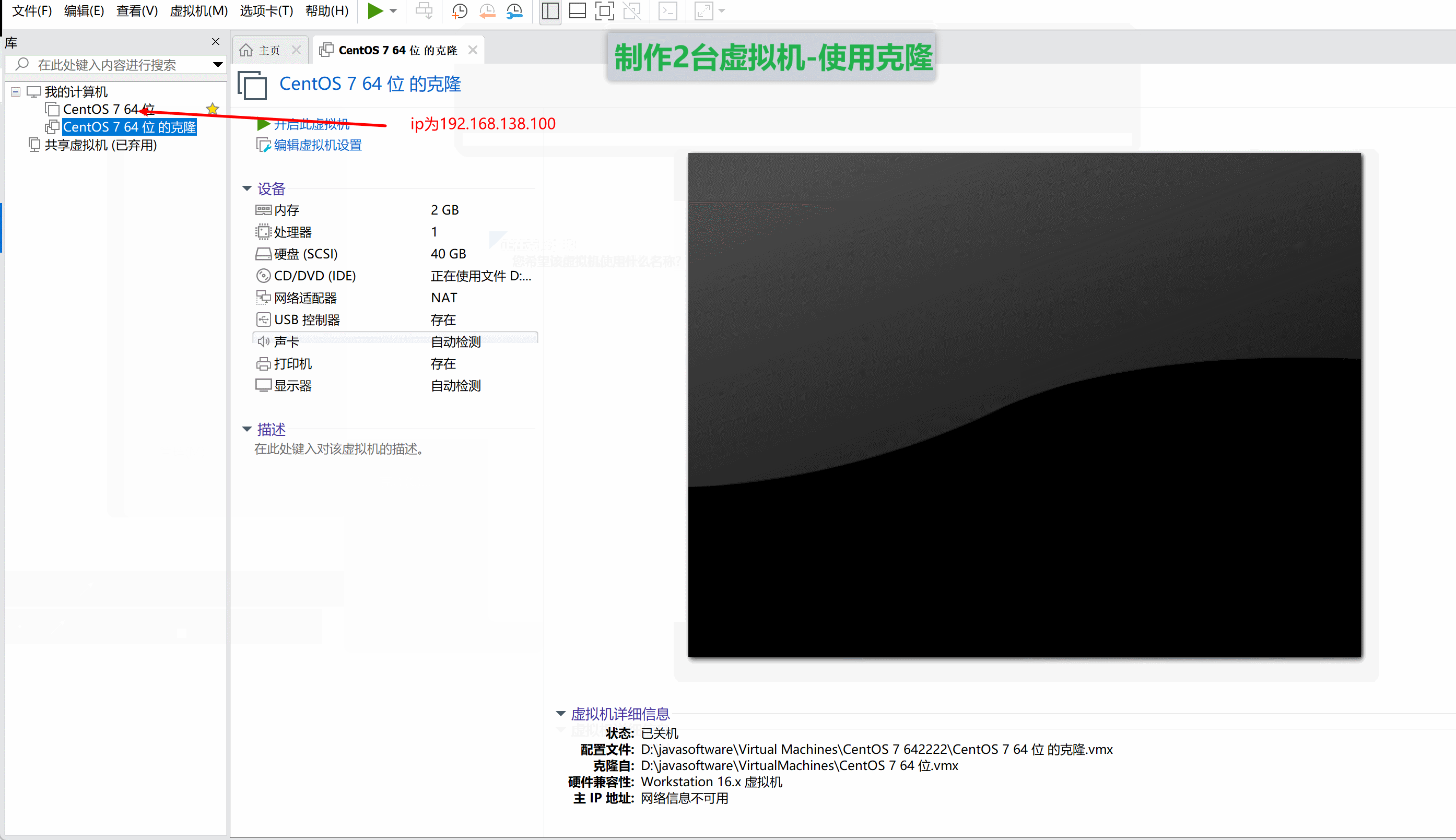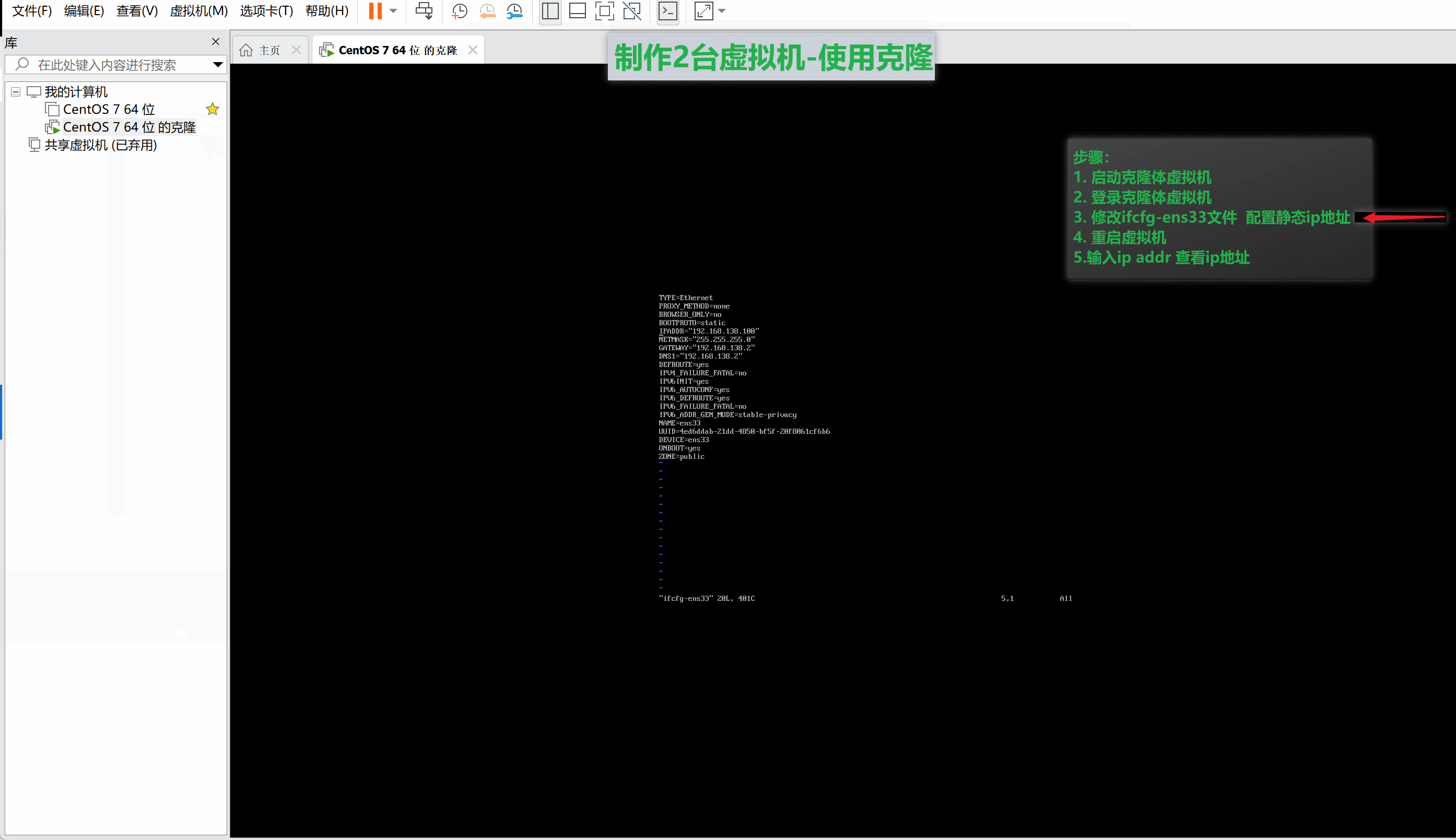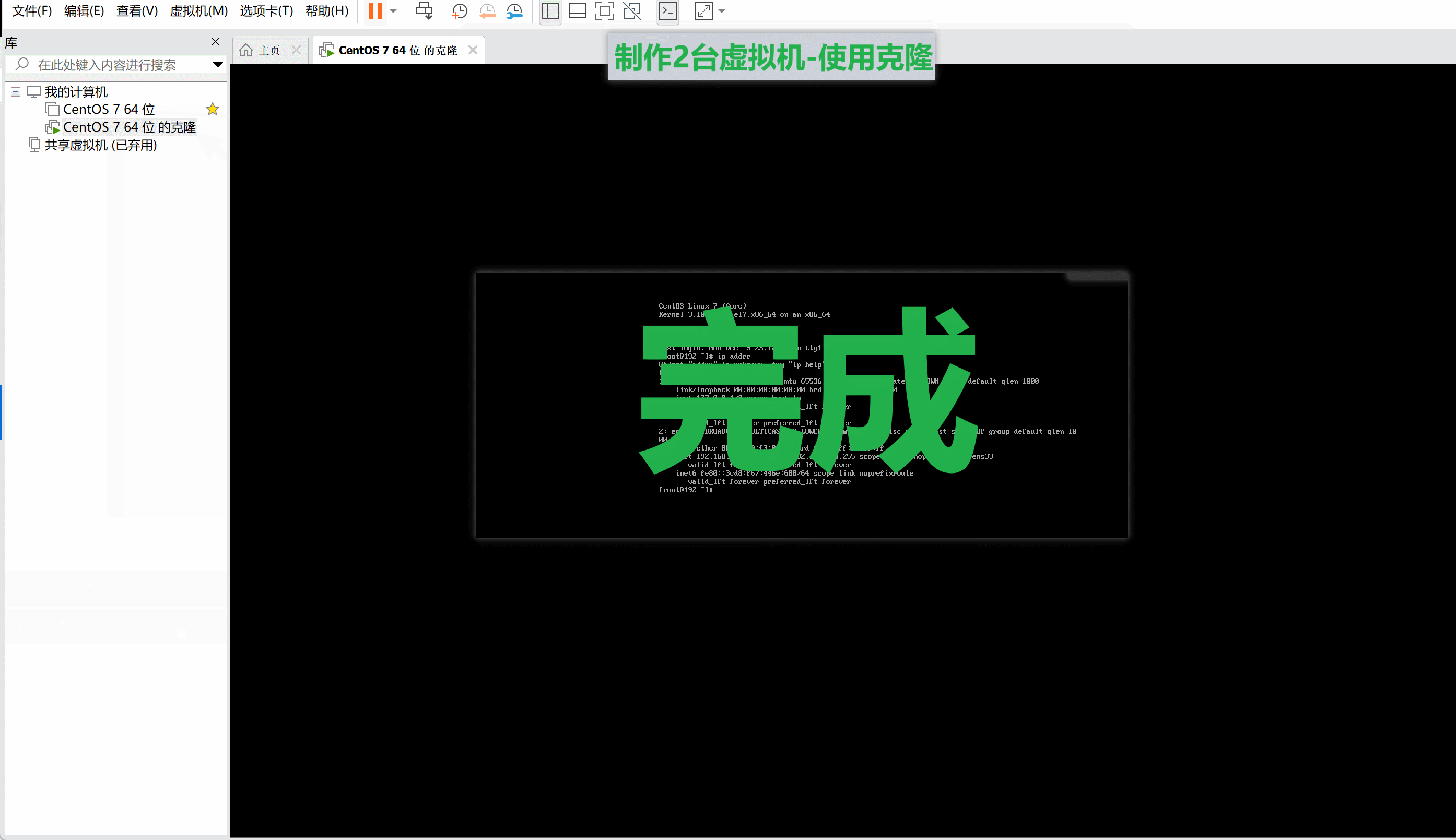
提前准备两台服务器,并且在服务器中安装MySQL,服务器的信息如下:
| 数据库 | IP | 数据库版本 |
|---|---|---|
| Master | 192.168.200.200 | 5.7.25 |
| Slave | 192.168.200.201 | 5.7.25 |
警告
⚠️ ⚠️ 注意:如果是clone的机器,mysql的uuid是一样的,出现Slave_IO_Running: Connecting /Slave_IO_Running: No错误。注意要进行修改,修改方案
并在两台服务器上做如下准备工作:
gif动画教程:🎥
 1). 防火墙开放3306端口号
1). 防火墙开放3306端口号
# 开放3306端口
firewall-cmd --zone=public --add-port=3306/tcp --permanent
# 重载防火墙
# 查看3306端口
firewall-cmd --zone=public --list-ports

