⼤盘板块功能实现
⼤盘板块功能实现
目标
- 🎯任务3:完善基于前后端分离⽤户验证码登录功能 🍐 ❤️✏️
- 理解前后端分离出现的问题和解决方案 🍐 🎤
- 熟悉验证码生成以及Redis集成
- 理解雪花算法的原理和影响因子 🍐 🎤
- 熟练使用接口测试工具
- 🎯任务4:掌握SwaggerUI使⽤并且在项目中集成✏️
- 🎯任务5:理解并实现国内⼤盘数据展示功能🍐✏️
- 理解SQL优化措施 🍐 🎤
- 🎯任务6:理解并实现国内板块数据展示功能🍐✏️
1. 验证码登录功能 🎯
1.1 前后端分离状态识别问题
前后端分离状态识别问题
1️⃣ 前后端分离存在的问题
单体架构基于session-cookie机制实现验证码流程:
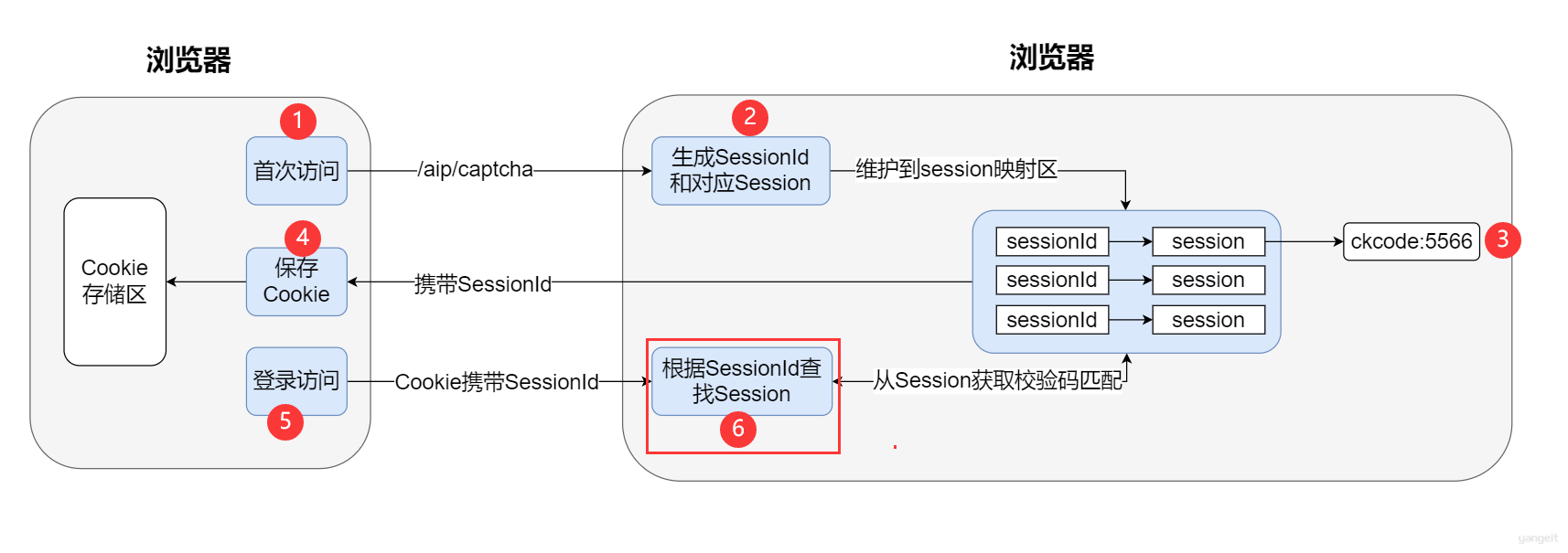
对于前后端分离的架构会存在
跨域问题,这会导致请求⽆法携带Cookie,⽽Session机制是基于Cookie的,所以会导致session失效 ;同时对于后端服务后期如果要搭建集群,则还需要解决单点session共享的问题;
2️⃣ 解决Session和Cookie失效问题
cookie失效问题
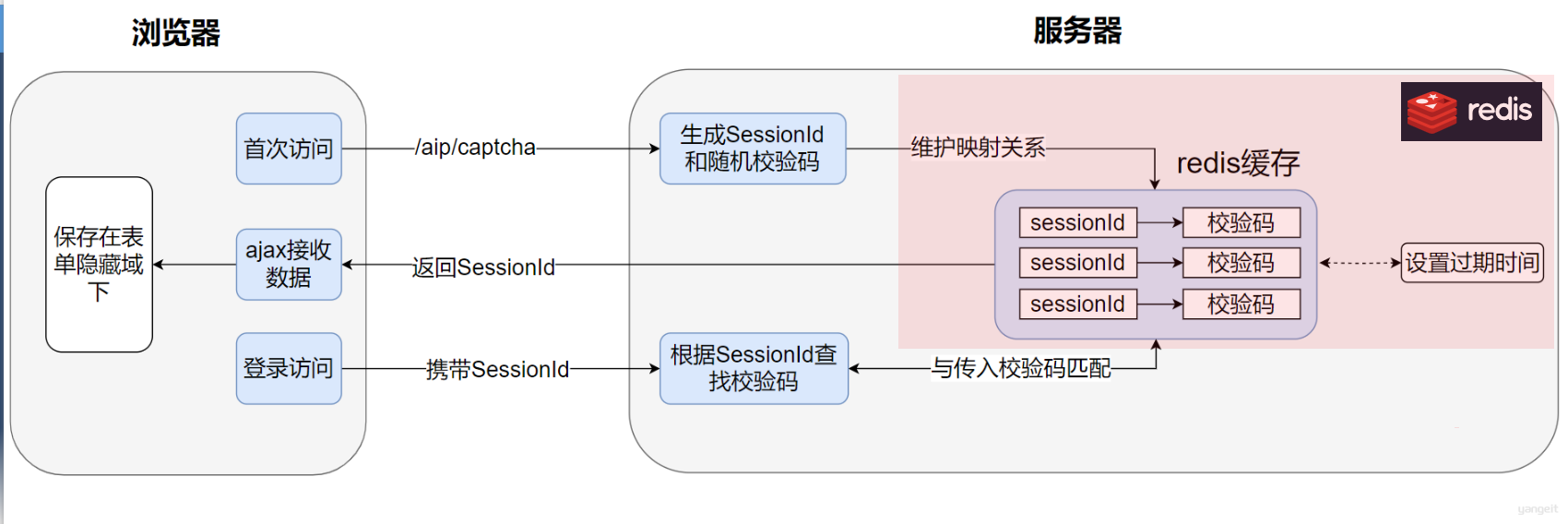
- 可在
后端⽣成⼀个sessionId,并将sessionId作为key,校验码作为value保存在redis下(redis代替session),之后借鉴cookie思路再将sessionId作为参数响应给前端;
- 可在
Session过期失效问题
- 我们借助
redis的过期失效机制来模拟Session过期失效的⾏为;
- 我们借助
课间作业
- 根据上述的问题,你能清晰的口述
cookie失效问题以及Session过期失效问题的解决方案吗?