2). 并将两台数据库服务器启动起来:
# 先检查mysqld是否启动了,如果启动了,可以先kill
ps -ef | grep mysqld
# kill 杀死进程
kill -9 进程id
# 重新启动mysqld服务
systemctl start mysqld
登录MySQL,验证是否正常启动
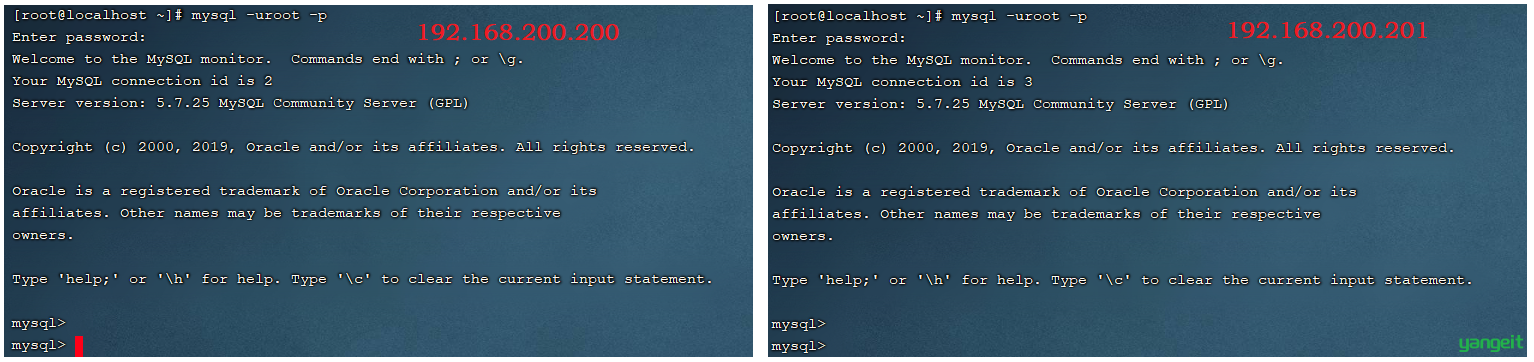
1.2.2 主库配置
服务器: 192.168.200.200
问题
- 主库需要增加什么配置?
1). 修改Mysql数据库的配置文件/etc/my.cnf
在最下面增加配置: ⚠️ ⚠️
log-bin=mysql-bin #[必须]启用二进制日志
server-id=200 #[必须]服务器唯一ID(唯一即可)
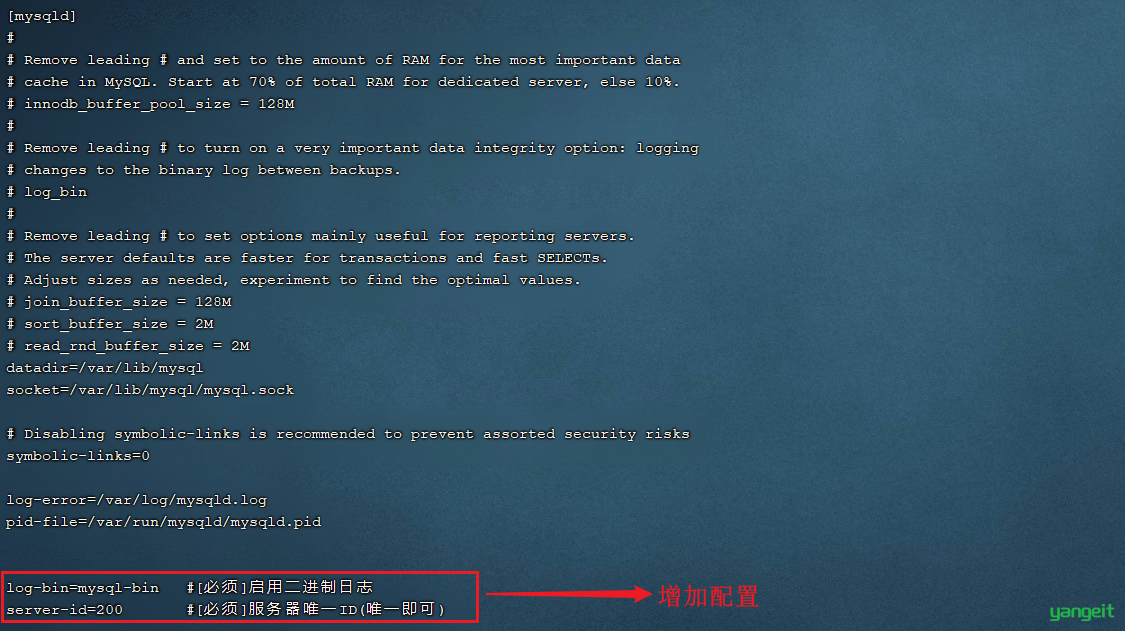
2). 重启Mysql服务
执行指令:
systemctl restart mysqld

3). 创建数据同步的用户并授权
登录mysql,并执行如下指令,创建用户并授权:
GRANT REPLICATION SLAVE ON *.* to 'xiaoming'@'%' identified by 'Root@123456';
注:上面SQL的作用是创建一个用户 xiaoming ,密码为 Root@123456 ,并且给xiaoming用户授予REPLICATION SLAVE权限。常用于建立复制时所需要用到的用户权限,也就是slave必须被master授权具有该权限的用户,才能通过该用户复制。
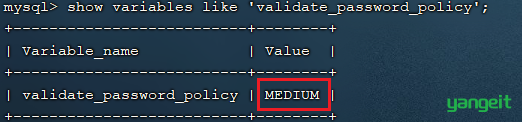
MySQL密码复杂程度说明:
目前mysql5.7默认密码校验策略等级为 MEDIUM , 该等级要求密码组成为: 数字、小写字母、大写字母 、特殊字符、长度至少8位
4). 登录Mysql数据库,查看master同步状态
执行下面SQL,记录下结果中File和Position的值
show master status;

注:上面SQL的作用是查看Master的状态,执行完此SQL后不要再执行任何操作
1.2.3 从库配置
服务器: 192.168.200.201
问题
- 从库的server-id 和主库的server-id 能一样吗?
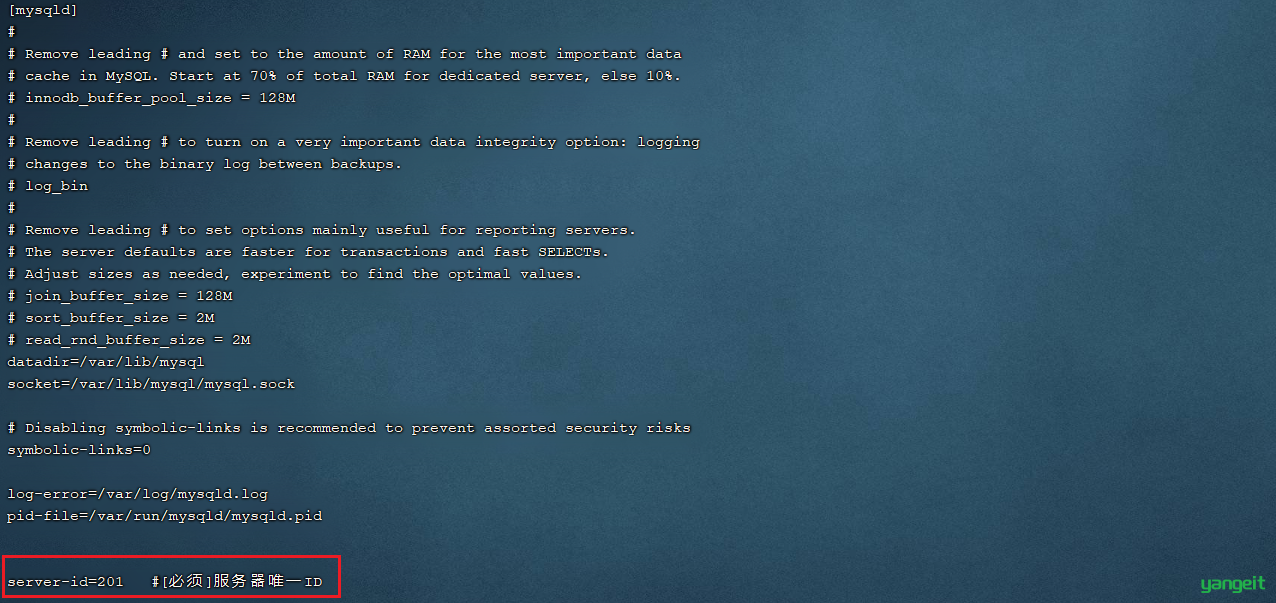
1). 修改Mysql数据库的配置文件/etc/my.cnf ⚠️ ⚠️
server-id=201 #[必须]服务器唯一ID
2). 重启Mysql服务
systemctl restart mysqld
3). 登录Mysql数据库,设置主库地址及同步位置
change master to master_host='192.168.31.131',master_user='xiaoming',master_password='Root@123456',master_log_file='mysql-bin.000001',master_log_pos=441;
-- start slave;启动从服务器
start slave;
-- 如果执行stop slave 是停止从服务器的
参数说明:
A. master_host : 主库的IP地址
B. master_user : 访问主库进行主从复制的用户名(上面在主库创建的)
C. master_password : 访问主库进行主从复制的用户名对应的密码
D. master_log_file : 从哪个日志文件开始同步(上述查询master状态中展示的有)
E. master_log_pos : 从指定日志文件的哪个位置开始同步(上述查询master状态中展示的有)
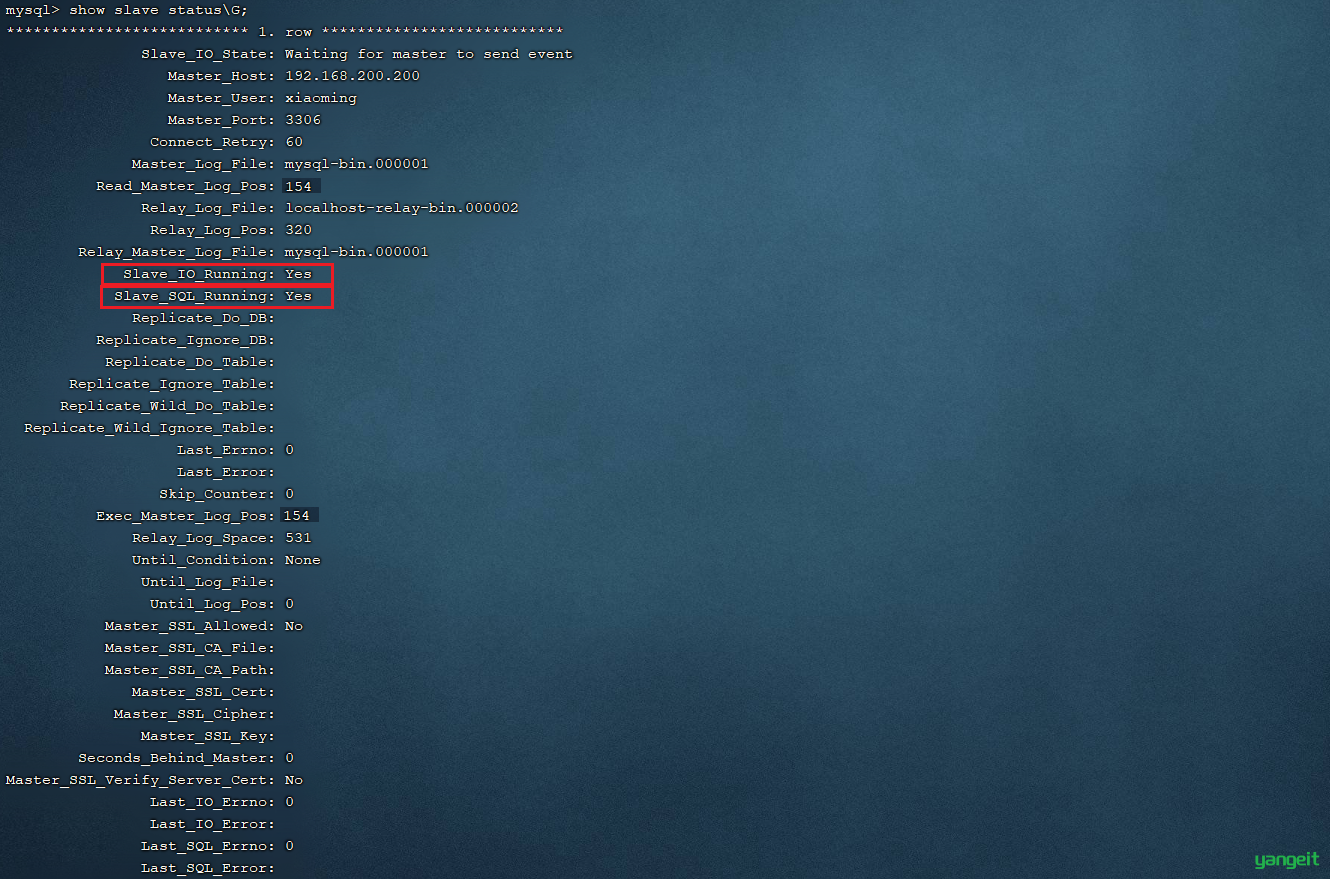
4). 查看从数据库的状态
show slave status;
然后通过状态信息中的 Slave_IO_running 和 Slave_SQL_running 可以看出主从同步是否就绪,如果这两个参数全为Yes,表示主从同步已经配置完成。
注意:
主库和从库的serverid一定要不同 ⚠️ ⚠️
可以将信息复制到文本编辑器中查看
MySQL命令行技巧:
\G : 在MySQL的sql语句后加上\G,表示将查询结果进行按列打印,可以使每个字段打印到单独的行。即将查到的结构旋转90度变成纵向;
1.3 测试 ✏️
问题
- 日志中有哪些信息?
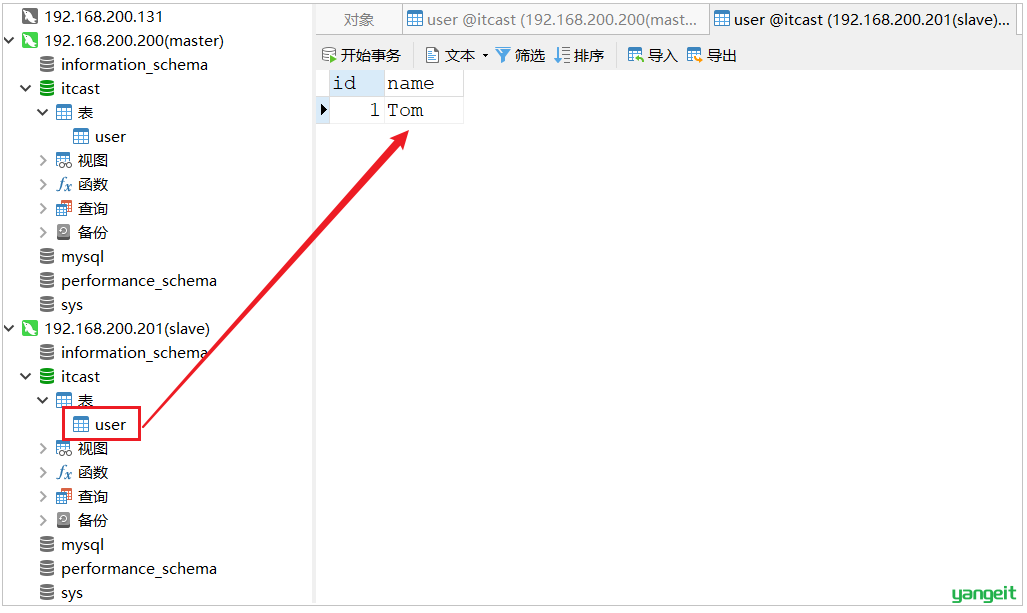
主从复制的环境,已经搭建好了,接下来,我们可以通过Navicat连接上两台MySQL服务器,进行测试。测试时,我们只需要在主库Master执行操作,查看从库Slave中是否将数据同步过去即可。
1). 在master中创建数据库itcast, 刷新slave查看是否可以同步过去