1.2 验证码功能
验证码功能
我们可使⽤分布式缓存redis模拟session机制,实现验证码的⽣成和校验功能,核⼼流程如下:
注意事项: 需要保证 SessionId的唯⼀性,否则可能会出现⽤户输⼊了正确的校验码,但是依旧可能会校验失败的问题;
- 功能描述:
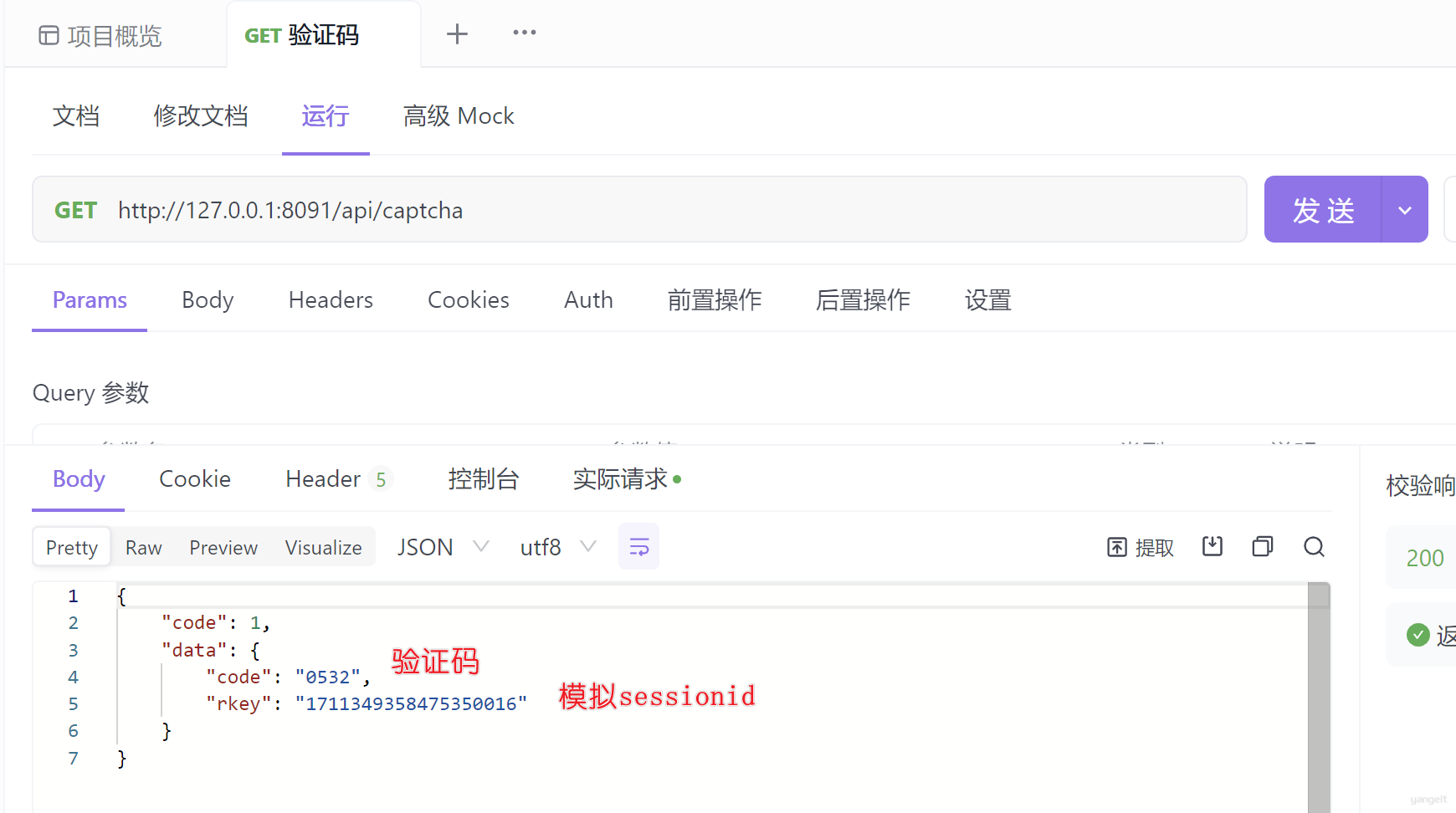
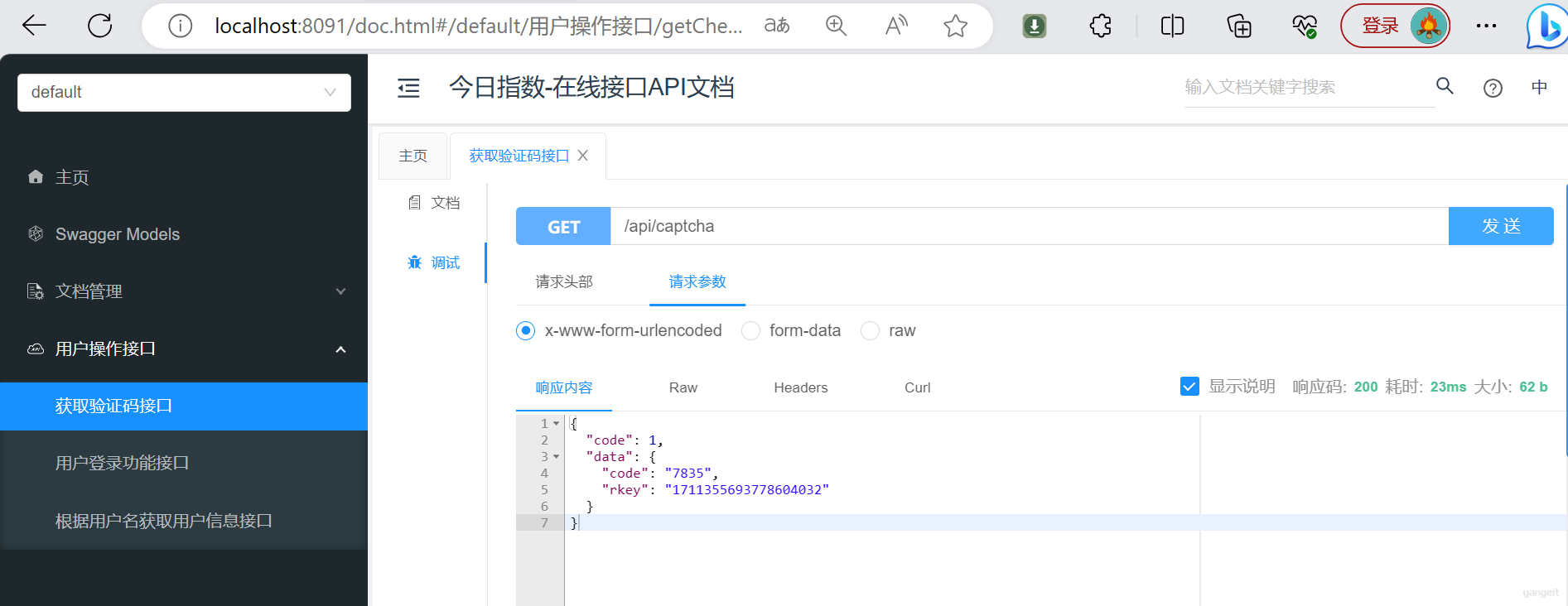
验证码⽣成功能 - 请求路径:
/api/captcha - 请求参数:
⽆ - 请求⽅式:
get - 响应数据格式:
{
"code": 1,
"data": {
"code": "1342",
"rkey": "1479063316897845248" //保存在redis中验证码对应的key,模拟sessionId
}
}
前端展示效果: 👇
image
准备工作代码操作
根据左边的需求描述和接口需求,可知接下来工作如下:
- 项目集成Redis解决cookie失效问题
- 定义常量类
- 保证sessionId的唯一性保证用户请求-验证码的唯一对应
- 验证码生成
1️⃣ 在stock_backend⼯程引⼊redis相关依赖:
<!--redis场景依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- redis创建连接池,默认不会创建连接池 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
2️⃣ 定义application-cache.yml⽂件专⻔配置缓存信息业务分离,方便维护:
spring:
# 配置缓存
redis:
host: 192.168.188.130
port: 6379
database: 0 #Redis数据库索引(默认为0)
lettuce:
pool:
max-active: 8 # 连接池最⼤连接数(使⽤负值表示没有限制)
max-wait: -1ms # 连接池最⼤阻塞等待时间(使⽤负值表示没有限制)
max-idle: 8 # 连接池中的最⼤空闲连接
min-idle: 1 # 连接池中的最⼩空闲连接
timeout: PT10S # 连接超时时间
说明:由于application主配置⽂件在后续会写⼊很多其它配置信息,这会导致主配置臃肿难以维护,所以我们把不同的信息独⽴配置,这样就降低了维护成本;
如:
application-cache.yml负责缓存配置如:
application-database.yml负责数据库配置
3️⃣ 在主配置⽂件中application.yml激活配置:
spring:
datasource:
----省略----
profiles:
active: cache # 激活|加载其它配置资源,如果还有其他的,可以使用,隔开
4️⃣ ⾃定义RedisTemplate序列化:
@Configuration
public class RedisCacheConfig {
/**
* 配置redisTemplate bean,⾃定义数据的序列化的⽅式
* @param redisConnectionFactory 连接redis的⼯⼚,底层有
场景依赖启动时,⾃动加载
* @return
*/
@Bean
public RedisTemplate redisTemplate(@Autowired RedisConnectionFactory redisConnectionFactory){
//1.构建RedisTemplate模板对象
RedisTemplate<String, Object> template = newRedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
//2.为不同的数据结构设置不同的序列化⽅案
//设置key序列化⽅式
template.setKeySerializer(new StringRedisSerializer());
//设置value序列化⽅式
template.setValueSerializer(new Jackson2JsonRedisSerializer<>(Object.class));
//设置hash中field字段序列化⽅式
template.setHashKeySerializer(new StringRedisSerializer());
//设置hash中value的序列化⽅式
template.setHashValueSerializer(new Jackson2JsonRedisSerializer<>(Object.class));
//5.初始化参数设置
template.afterPropertiesSet();
return template;
}
}
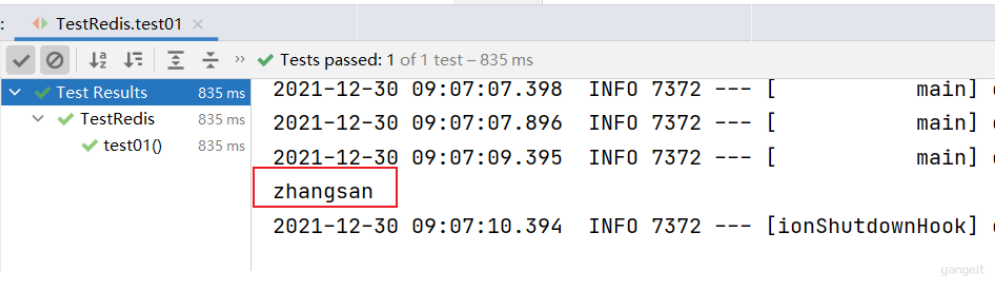
5️⃣ 测试redis基础环境:
@SpringBootTest
public class TestRedis {
@Autowired
private RedisTemplate<String,String> redisTemplate;
@Test
public void test01(){
redisTemplate.opsForValue().set("myname","zhangsan");
//获取值
String myname = redisTemplate.opsForValue().get("myname");
System.out.println(myname);
}
}
效果:
项⽬中⼀些业务经常会使⽤⼀些常量字段,开发者⼀般会将这些业务相关的常量信息封装到⼀个常量类中统⼀维护;
举例:在redis中为了⽅便维护⽤户登录校验码信息,我们可为key配置⼀个业务前缀,⽐如CK:12312323->6677,这样后期开发和运维⼈员就会很⽅便的查找出以CK开头的验证码信息了;
作为公共的常量信息类,我们就将它封装到stock_common⼯程下即可:
package com.itheima.stock.constant;
public class StockConstant {
/**
* 定义校验码的前缀
*/
public static final String CHECK_PREFIX="CK:";
/**
* http请求头携带Token信息key
*/
public static final String TOKEN_HEADER = "authorization";
/**
* 缓存股票相关信息的cacheNames命名前缀
*/
public static final String STOCK="stock";
}
- 在stock_backend⼯程引⼊图⽚验证码⽣成⼯具包
<!--hutool万能⼯具包-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
</dependency>
- 书写测试类,测试验证码和图片的Base64格式生成
String checkCode = captcha.getCode();
log.info("⽣成校验码:{}",checkCode);
//⽣成sessionId
String sessionId =
String.valueOf(idWorker.nextId());
//将sessionId和校验码保存在redis下,并设置缓存中数据存活时间⼀分钟
redisTemplate.opsForValue().set(StockConstant.CHECK_PREFIX+sessionId,checkCode,1, TimeUnit.MINUTES);
1️⃣ 雪花算法介绍
后台⽣成SessionId需要
保证全局唯⼀,我们可借鉴SnowFlake(雪花算法)来实现;
什么是雪花算法?