2). 在master的itcast数据下创建user表, 刷新slave查看是否可以同步过去

3). 在master的user表中插入一条数据, 刷新slave查看是否可以同步过去
2. 读写分离案例
2.1 背景介绍 🍐
问题
- 读写分离的作用或应用场景?
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
通过读写分离,就可以降低单台数据库的访问压力, 提高访问效率,也可以避免单机故障。
相关信息
主从复制的结构,我们在第一节已经完成了,那么我们在项目中:
- 如何通过java代码来完成读写分离呢?
- 如何在执行select的时候查询从库,而在执行insert、update、delete的时候,操作主库呢?
这个时候,我们就需要介绍一个新的技术 。
2.2 ShardingJDBC介绍
问题
- Sharding-JDBC框架有何特点?
Sharding-JDBC定位为,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
使用Sharding-JDBC可以在程序中。
Sharding-JDBC具有以下几个特点:
1). 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
2). 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
3). 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
依赖:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2.3 数据库环境
准备工作
- 2个虚拟机,2个mysql数据库
- 配置好主从复制
- 在主库中创建一个库和一张测试表
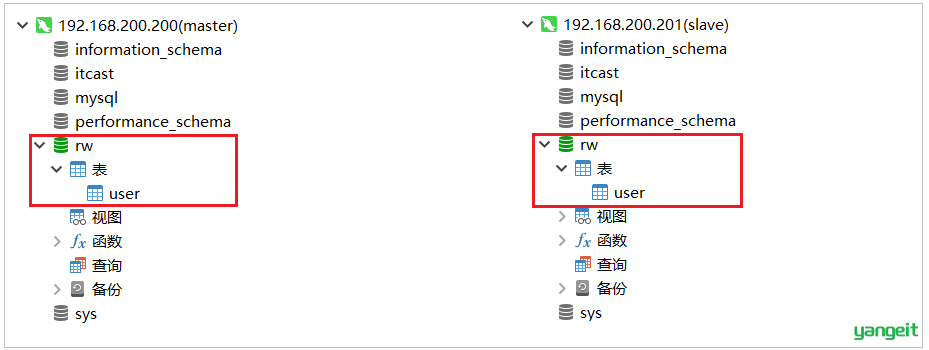
在主库中创建一个数据库rw, 并且创建一张表, 该数据库及表结构创建完毕后会自动同步至从数据库,SQL语句如下:
create database rw default charset utf8mb4;
use rw;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`address` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2.4 初始工程导入
问题
- yml文件中需要配置mp的数据源信息吗?
我们本案例主要是演示一下读写分离操作,对于基本的增删改查的业务操作,我们就不再去编写了,我们可以直接导入资料中提供的demo工程(rw_demo),在demo工程中,我们已经完成了user的增删改查操作,具体的工程结构如下:

2.5 读写分离配置 ✏️
问题
- 配置了读写分离后,项目中的java代码需要修改吗?
1). 在pom.xml中增加shardingJdbc的maven坐标
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2). 在application.yml中增加数据源的配置
spring:
shardingsphere:
datasource:
names:
master,slave
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.200.200:3306/rw?characterEncoding=utf-8&useSSL=false
username: root
password: root
# 从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.200.201:3306/rw?characterEncoding=utf-8
username: root
password: root
masterslave:
# 读写分离配置(从库可能有多个,轮着来比较均匀和公平)
load-balance-algorithm-type: round_robin #轮询
# 最终的数据源名称
name: dataSource
# 主库数据源名称
master-data-source-name: master
# 从库数据源名称列表,多个逗号分隔 如slave ,slave2
slave-data-source-names: slave
props:
sql:
show: true #开启SQL显示,默认false
配置解析:

3). 在application.yml中增加配置
该配置项的目的,就是如果当前项目中存在同名的bean,后定义的bean会覆盖先定义的。
spring:
main:
# 允许bean定义覆盖 ,该配置项的目的,就是如果当前项目中存在同名的bean,后定义的bean会覆盖先定义的。
allow-bean-definition-overriding: true
如果不配置该项,项目启动之后将会报错:

报错信息表明,在声明 org.apache.shardingsphere.shardingjdbc.spring.boot 包下的SpringBootConfiguration中的dataSource这个bean时出错, 原因是有一个同名的 dataSource 的bean在com.alibaba.druid.spring.boot.autoconfigure包下的DruidDataSourceAutoConfigure类加载时已经声明了。
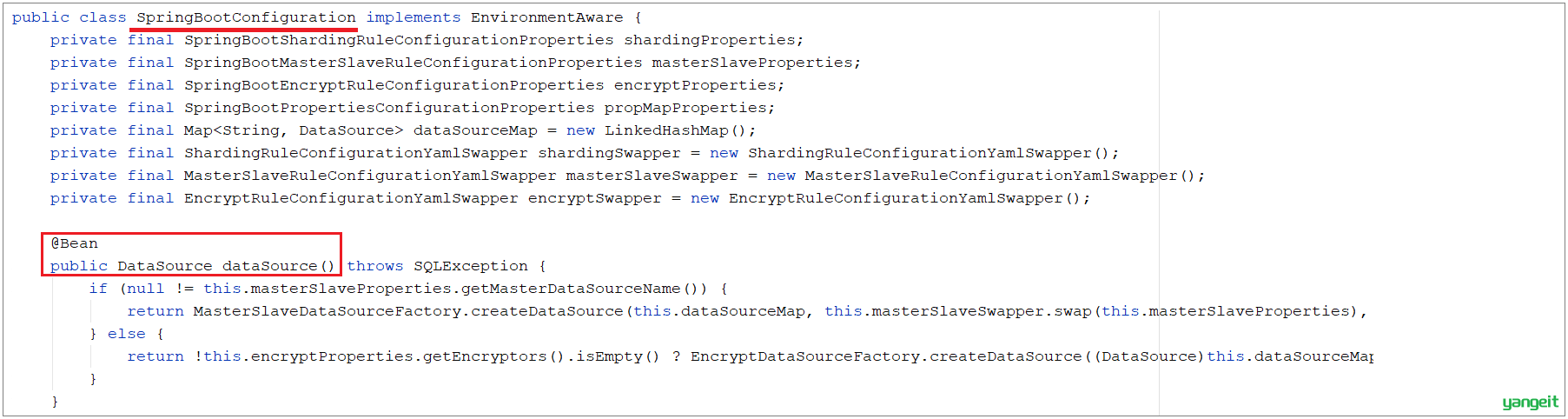
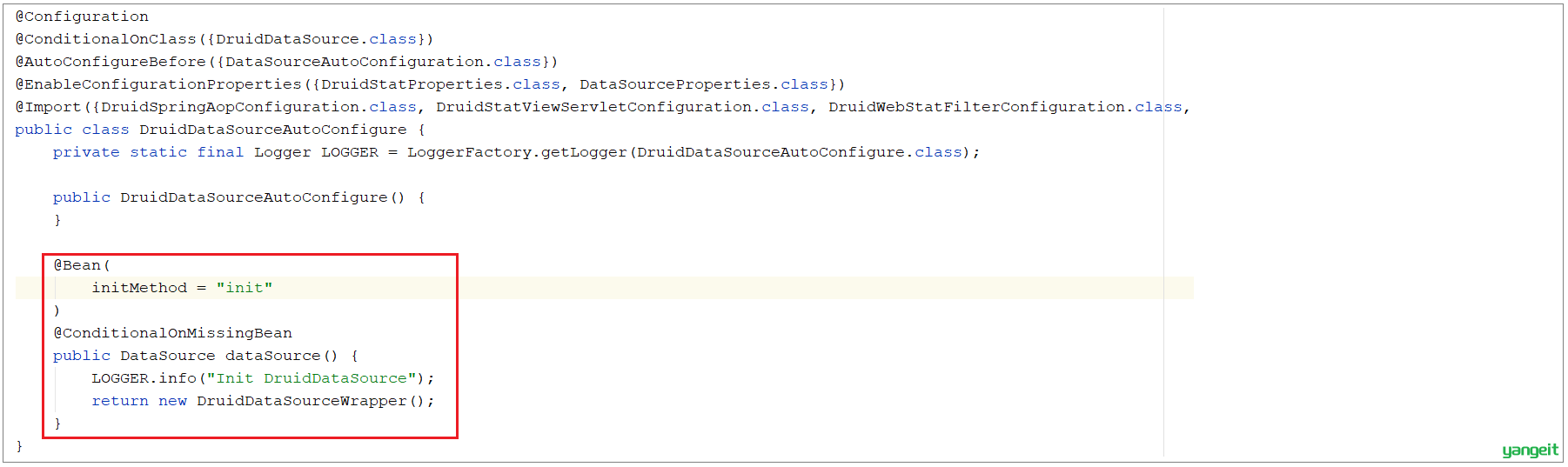
而我们需要用到的是 shardingjdbc包下的dataSource,所以我们需要配置上述属性,让后加载的覆盖先加载的。
2.6 测试 ✏️
问题
- 怎样能直观的看到插入和查询是不同的数据源?
我们使用shardingjdbc来实现读写分离,直接通过上述简单的配置就可以了。配置完毕之后,我们就可以重启服务,通过postman来访问controller的方法,来完成用户信息的增删改查,我们可以通过debug及日志的方式来查看每一次执行增删改查操作,使用的是哪个数据源,连接的是哪个数据库。
1). 保存数据
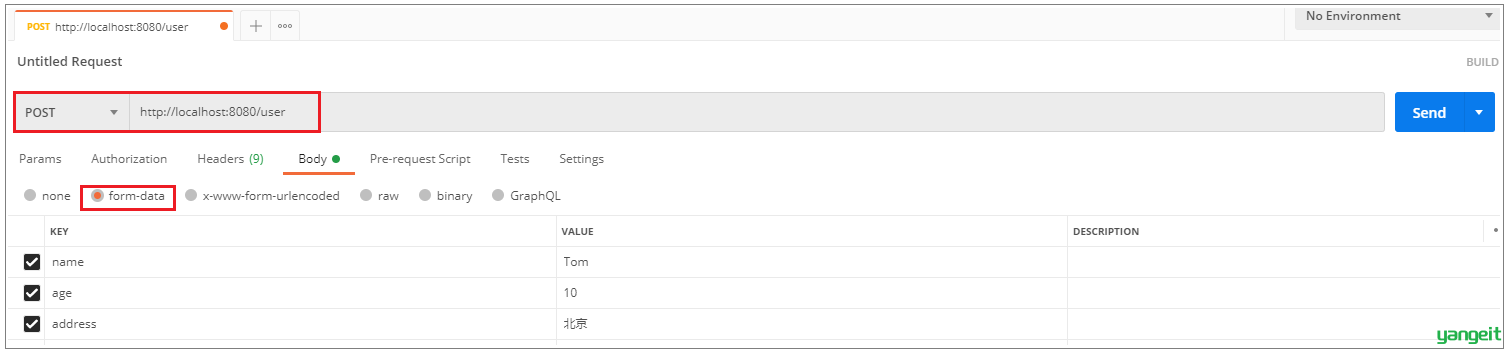
控制台输出日志,可以看到操作master主库:

2). 修改数据
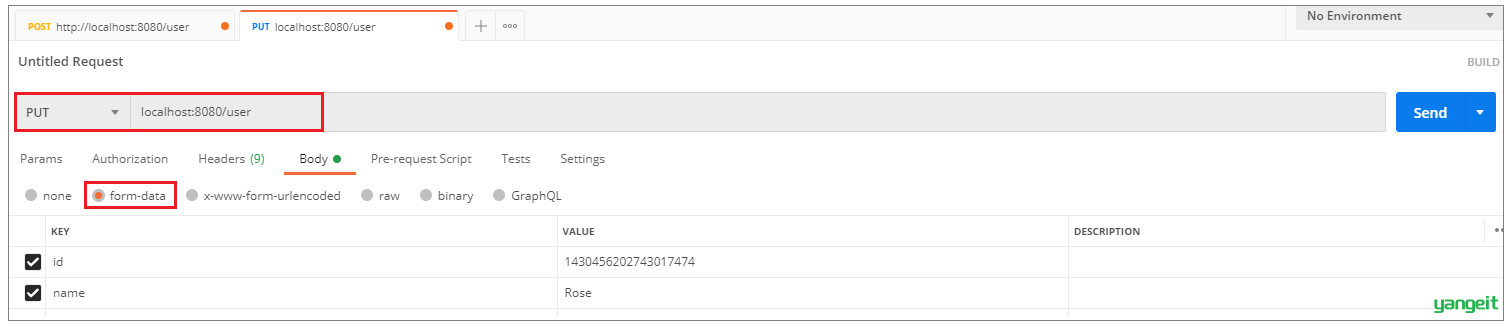
控制台输出日志,可以看到操作master主库:

3). 查询数据

控制台输出日志,可以看到操作slave主库:

4). 删除数据

控制台输出日志,可以看到操作master主库:

3. 项目实现读写分离
3.1 数据库环境准备
问题
- 在主库创建reggie数据库后,从库要单独创建吗?
直接使用我们前面在虚拟机中搭建的主从复制的数据库环境即可。在主库中创建瑞吉外卖项目的业务数据库reggie, 并导入相关表结构和数据(我们可以将自己之前在本地开发时使用的数据库数据导出, 然后导入到服务器中的主库即可)。
1). 将自己本地的reggie数据库的数据导出SQL文件
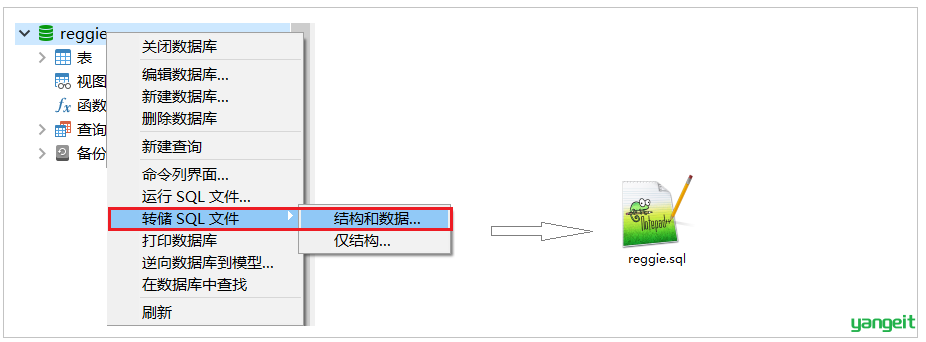
这样做的话,我们之前自己开发时,添加的测试数据都还在的,便于测试。
2). 在主数据库master中,创建数据库reggie,并导入该SQL文件
master中创建数据库,会自动同步至slave从库
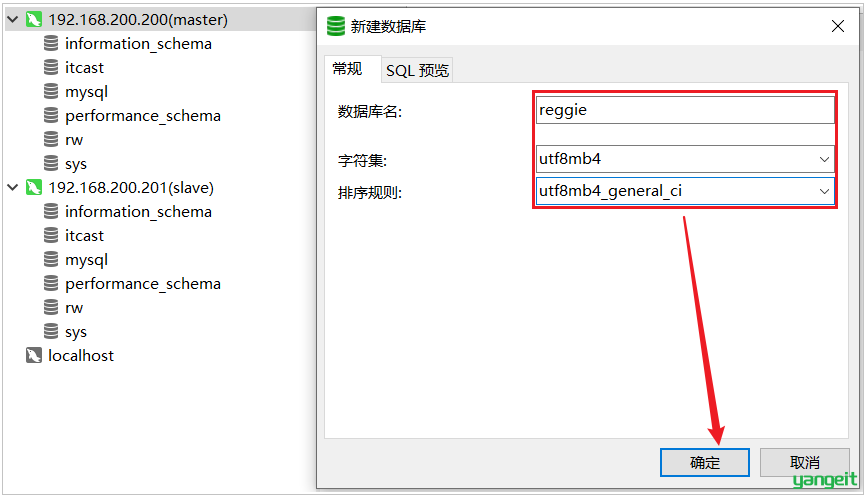
在master的reggie中导入sql文件
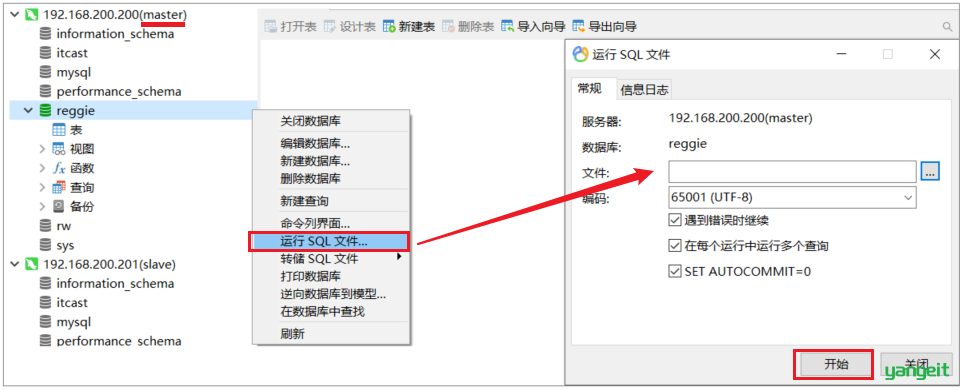
3.2 创建Git分支
问题
- 瑞吉集成读写分离功能需要修改Java代码吗?
目前默认git中有两个分支master 和 v1.0 ,我们接下来进行读写分离的优化,就不在master和v1.0分支来操作了,我们需要在git上创建一个单独的分支v1.1,读写分离的优化,我们就在该分支上进行操作。具体创建分支的操作,和前面演示的一致。
当前创建的v1.1分支,是基于master分支创建出来的,所以目前master分支的代码, 和v1.1分支的代码是完全一样的,接下来把v1.1的代码也推送至远程仓库。
3.3 读写分离配置 ✏️
1). 在项目的pom.xml增加依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2). 在项目的application.yml中配置数据源相关信息
spring:
shardingsphere:
datasource:
names:
master,slave
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.200.200:3306/reggie?characterEncoding=utf-8
username: root
password: root
# 从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.200.201:3306/reggie?characterEncoding=utf-8
username: root
password: root
masterslave:
# 读写分离配置
load-balance-algorithm-type: round_robin #轮询
# 最终的数据源名称
name: dataSource
# 主库数据源名称
master-data-source-name: master
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave
props:
sql:
show: true #开启SQL显示,默认false
main:
allow-bean-definition-overriding: true
3.4 功能测试 ✏️
配置完毕之后,我们启动项目进行测试,直接访问系统管理后台的页面,然后执行相关业务操作,看控制台输出的日志信息即可。
查询操作:

更新操作:

插入操作:

删除操作:

3.5 Git合并代码
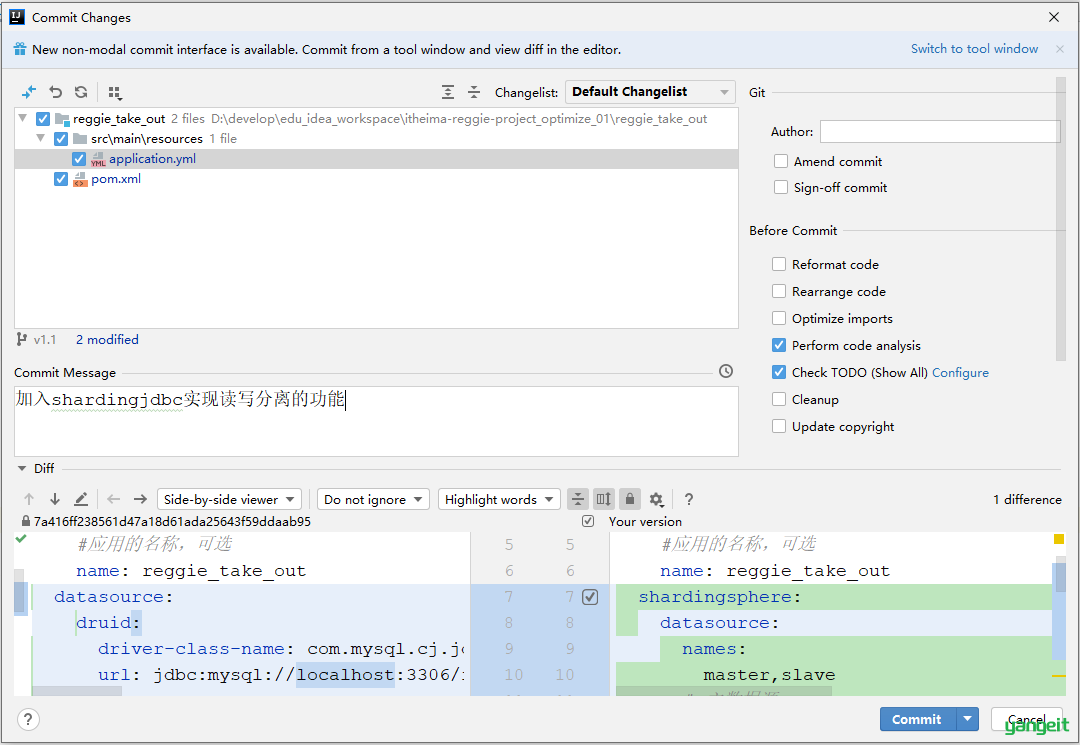
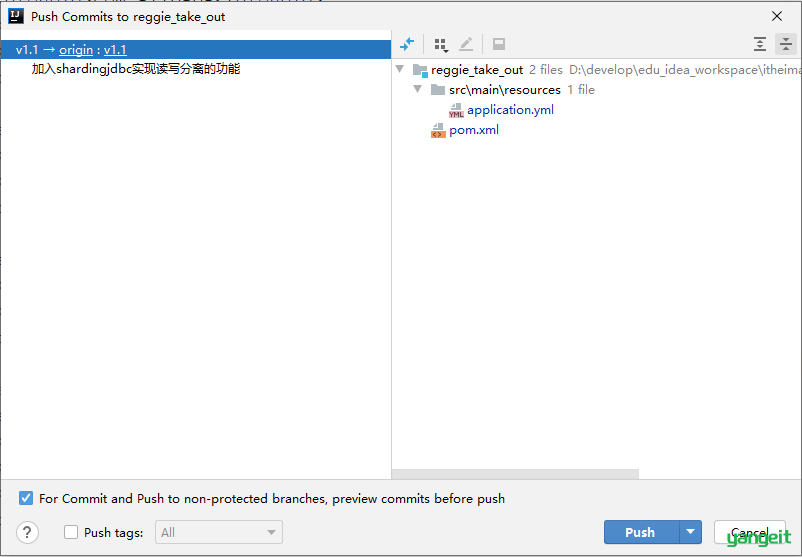
读写分离的功能我们已经实现完毕了,那么接下来,我们就可以将当前分支v1.1代码提交并推送到远程仓库。
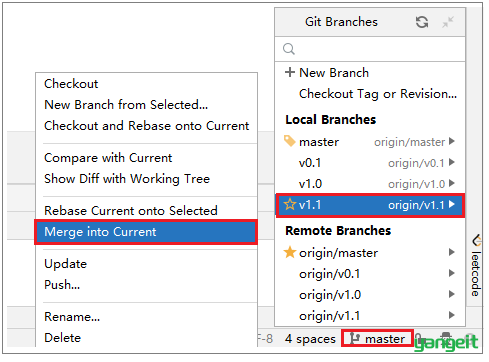
然后,再将v1.1的代码,合并到master分支,然后推送至远程仓库。
4. Nginx-概述
4.1 介绍 🍐
问题
- Nginx能做什么?有什么特点?