- ❄️雪花算法是
Twitter公司内部为分布式环境下⽣成唯⼀ID的⼀种算法解决⽅案,底层会帮助我们⽣成⼀个64位(⽐特位)的long类型的Id;

👉概括:什么样的机房下的哪台机器,在什么时间点生成的唯一ID,如果在这个时间点上还有并发,那么就搞一些序列号,这样能保证生产的ID唯一性。
2️⃣ 导⼊雪花算法工具类
各种开发语⾔都有对雪花算法的实现,不需要自行实现,直接导入现成的工具类即可。
- 在
stock_common⼯程中引⼊已写好的⼯具类即可:点击下方的折叠的雪花算法工具类
- 在
stock_backend⼯程配置ID⽣成器bean对象:
@Configuration
public class CommonConfig {
/**
* 配置id⽣成器bean
* @return
*/
@Bean
public IdWorker idWorker(){
//基于运维⼈员对机房和机器的编号规划⾃⾏约定
return new IdWorker(1l,2l);
}
......
}
至此,我们的准备工作完毕,现在可以写验证码的接口了 ✏️ 👇
点击查看雪花算法工具类
package com.sharding.hint.utils;
import java.lang.management.ManagementFactory;
import java.net.InetAddress;
import java.net.NetworkInterface;
/**
* <p>名称:IdWorker.java</p>
* <p>描述:分布式自增长ID</p>
* <pre>
* Twitter的 Snowflake JAVA实现方案
* </pre>
* 核心代码为其IdWorker这个类实现,其原理结构如下,我分别用一个0表示一位,用—分割开部分的作用:
* 1||0---0000000000 0000000000 0000000000 0000000000 0 --- 00000 ---00000 ---000000000000
* 在上面的字符串中,第一位为未使用(实际上也可作为long的符号位),接下来的41位为毫秒级时间,
* 然后5位datacenter标识位,5位机器ID(并不算标识符,实际是为线程标识),
* 然后12位该毫秒内的当前毫秒内的计数,加起来刚好64位,为一个Long型。
* 这样的好处是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和机器ID作区分),
* 并且效率较高,经测试,snowflake每秒能够产生26万ID左右,完全满足需要。
* <p>
* 64位ID (42(毫秒)+5(机器ID)+5(业务编码)+12(重复累加))
*
* @author Polim
*/
public class IdWorker {
// 时间起始标记点,作为基准,一般取系统的最近时间(一旦确定不能变动)
private final static long twepoch = 1288834974657L;
// private final static long twepoch = 1457258545962L;
// 机器标识位数
private final static long workerIdBits = 5L;
// 数据中心标识位数
private final static long datacenterIdBits = 5L;
// 机器ID最大值
private final static long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 数据中心ID最大值
private final static long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// 毫秒内自增位
private final static long sequenceBits = 12L;
// 机器ID偏左移12位
private final static long workerIdShift = sequenceBits;
// 数据中心ID左移17位
private final static long datacenterIdShift = sequenceBits + workerIdBits;
// 时间毫秒左移22位
private final static long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private final static long sequenceMask = -1L ^ (-1L << sequenceBits);
/* 上次生产id时间戳 */
private static long lastTimestamp = -1L;
// 0,并发控制
private long sequence = 0L;
private final long workerId;
// 数据标识id部分
private final long datacenterId;
public IdWorker(){
this.datacenterId = getDatacenterId(maxDatacenterId);
this.workerId = getMaxWorkerId(datacenterId, maxWorkerId);
}
/**
* @param workerId
* 工作机器ID
* @param datacenterId
* 序列号
*/
public IdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获取下一个ID
*
* @return
*/
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
// 当前毫秒内,则+1
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
// 当前毫秒内计数满了,则等待下一秒
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = timestamp/2;
}
lastTimestamp = timestamp;
// ID偏移组合生成最终的ID,并返回ID
long nextId = ((timestamp - twepoch) << timestampLeftShift)
| (datacenterId << datacenterIdShift)
| (workerId << workerIdShift) | sequence;
return nextId;
}
private long tilNextMillis(final long lastTimestamp) {
long timestamp = this.timeGen();
while (timestamp <= lastTimestamp) {
timestamp = this.timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
/**
* <p>
* 获取 maxWorkerId
* </p>
*/
protected static long getMaxWorkerId(long datacenterId, long maxWorkerId) {
StringBuffer mpid = new StringBuffer();
mpid.append(datacenterId);
String name = ManagementFactory.getRuntimeMXBean().getName();
if (!name.isEmpty()) {
/*
* GET jvmPid
*/
mpid.append(name.split("@")[0]);
}
/*
* MAC + PID 的 hashcode 获取16个低位
*/
return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
}
/**
* <p>
* 数据标识id部分
* </p>
*/
protected static long getDatacenterId(long maxDatacenterId) {
long id = 0L;
try {
InetAddress ip = InetAddress.getLocalHost();
NetworkInterface network = NetworkInterface.getByInetAddress(ip);
if (network == null) {
id = 1L;
} else {
byte[] mac = network.getHardwareAddress();
id = ((0x000000FF & (long) mac[mac.length - 1])
| (0x0000FF00 & (((long) mac[mac.length - 2]) << 8))) >> 6;
id = id % (maxDatacenterId + 1);
}
} catch (Exception e) {
System.out.println(" getDatacenterId: " + e.getMessage());
}
return id;
}
}
🎯验证码接口书写
往上翻查看验证码接口
在UserController接⼝定义访问⽅法:
/**
* ⽣成登录校验码的访问接⼝
* @return
*/
@GetMapping("/captcha")
public R<Map> getCaptchaCode(){
return userService.getCaptchaCode();
}
定义⽣成验证码服务
- 在UserService服务接⼝:
/**
* 登录校验码⽣成服务⽅法
* @return
*/
R<Map> getCaptchaCode();
- 🎯在UserServiceImpl服务实现类中书写逻辑✏️
参考答案点击这里查看(需要密码)👈不要轻易点击哦
完善验证码登录功能
代码操作
完善登录请求VO
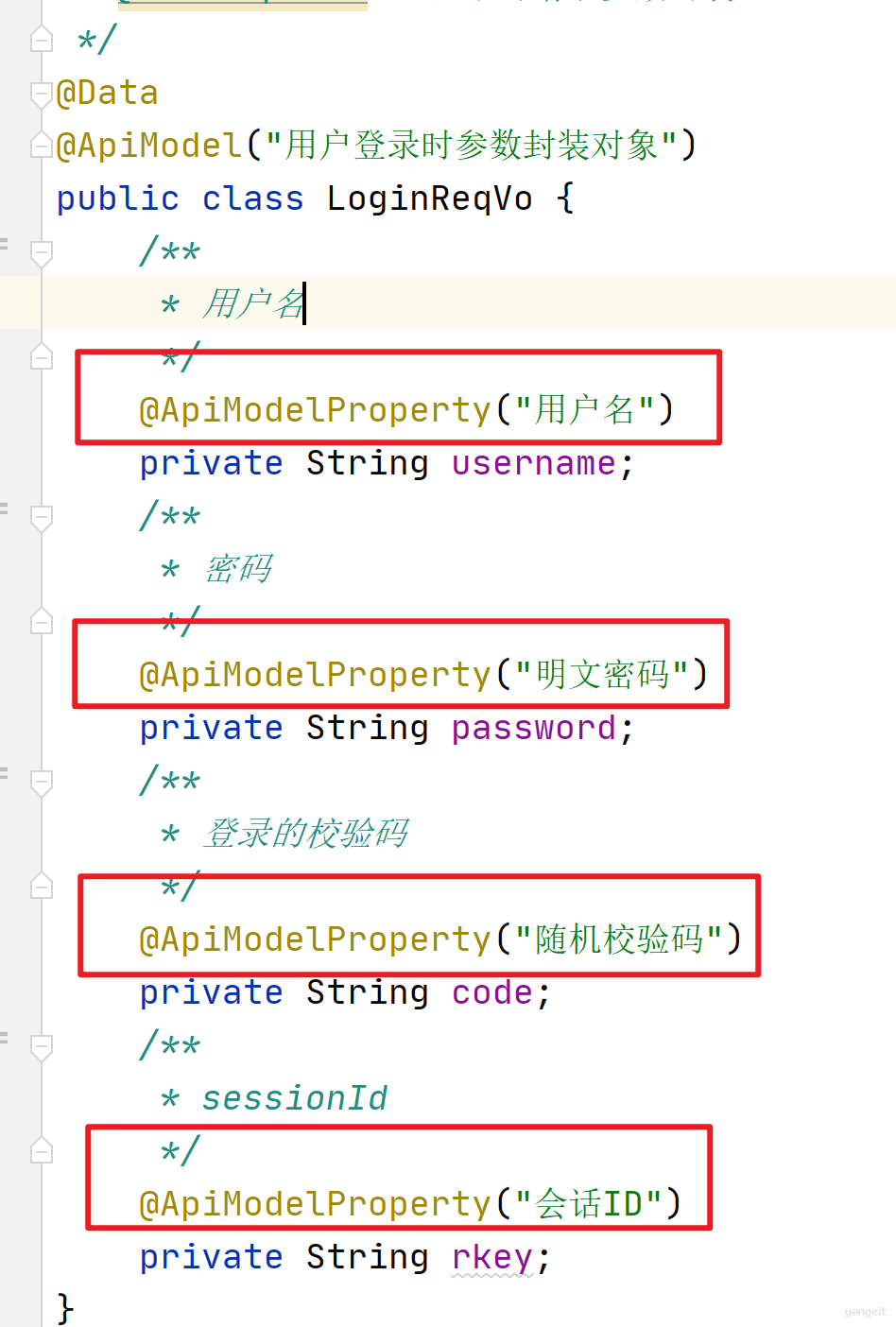
LoginReqVo添加sessionId属性:
@Data
public class LoginReqVo {
/**
* 用户名
*/
private String username;
/**
* 密码
*/
private String password;
/**
* 登录的校验码
*/
private String code;
/**
* 模拟sessionId
*/
private String rkey;
}
在stock_backend⼯程中的UserServiceImpl完善登录验证码逻辑
@Service("userService")
public class UserServiceImpl implements UserService {
@Autowired
private SysUserMapper sysUserMapper;
@Autowired
private PasswordEncoder passwordEncoder;
@Autowired
private IdWorker idWorker;
@Autowired
private RedisTemplate redisTemplate;
/**
* 根据用户名查询用户信息
* @param userName
* @return
*/
@Override
public SysUser getUserByUserName(String userName) {
return sysUserMapper.getUserByUserName(userName);
}
/**
* 用户登录功能
* @param reqVo
* @return
*/
@Override
public R<LoginRespVo> login(LoginReqVo reqVo) {
//判断输入参数的合法性
if (reqVo==null ||
StringUtils.isBlank(reqVo.getUsername()) ||
StringUtils.isBlank(reqVo.getPassword())) {
return R.error(ResponseCode.USERNAME_OR_PASSWORD_ERROR);
}
....自己敲....
return R.ok(respVo);
}
@Override
public R<Map> getCheckCode() {
....自己敲....