Nginx是一款轻量级的Web服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。其特点是,事实上nginx的并发能力在同类型的网页服务器中表现较好,中国大陆使用nginx的网站有:百度、京东、新浪、网易、腾讯、淘宝等。
Nginx是由伊戈尔·赛索耶夫为俄罗斯访问量第二的Rambler.ru站点(俄文:Рамблер)开发的,第一个公开版本0.1.0发布于2004年10月4日。
4.2 下载和安装 ✏️
4.2.1 下载
在Nginx的官网的下载页面中(http://nginx.org/en/download.html),就展示了当前Nginx版本,并提供了下载的连接。 如下:
在本项目中,我们所学习的Nginx选择的是稳定版本的1.16这个版本,我们可以直接从官网下载,当然在我们的课程资料中也已经提供了该版本的安装包。
4.2.2 linux安装部署
1). 安装依赖包
由于nginx是基于c语言开发的,所以需要安装c语言的编译环境,及正则表达式库等第三方依赖库。
yum -y install gcc pcre-devel zlib-devel openssl openssl-devel
2). 下载Nginx安装包
yum -y install wget
wget https://nginx.org/download/nginx-1.16.1.tar.gz
wget :
wget命令用来从指定的URL下载文件。wget非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性,如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕。如果是服务器打断下载过程,它会再次联到服务器上从停止的地方继续下载。
执行完wget指令后,就会在当前所在目录看到下载下来的文件。
3). 解压nginx压缩包
tar -zxvf nginx-1.16.1.tar.gz
4). 配置Nginx编译环境
cd nginx-1.16.1
./configure --prefix=/usr/local/nginx
说明:
--prefix 指定的目录,就是我们安装Nginx的目录。
5). 编译&安装
make & make install
4.2.3 windows 安装部署 👈
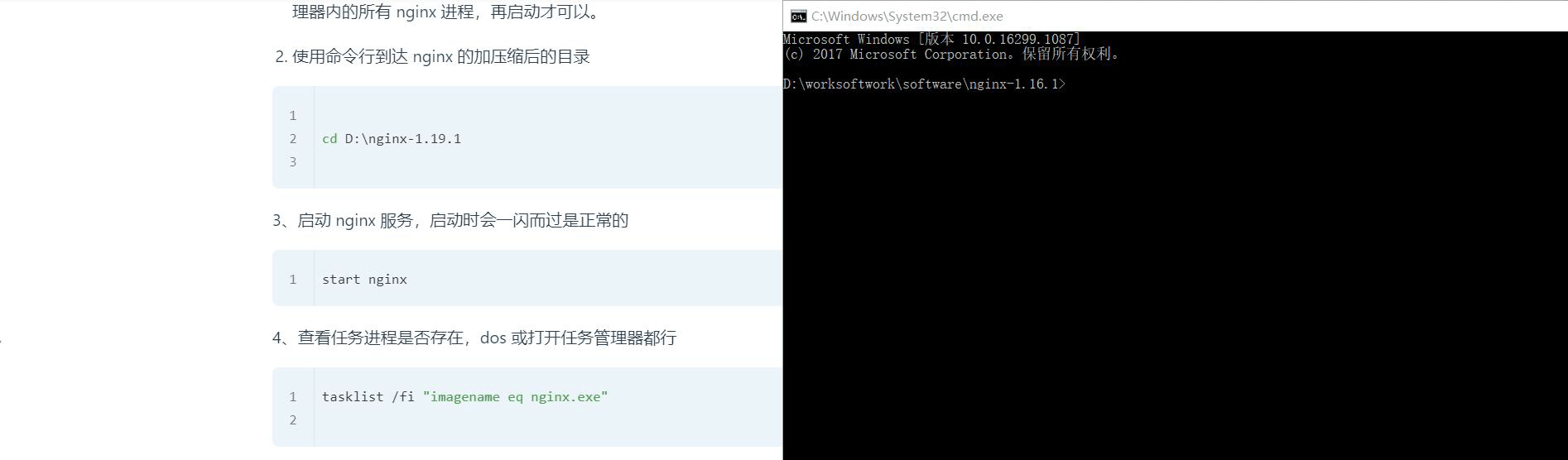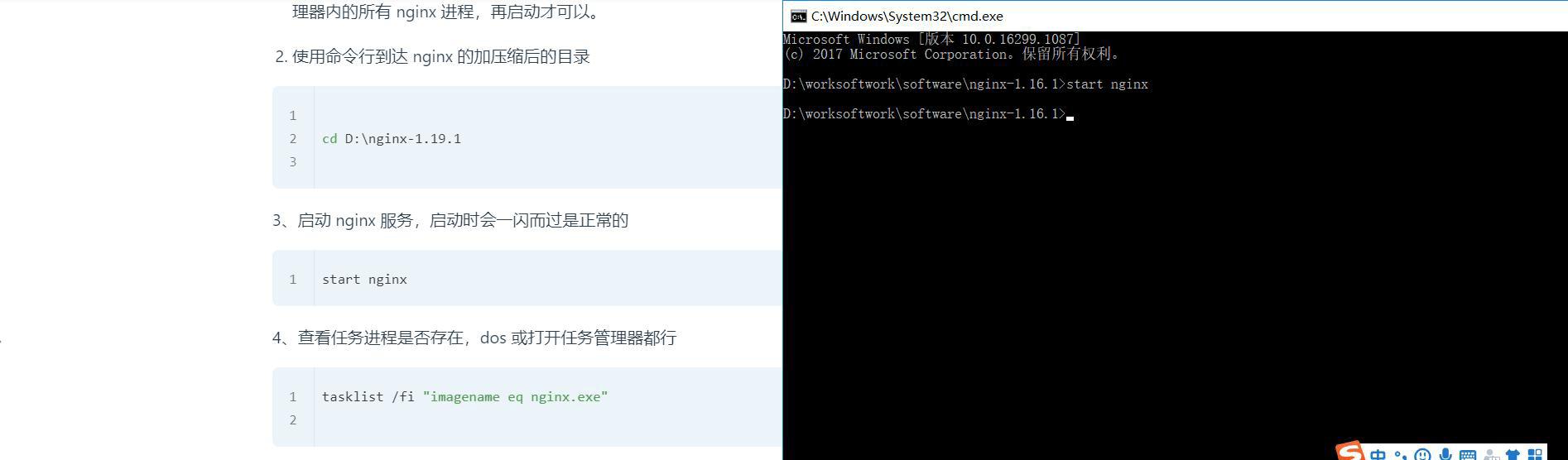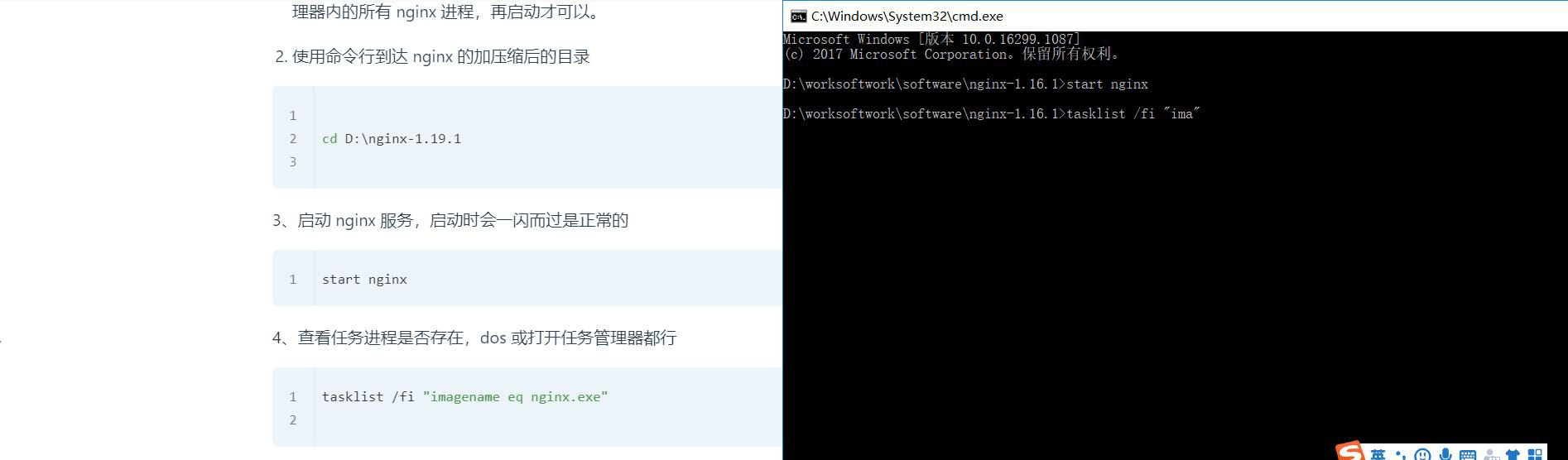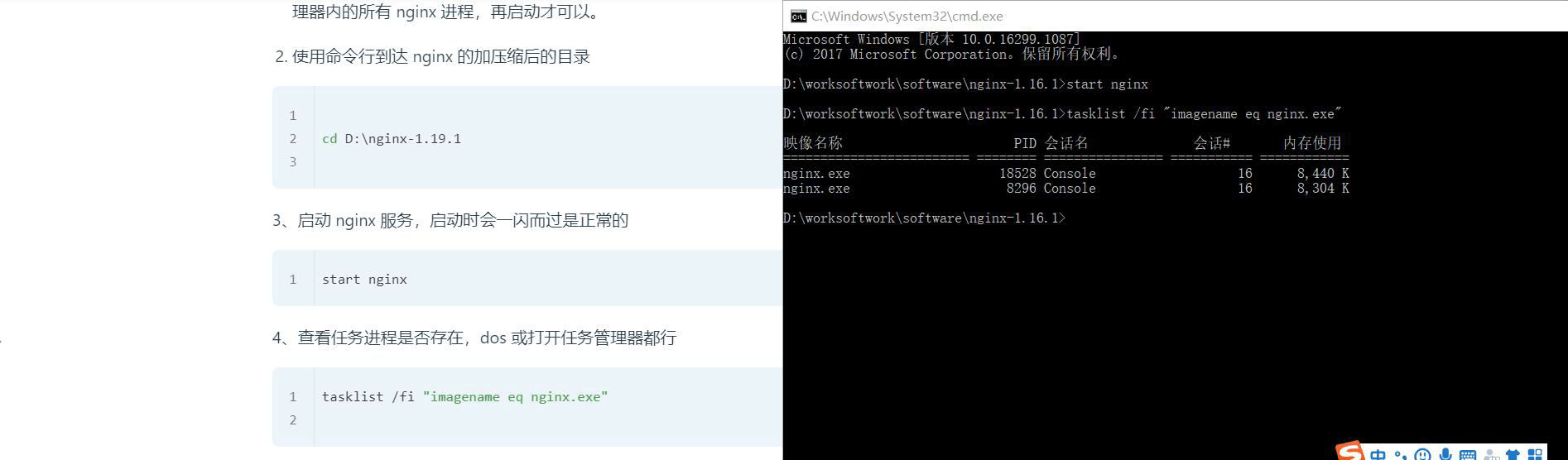
下载完成后,解压缩,运行 cmd,使用命令进行操作,,,不要直接双击 nginx.exe,这样会导致修改配置后重启、停止 nginx 无效,需要手动关闭任务管理器内的所有 nginx 进程,再启动才可以。
使用命令行到达 nginx 的加压缩后的目录
# cd 到你的解压缩目录
cd D:\nginx-1.16.1
3、启动 nginx 服务,
start nginx
4、查看任务进程是否存在,dos 或打开任务管理器都行
tasklist /fi "imagename eq nginx.exe"

4.3 目录结构 🍐
4.3.1 linux目录结构
安装完Nginx后,我们可以切换到Nginx的安装目录(/usr/local/nginx),先来熟悉一下Nginx的目录结构,如下图:

备注:
上述我们用到的一个指令 tree,该指令可以将我们指定的目录以树状结构展示出来。如果没有这个指令,可以通过以下指令进行安装。
yum install tree
重点目录和文件如下:
| 目录/文件 | 说明 | 备注 |
|---|---|---|
| conf | 配置文件的存放目录 | |
| conf/nginx.conf | Nginx的核心配置文件 | conf下有很多nginx的配置文件,我们主要操作这个核心配置文件 |
| html | 存放静态资源(html, css, ) | 部署到Nginx的静态资源都可以放在html目录中 |
| logs | 存放nginx日志(访问日志、错误日志等) | |
| sbin/nginx | 二进制文件,用于启动、停止Nginx服务 |
4.3.2 windows 目录结构 👈

重点目录和文件如下:
| 目录/文件 | 说明 | 备注 |
|---|---|---|
| conf | 配置文件的存放目录 | |
| conf/nginx.conf | Nginx 的核心配置文件 | conf 下有很多 nginx 的配置文件,我们主要操作这个核心配置文件 |
| html | 存放静态资源(html, css, ) | 部署到 Nginx 的静态资源都可以放在 html 目录中 |
| logs | 存放 nginx 日志(访问日志、错误日志等) |
5. Nginx-命令
5.1 常用命令
问题
- Nginx常用命令有哪些?
Nginx中,我们的二进制可执行文件(nginx)存放在sbin目录下,虽然只有一个可执行文件,但是我们可以通过该指令配合不同的参数达到更加强大的功能。接下来,我们就演示一下Nginx常见指令, 在执行下面的指令时,都需要在/usr/local/nginx/sbin/目录下执行。
1). 查看版本
./nginx -v

2). 检查配置文件
修改了nginx.conf核心配置文件之后,在启动Nginx服务之前,可以先检查一下conf/nginx.conf文件配置的是否有错误,命令如下:
./nginx -t

3). 启动
./nginx
启动之后,我们可以通过ps -ef指令来查看nginx的进程是否存在。

注意: nginx服务启动后,默认就会有两个进程。
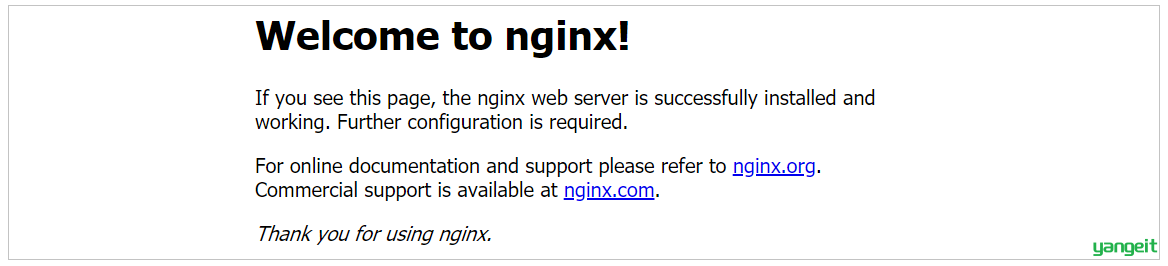
启动之后,我们可以直接访问Nginx的80端口, http://192.168.200.200
注意:
要想正常访问Nginx,需要关闭防火墙或开放指定端口号,执行的指令如下:
A. 关闭防火墙
systemctl stop firewalld
B. 开放80端口
firewall-cmd --zone=public --add-port=80/tcp --permanent
firewall-cmd --reload
4). 停止
./nginx -s stop
停止之后,我们可以查看nginx的进程:
ps -ef|grep nginx

5). 重新加载
当修改了Nginx配置文件后,需要重新加载才能生效,可以使用下面命令重新加载配置文件:
./nginx -s reload
5.2 环境变量配置
问题
- linux系统下环境变量在哪个文件中?
在上述我们在使用nginx命令在进行服务的启动、停止、重新加载时,都需要用到一个指令nginx,而这个指令是在nginx/sbin目录下的,我们每一次使用这个指令都需要切换到sbin目录才可以,使用相对繁琐。那么我们能不能在任意目录下都可以执行该指令来操作nginx呢?答案是可以的,配置nginx的环境变量即可。
通过vim编辑器,打开/etc/profile文件, 在PATH环境变量中增加nginx的sbin目录,如下:

修改完配置文件之后,需要执行 source /etc/profile 使文件生效。 接下来,我们就可以在任意目录下执行nginx的指令了,如:

6. Nginx-应用 🍐
介绍了并安装了Nginx之后,本章节将要讲解的是Nginx的使用,我们主要从以下四个方面进行讲解。
6.1 配置文件结构 🍐
问题
- nginx的配置文件分为几部分?
nginx的配置文件(conf/nginx.conf)整体上分为三部分: 。这三块的分别配置什么样的信息呢,看下表:
| 区域 | 职责 |
|---|---|
| 全局块 | 配置和nginx运行相关的全局配置 |
| events块 | 配置和网络连接相关的配置 |
| http块 | 配置代理、缓存、日志记录、虚拟主机等配置 |
具体结构图如下:
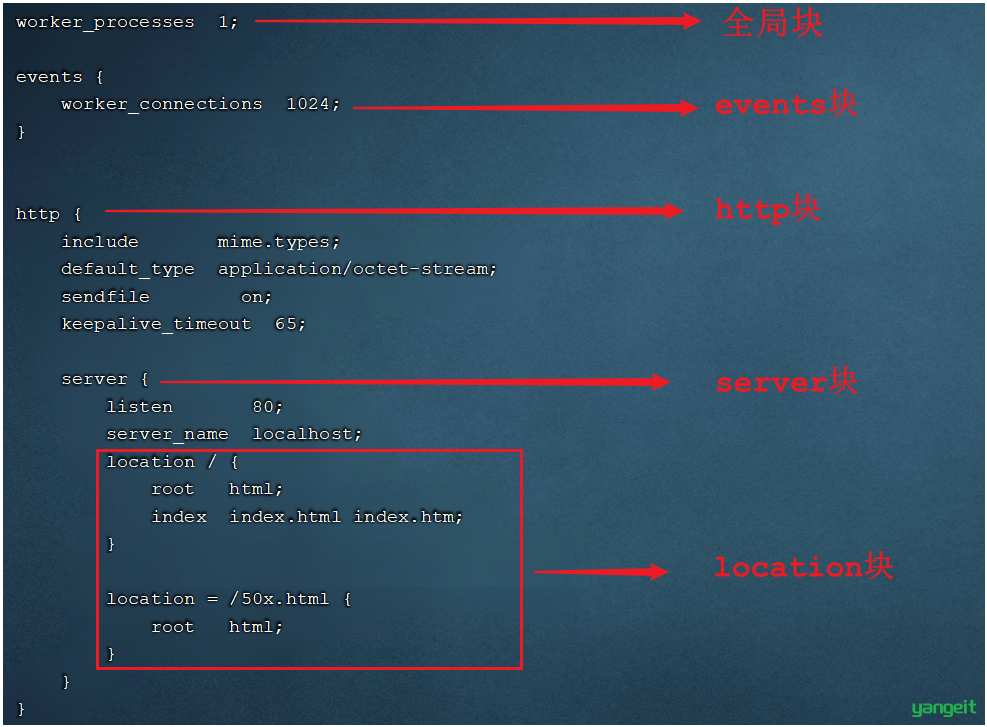
在全局块、events块以及http块中,我们经常配置的是http块。
在http块中可以包含多个server块,每个server块可以配置多个location块。
6.2 部署静态资源 🍐
6.2.1 介绍
问题
- 为什么使用Nginx部署静态资源?
Nginx可以作为静态web服务器来部署静态资源。这里所说的静态资源是指在服务端真实存在,并且能够直接展示的一些文件,比如常见的html页面、css文件、js文件、图片、视频等资源。
相对于Tomcat,Nginx处理静态资源的能力更加高效,所以在生产环境下,一般都会将静态资源部署到Nginx中。
将静态资源部署到Nginx非常简单,只需要将文件复制到Nginx安装目录下的html目录中即可。
server {
listen 80; #监听端口
location / { #匹配客户端请求url
root html; #指定静态资源根目录
index index.html; #指定默认首页
}
}
我们部署自己的静态资源?
1. 简单:把静态资源放入nginx安装目录下的html文件夹下
2. 在nginx安装目录下新建文件夹:reggie
将静态资源放进去
配置localhost中 root 属性的值reggie
需求:编辑一个html页面,部署到nginx中,使用浏览器访问
6.2.2 测试
在资料中,我们提供了一个静态的html文件,我们需要将这个文件部署到nginx中,然后通过nginx访问html静态资源。
1). 将静态资源上传到 /usr/local/nginx/html 目录

2). 启动nginx
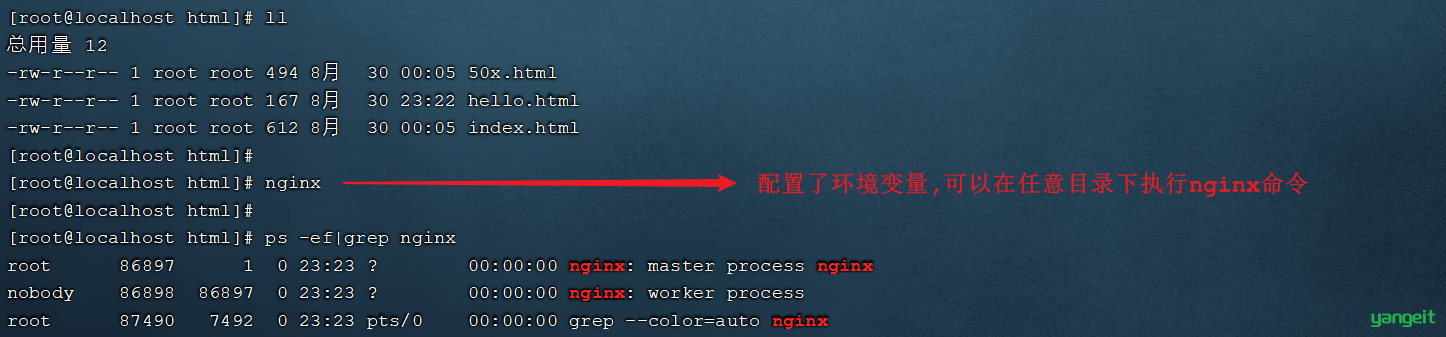

4). 配置首页

如果我们需要将hello.html作为nginx的首页,可以修改location的index指令,配置为hello.html,如下:

配置完毕后,我们可以通过指令,来检查配置文件是否配置正确: nginx -t

配置文件修改了,我们需要重新加载一下,才可以生效:
nginx -s reload

6.3 反向代理 🍐
6.3.1 概念介绍
问题
- 什么是反向代理?和正向代理的区别?
1). 正向代理
正向代理服务器是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。
正向代理的典型用途是为在防火墙内的局域网客户端提供访问Internet的途径。
正向代理一般是在客户端设置代理服务器,通过代理服务器转发请求,最终访问到目标服务器。
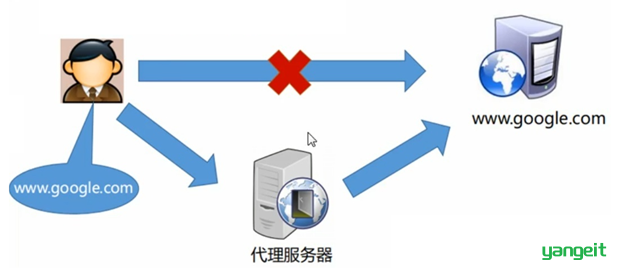
2). 反向代理
反向代理服务器位于用户与目标服务器之间,但是对于用户而言,反向代理服务器就相当于目标服务器,即用户直接访问反向代理服务器就可以获得目标服务器的资源,反向代理服务器负责将请求转发给目标服务器。用户不需要知道目标服务器的地址,也无须在用户端作任何设定,对于用户来说,访问反向代理服务器是完全无感知的。
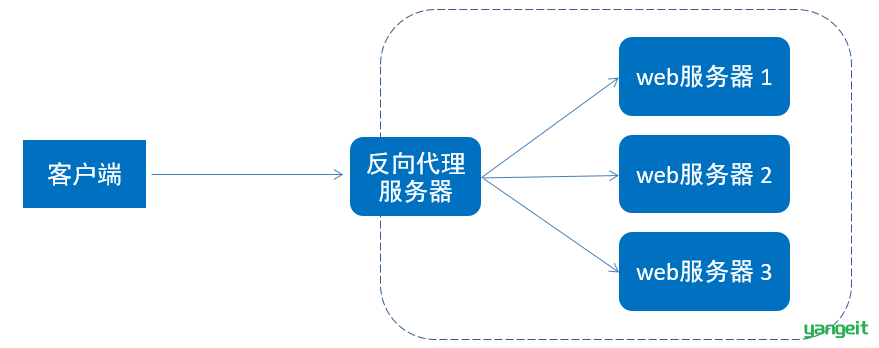
那么在本小节,我们就是要使用nginx来作为反向代理服务器使用。 在nginx中,我们可以在nginx.conf中配置反向代理:
server {
listen 82;
server_name localhost;
location / {
proxy_pass http://192.168.200.201:8080; #反向代理配置,将请求转发到指定服务
}
}
上述配置的含义为: 当我们访问nginx的82端口时,根据反向代理配置,会将请求转发到 http://192.168.200.201:8080 对应的服务上。
6.3.2 测试 ✏️
问题
- 为什么要使用反向代理?
需求: 在192.168.200.201这台服务器中部署了java应用,运行端口为8080,并提供了一个可访问的链接 /hello。现在我们需要在访问nginx的82端口时,通过nginx将请求转发到192.168.200.201:8080的服务。
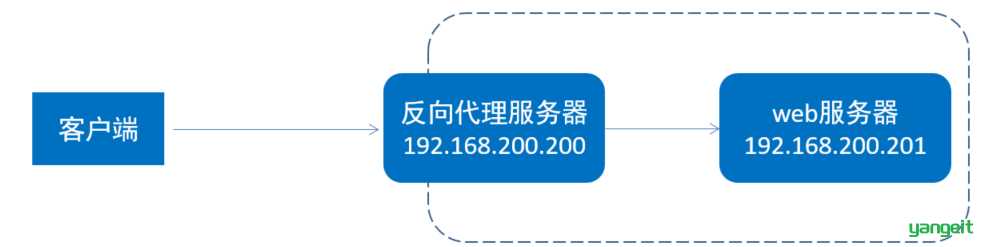
1). 在192.168.200.201部署服务并启动
将资料中提供的 helloworld-1.0-SNAPSHOT.jar 上传到服务器端,并通过指令 java -jar helloworld-1.0-SNAPSHOT.jar 运行服务。
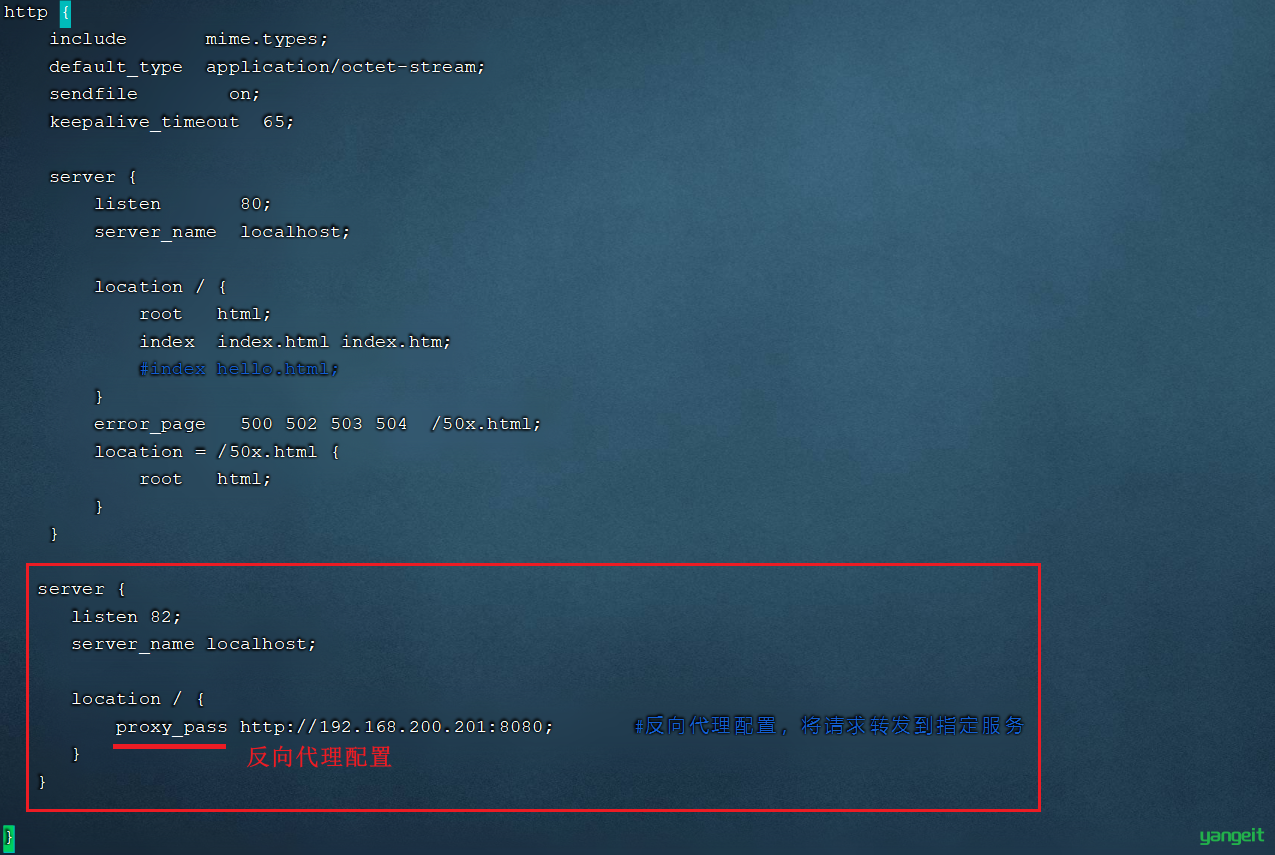
2). 在192.168.200.200中的nginx.conf中配置反向代理
进入nginx的安装目录,并编辑配置文件nginx.conf:
cd /usr/local/nginx/conf/
vim nginx.conf
在http块中,再添加一个server块虚拟主机的配置,监听82端口,并配置反向代理proxy_pass:
server {
listen 82;
server_name localhost;
location / {
proxy_pass http://192.168.31.134:8080; #反向代理配置,将请求转发到指定服务
}
}
3). 检查配置文件,并重新加载
nginx -t