}
}
参考答案点击这里查看(需要密码)👈不要轻易点击哦
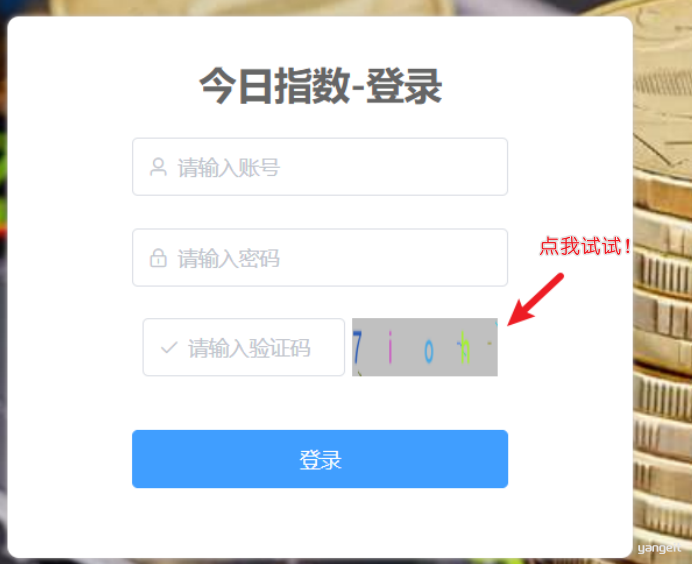
登录测试联调
2.接口文档管理工具 🎯
2.1 Swagger和knife4j介绍
Swagger和knife4j介绍

Swagger 是⼀个规范和完整的Web API框架,⽤于⽣成、描述、调⽤和可视化 RESTful ⻛格的 Web 服务。
功能主要包含以下⼏点:
- A. 使得前后端分离开发更加⽅便,有利于团队协作;
- B. 接⼝⽂档在线⾃动⽣成,降低后端开发⼈员编写接⼝⽂档的负担;
- C. 接⼝功能测试;
使⽤Swagger只需要按照它的规范去定义接⼝及接⼝相关的信息,再通过Swagger衍⽣出来的⼀系列项⽬和⼯具,就可以做到⽣成各种格式的接⼝⽂档,以及在线接⼝调试⻚⾯等等;
knife4j是为Java MVC框架集成Swagger⽣成Api⽂档的增强解决⽅案,前身是swagger-bootstrap-ui,取名kni4j是希望它能像⼀把⼔⾸⼀样⼩巧,轻量,并且功能强悍
- gitee地址:https://gitee.com/xiaoym/knife4j
- 官⽅⽂档:https://doc.xiaominfo.com/
- 效果演示:http://knife4j.xiaominfo.com/doc.html
核⼼功能:
- 该UI增强包主要包括两⼤核⼼功能:⽂档说明 和 在线调试
⽂档说明:根据Swagger的规范说明,详细列出接⼝⽂档的说明,包括接⼝地址、类型、请求示例、请求参数、响应示例、响应参数、响应码等信息,使⽤swagger-bootstrap-ui能根据该⽂档说明,对该接⼝的使⽤情况⼀⽬了然。
在线调试:提供在线接⼝联调的强⼤功能,⾃动解析当前接⼝参数,同时包含表单验证,调⽤参数可返回接⼝响应内容、headers、Curl请求命令实例、响应时间、响应状态码等信息,帮助开发者在线调试,⽽不必通过其他测试⼯具测试接⼝是否正确,简介、强⼤。
集成Knife4j代码操作
在stock_common⼯程添加依赖
<!--knife4j的依赖-->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-spring-boot-starter</artifactId>
<version>2.0.2</version>
</dependency>
<!--⽀持接⼝参数校验处理-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
在swagger配置类添加knife4j配置:
package com.itheima.stock.config;
@Configuration
@EnableSwagger2
@EnableKnife4j
@Import(BeanValidatorPluginsConfiguration.class)
public class SwaggerConfiguration {
@Bean
public Docket buildDocket() {
//构建在线API概要对象
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(buildApiInfo())
.select()
// 要扫描的API(Controller)基础包
.apis(RequestHandlerSelectors.basePackage("com.itheima.stock.web"))
.paths(PathSelectors.any())
.build();
}
private ApiInfo buildApiInfo() {
//网站联系方式
Contact contact = new Contact("黑马程序员","https://www.itheima.com/","itcast@163.com");
return new ApiInfoBuilder()
.title("今日指数-在线接口API文档")
.description("这是一个方便前后端开发人员快速了解开发接口需求的在线接口API文档")
.contact(contact)
.version("1.0.0").build();
}
}
@EnableSwagger2 该注解是Springfox-swagger框架提供的使⽤Swagger注解,该注解必须加
@EnableKnife4j 该注解是knife4j提供的增强注解,Ui提供了例如动态参数、参数过滤、接⼝排序等增强功能,如果你想使⽤这些增强功能就必须加该注解,否则可以不⽤加
在Controller等类配置注解
@RestController
@RequestMapping("/api")
@Api(value = "⽤户认证相关接⼝定义",tags = "⽤户功能-⽤户登录功能")
public class UserController {
/**
* 注⼊⽤户服务bean
*/
@Autowired
private UserService userService;
/**
* 根据⽤户名查询⽤户信息
* @param userName
* @return
*/
@GetMapping("/{userName}")
@ApiOperation(value = "根据⽤户名查询⽤户信息",notes ="⽤户信息查询",response = SysUser.class)
@ApiImplicitParam(paramType = "path",name ="userName",value = "⽤户名",required = true)
public SysUser getUserByUserName(@PathVariable("userName") String userName){
return userService.getUserByUserName(userName);
}
/**
* ⽤户登录功能接⼝
* @param vo
* @return
*/
@PostMapping("/login")
@ApiOperation(value = "⽤户登录功能",notes = "⽤户登录",response = R.class)
public R<LoginRespVo> login(@RequestBody LoginReqVo vo)
{
return userService.login(vo);
}
/**
* ⽣成登录校验码的访问接⼝
* @return
*/
@GetMapping("/captcha")
@ApiOperation(value = "验证码⽣成功能",response =R.class)
public R<Map> getCaptchaCode(){
return userService.getCaptchaCode();
}
}
将登录封装对象LoginReqVo也进行添加注解
2.2 ApiFox介绍和安装以及数据同步
ApiFox

假设一种场景: 程序员忙活一天,写了4个接口,这时候通过swagger测试,还要手动的录入到Apifox接口管理平台中,是不是增加了工作量,能不能接口代码写完后,Apifox自动就同步了尼?