nginx -s reload
4). 访问

注意: 在访问82端口时,有可能访问不通,原因是以为防火墙中没有开放端口号。我们可以通过两种方式来解决该问题:
A. 关闭防火墙
systemctl stop firewalld
B. 开发指定端口
firewall-cmd --zone=public --add-port=82/tcp --permanent
firewall-cmd --reload
6.4 负载均衡 🍐
6.4.1 概念介绍
问题
- 为什么要学习负载均衡?
早期的网站流量和业务功能都比较简单,单台服务器就可以满足基本需求,但是随着互联网的发展,业务流量越来越大并且业务逻辑也越来越复杂,单台服务器的性能及单点故障问题就凸显出来了,因此需要多台服务器组成应用集群,进行性能的水平扩展以及避免单点故障出现。
应用集群: 将同一应用部署到多台机器上,组成应用集群,接收负载均衡器分发的请求,进行业务处理并返回响应数据
负载均衡器: 将用户请求根据对应的负载均衡算法分发到应用集群中的一台服务器进行处理
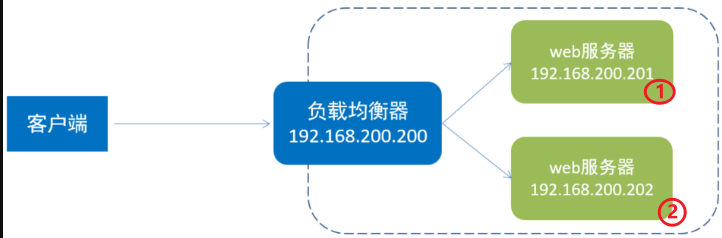
此处的负载均衡器,我们将会使用Nginx来实现,而Nginx的负载均衡是基于反向代理的,只不过此时所代理的服务器不是一台,而是多台。
6.4.2 测试
问题
- 负载均衡怎么配置?可以定义多少服务器?
1). 将资料中提供的两个jar包,上传到192.168.200.201服务器上
| jar | 运行端口 | 请求链接 | 响应数据 |
|---|---|---|---|
 | 8080 | /hello | 8080 |
 | 8081 | /hello | 8081 |
我们在测试时,并没有那么多服务器,我们可以在一台服务器中启动多个服务,运行在不同的端口号上进行测试。
2). 运行上传上来的两个jar包,运行端口分别是 8080 , 8081
由于我们执行 java -jar 指令会占用前台窗口,所以我们可以开启两个窗口进行测试。
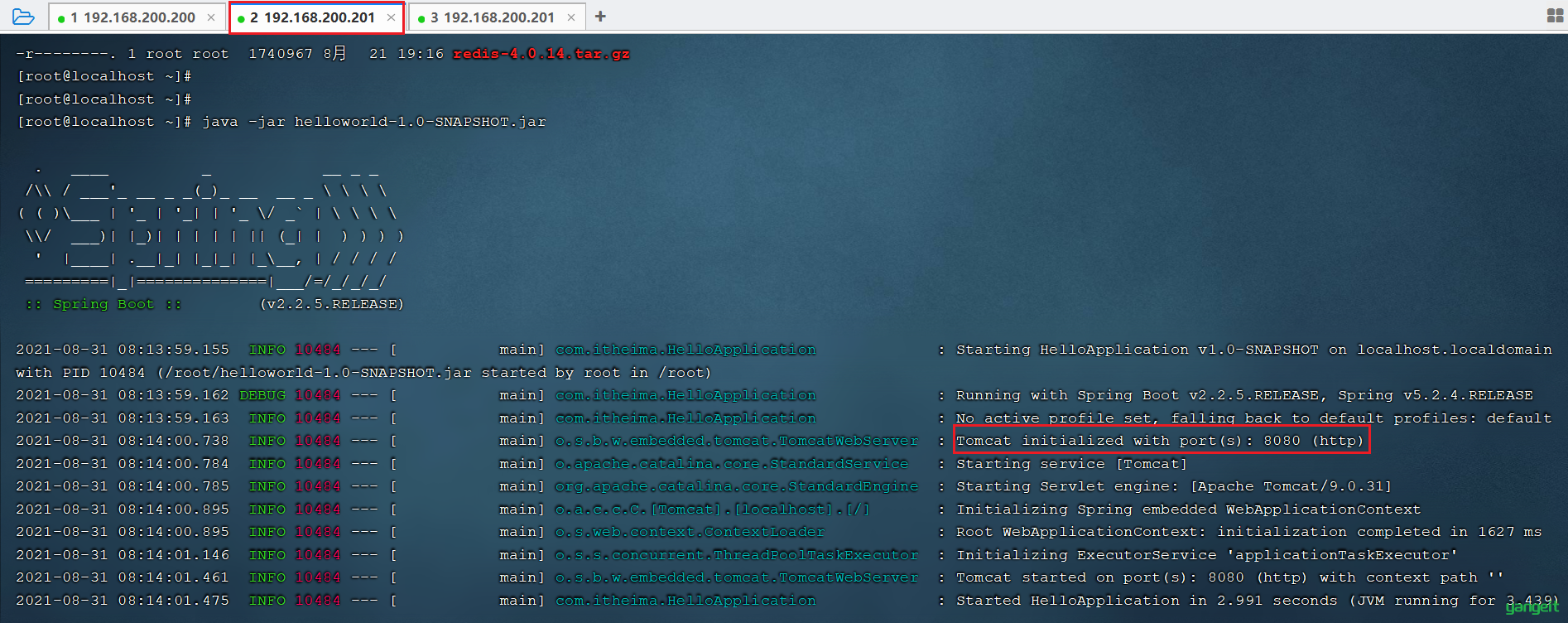
如果是win 直接运行以下指令 java -jar helloworld-1.0-SNAPSHOT.jar --server.port=8080 java -jar helloworld-1.0-SNAPSHOT2.jar --server.port=8081
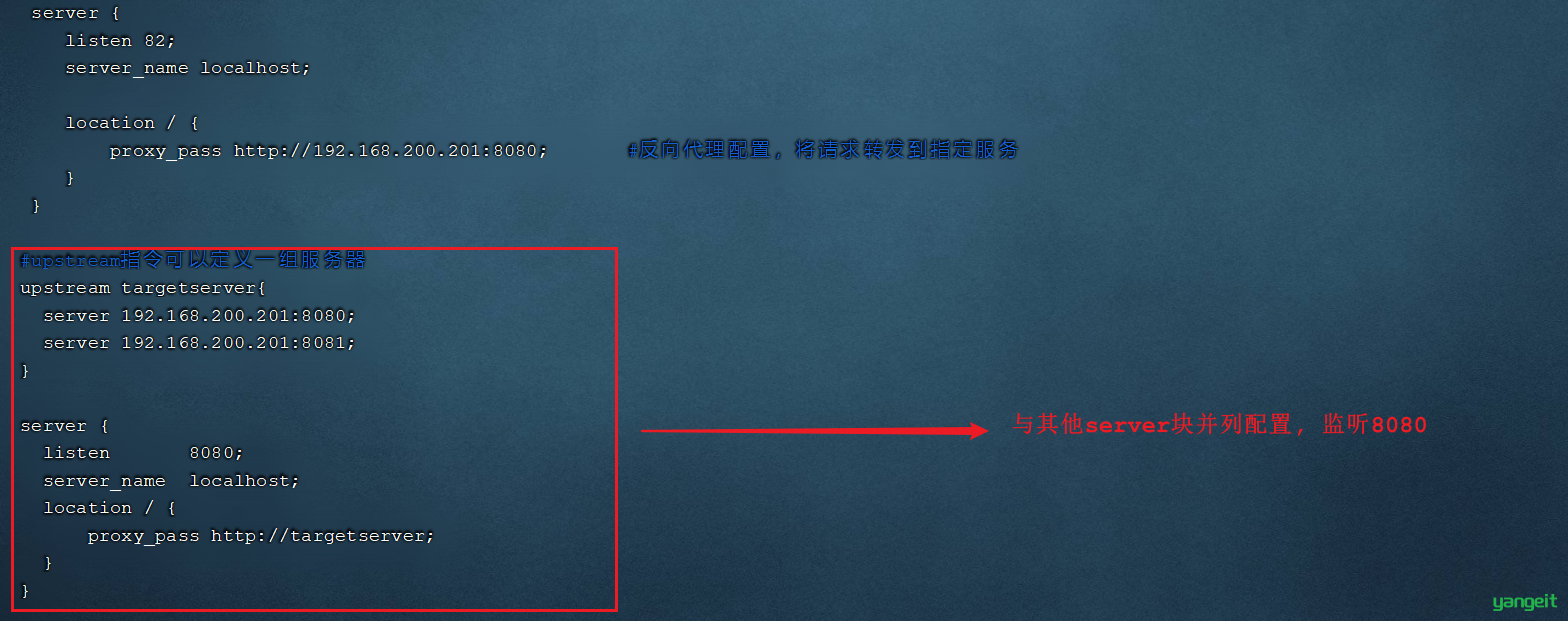
3). 在nginx中配置负载均衡
打开nginx的配置文件nginx.conf并增加如下配置:
upstream targetserver{
server 192.168.31.134:8080;
server 192.168.31.134:8081;
}
server {
listen 8080;
server_name localhost;
location / {
proxy_pass http://targetserver;
}
}
具体的配置位置如下:
4). 重新加载nginx配置文件,访问
nginx -s reload
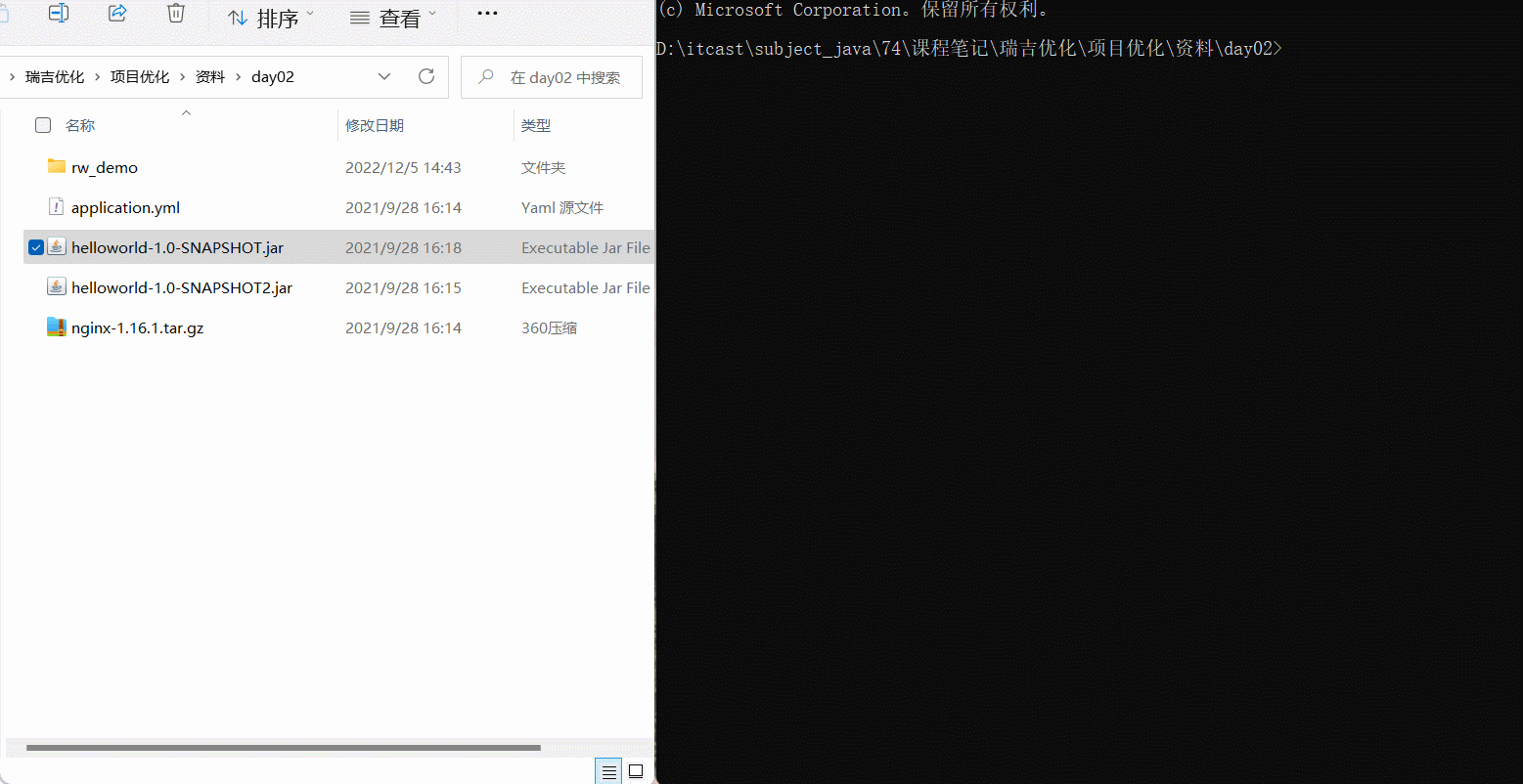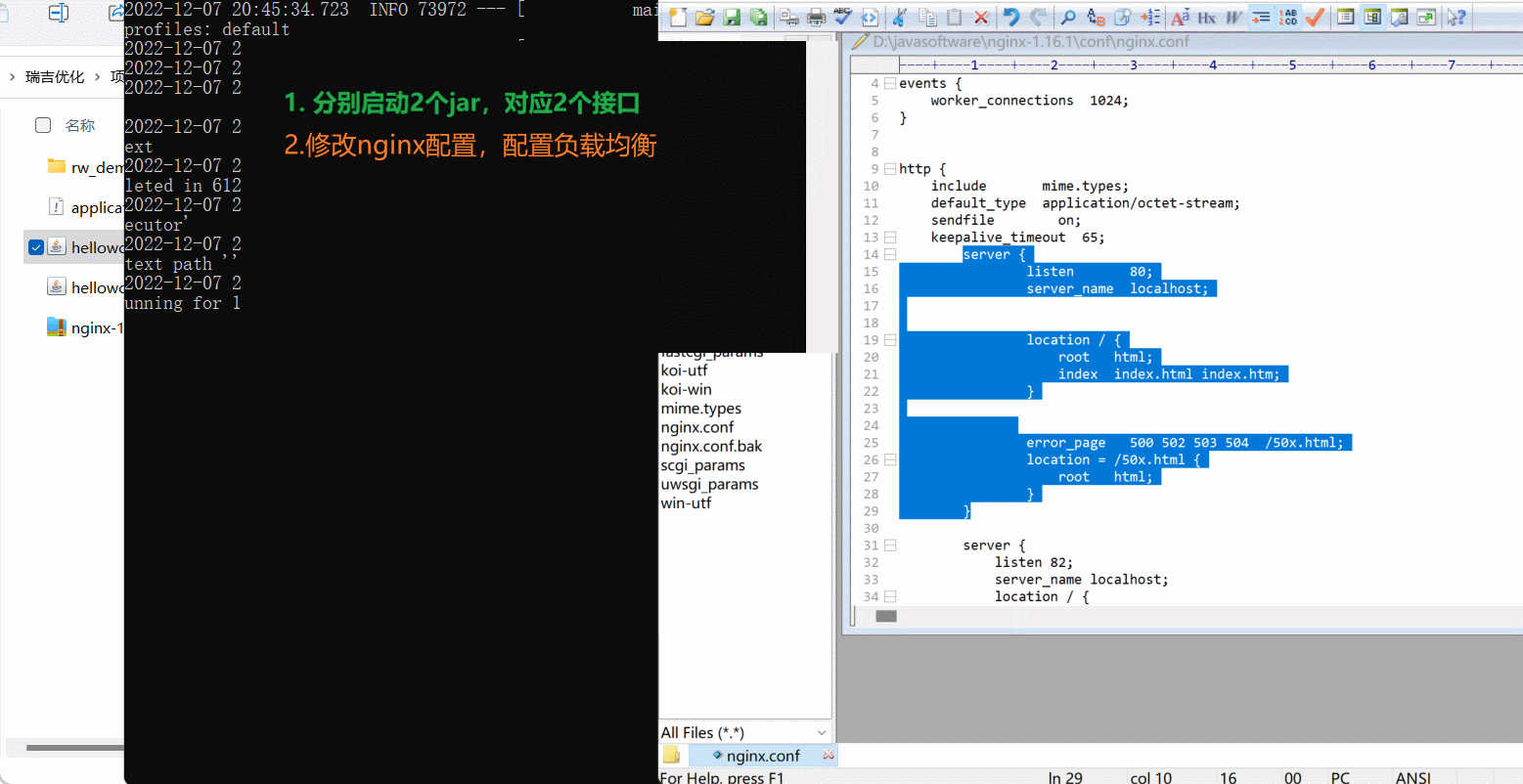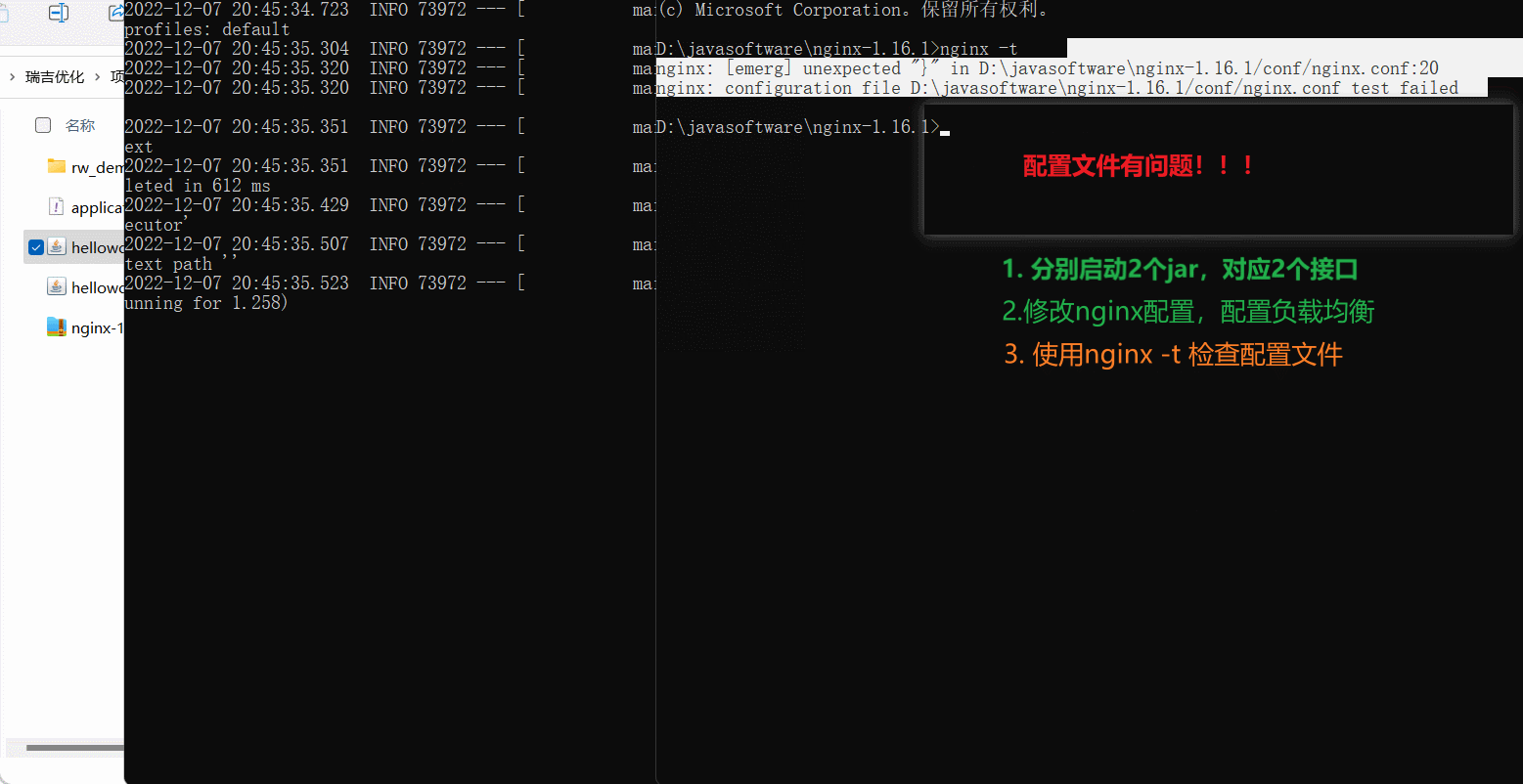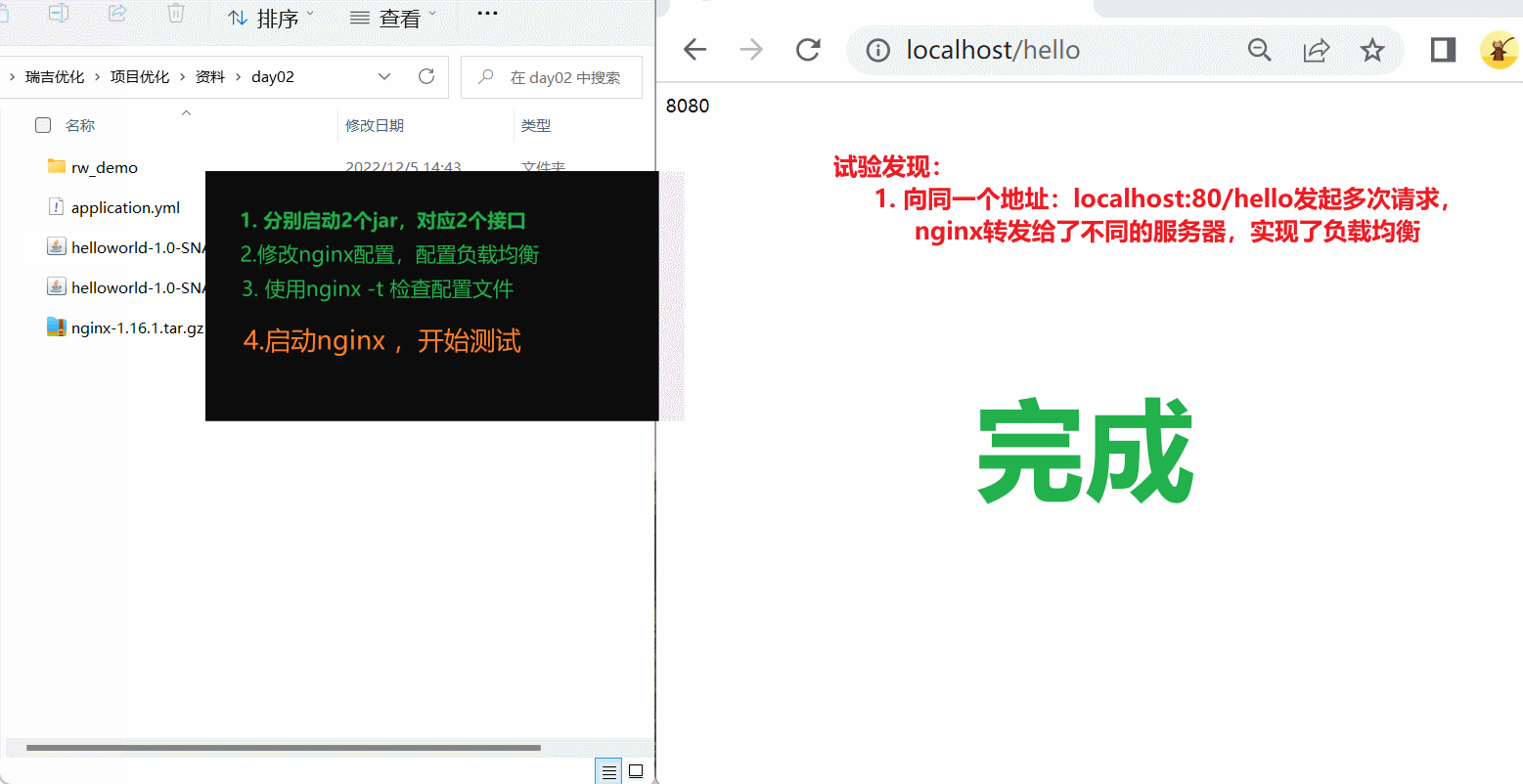
测试时,我们直接访问nginx的8080端口(http://192.168.200.200:8080), 此时nginx会根据负载均衡策略,将请求转发到后面的两台服务器。
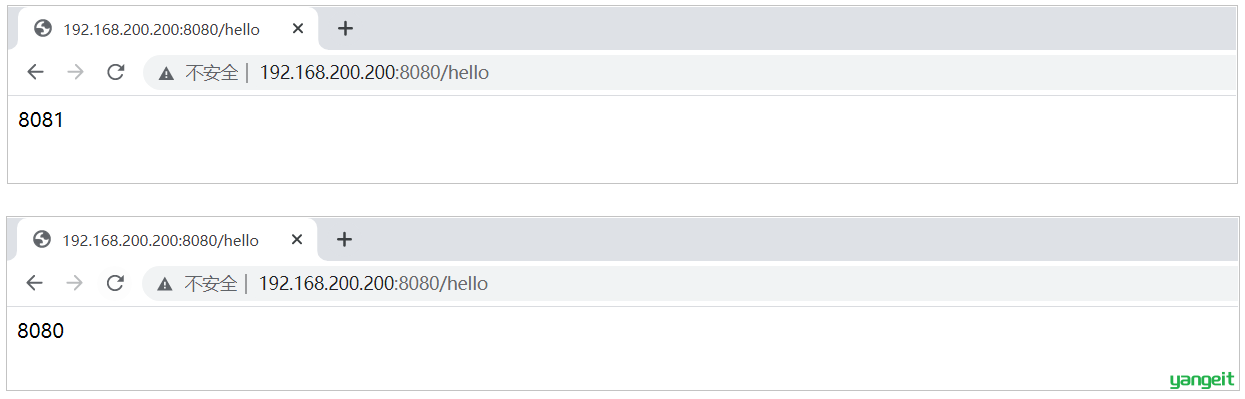
在上述的测试过程中,我们看到请求均衡的转发到了8080和8081,因为模式的负载均衡策略是轮询。
注意: 上述所有涉及到的端口号,都需要在对应的服务器的防火墙中开放,或者彻底关闭防火墙nginx负载均衡配置以及测试的gif动画教程 🎥
6.4.3 负载均衡策略
问题
- 负载均衡策略有哪些? 默认是什么?
处理上述默认的轮询策略以外,在Nginx中还提供了其他的负载均衡策略,如下:
| 名称 | 说明 | 特点 |
|---|---|---|
| 轮询 | 默认方式 | |
| 根据权重分发请求,权重大的分配到请求的概率大 | ||
| ip_hash | 依据ip分配方式 | 根据客户端请求的IP地址计算hash值, 根据hash值来分发请求, 同一个IP发起的请求, 会发转发到同一个服务器上 |
| least_conn | 依据最少连接方式 | 哪个服务器当前处理的连接少, 请求优先转发到这台服务器 |
| url_hash | 依据url分配方式 | 根据客户端请求url的hash值,来分发请求, 同一个url请求, 会发转发到同一个服务器上 |
| fair | 依据响应时间方式 | 优先把请求分发给处理请求时间短的服务器 |
权重的配置:
#upstream指令可以定义一组服务器
upstream targetserver{
server 192.168.200.201:8080 weight=10;
server 192.168.200.201:8081 weight=5;
}
上述配置的weight权重是相对的,在上述的配置中,效果就是,在大数据量的请求下,最终8080接收的请求数是8081的。