ApiFox同步Swaager代码操作
- 配置自动导入
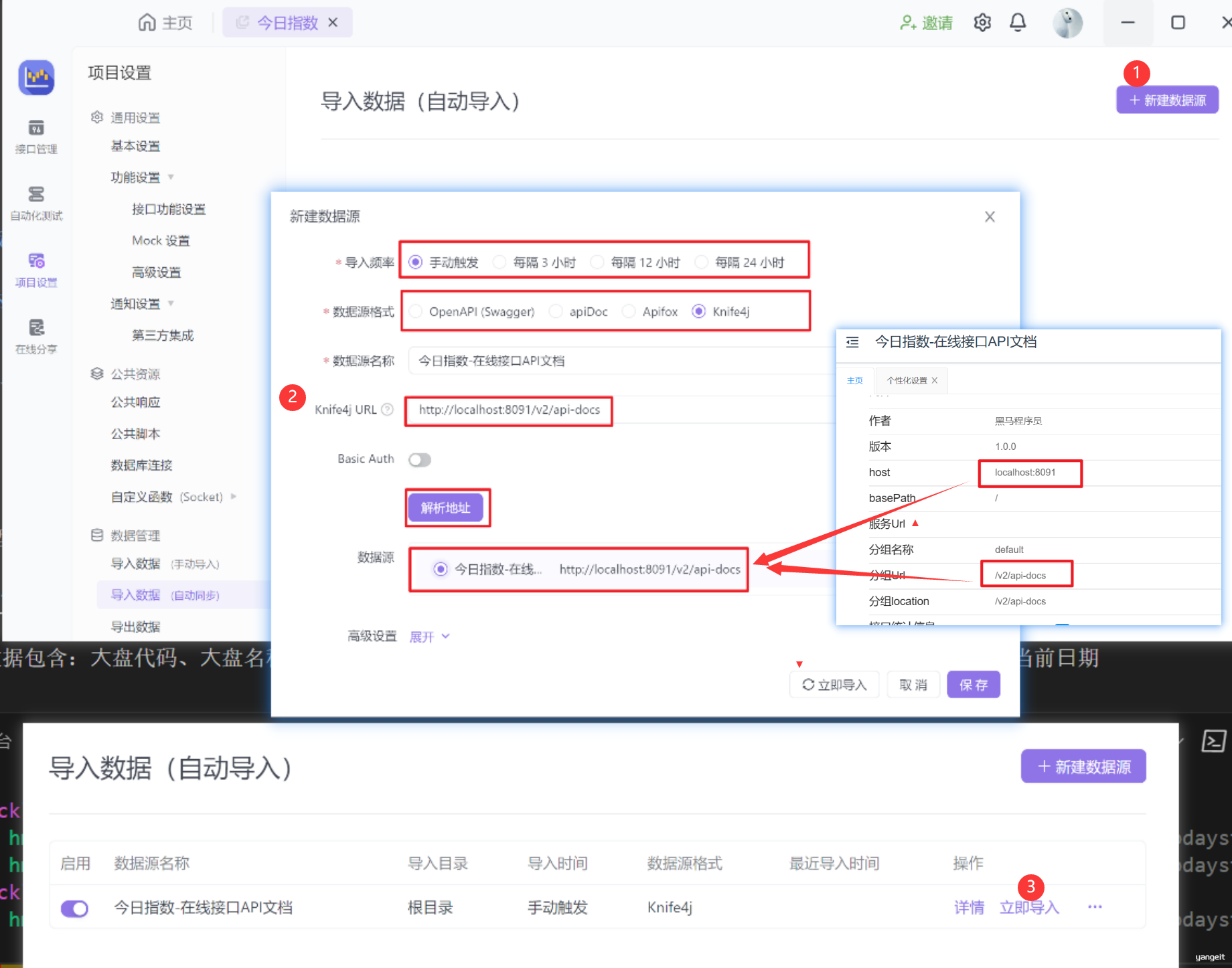
- 开始自动导入
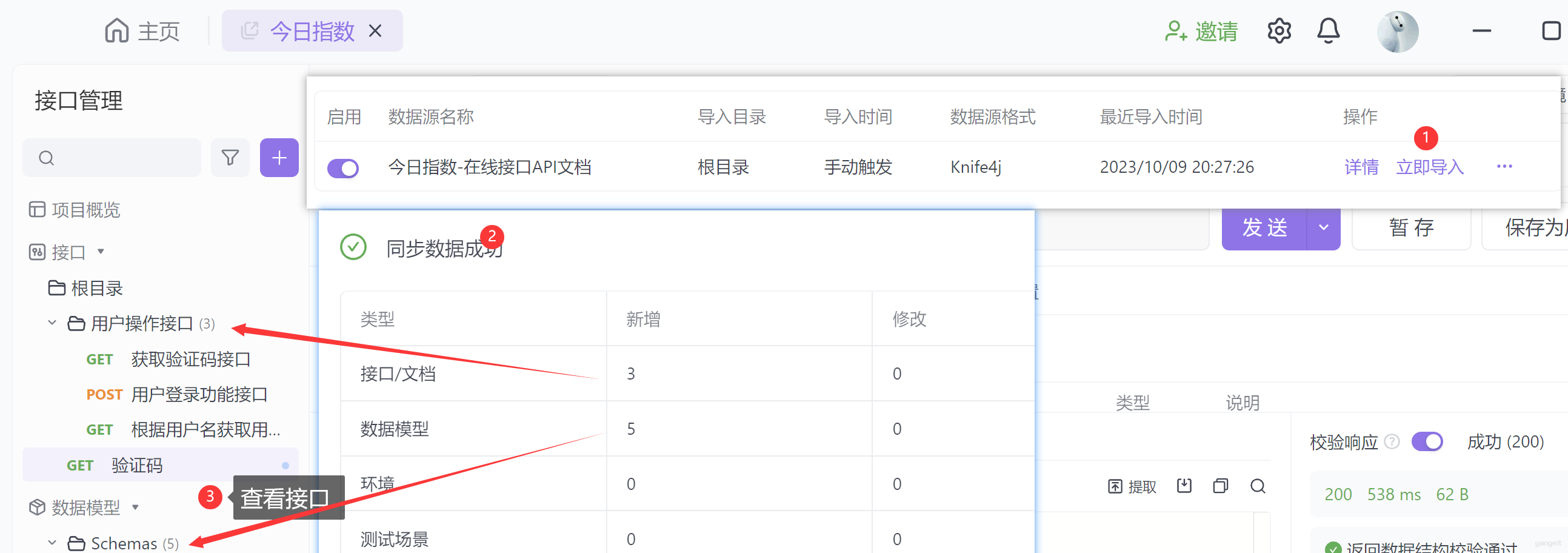
3. 大盘板块
3.1 国内⼤盘指数功能 🎯
前言
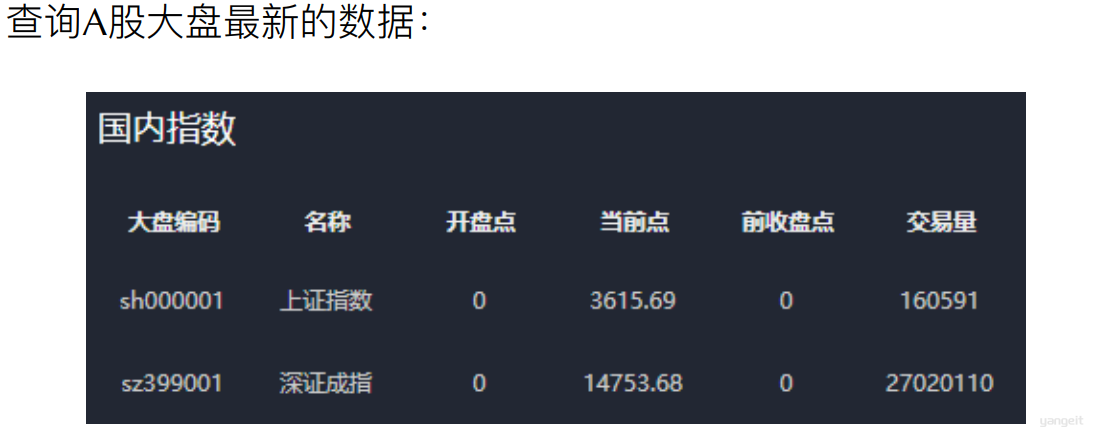
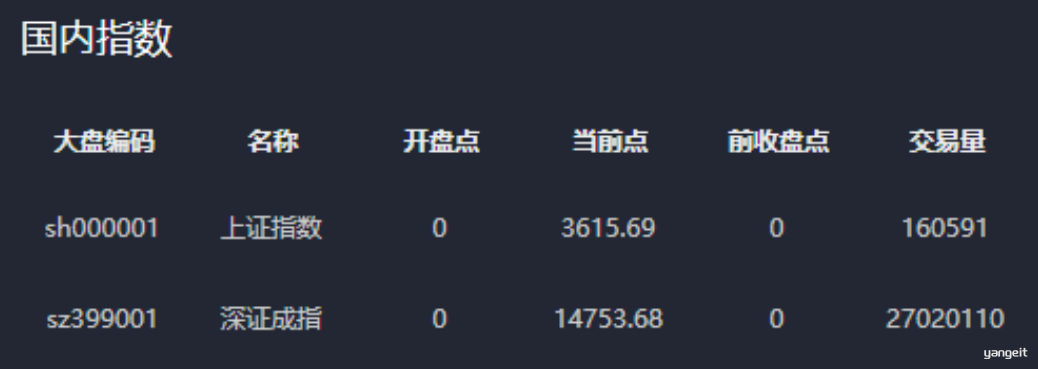
国内⼤盘数据包含:⼤盘代码、⼤盘名称、开盘点、最新点、前收盘点、交易量、交易⾦额、涨跌值、涨幅、振幅、当前⽇期
相关表结构分析
⼤盘指数包含国内和国外的⼤盘数据,⽬前我们先完成国内⼤盘信数据的展示功能;
国内股票⼤盘数据详情表设计如下: 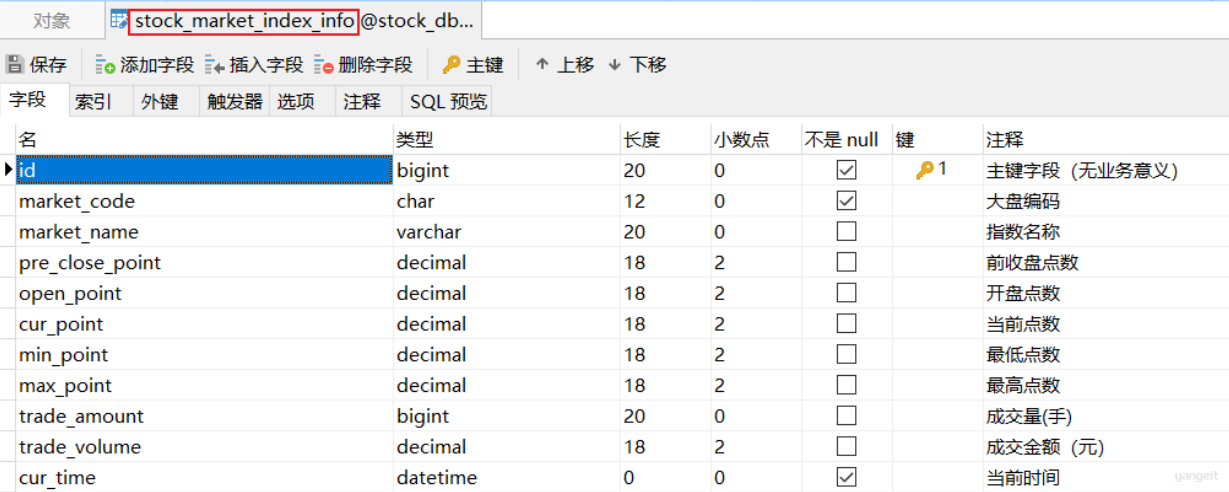
注意事项: 👇
数据库字段类型decimal—>java中的BigDecimal
数据库字段类型bigint—> java中的Long类型
A股⼤盘指数接⼝说明
- 功能说明:
- 获取最新国内A股⼤盘信息(仅包含上证和深证⼤盘数据);查询时间点不在正常股票交易时间内,则显示最近时间点的交易信息;
- ⽐如:当前查询时间点是周⼀上午8点整,因为当天尚未开盘,则显示上周五最新的数据,也就是收盘时数据;
- 请求路径:
/api/quot/index/all - 请求⽅式:
GET - 参数:
⽆ - 响应数据格式:
{
"code": 1,
"data": [
{
"code": "sh000001",//⼤盘编码
"name": "上证指数",//指数名称
"openPoint": 3267.81,//开盘点
"curPoint": 3236.70,//当前点
"preClosePoint": 3283.43,//前收盘点
"tradeAmt": 160591,//交易量
"tradeVol": 1741099,//交易⾦额
"upDown": -46.73,//涨跌值
"rose": -0.01.42,//涨幅
"amplitude": 0.0164,//振幅
"curTime": "2022-01-02 01:32"//当前时间
},
{......}
]
}
A股⼤盘开盘周期:周⼀⾄周五,每天上午9:30到11:30和下午13:00到15:00;
domain、pojo、entity、vo类等实体类作为公共资源都维护在stock_common⼯程下 注意:在stock_common⼯程下直接导⼊day02\资料\domain\InnerMarketDomain.java 即可
image

代码操作
步骤
- 准备工作
- 股票交易时间⼯具类封装
- 常量数据封装
- 国内⼤盘指数SQL分析
- 业务功能:获取最新的国内⼤盘的数据信息
- 国内⼤盘指数功能实现
- 定义获取A股⼤盘数据接⼝
- 定义服务⽅法和实现
- 定义mapper⽅法与xml
- web接⼝测试
1️⃣ 股票交易时间⼯具类封装
- 在stock_common下直接导⼊⽇期⼯具类:今⽇指数
\day02\资料\date⼯具类\DateTimeUtil.java - ⼯具类借助jode-time⽇期插件实现,jode-date核⼼⽅式参考:
day02\资料\date⼯具类\TestJodeDate.java
- 在stock_common下直接导⼊⽇期⼯具类:今⽇指数
2️⃣ 常量数据封装
股票常⽤的公共参数⾮常多,我们可以在
stock_common下把他们封装到⼀个Value Object(vo)对象下,并通过Spring为调⽤⽅动态赋值
本⼩节我们把股票⼤盘编码信息配置到StockInfoConfig实体类下:
@ConfigurationProperties(prefix = "stock") @Data public class StockInfoConfig { //A股⼤盘ID集合 private List<String> inner; //外盘ID集合 private List<String> outer; }在调⽤⽅
stock_backend⼯程下定义application-stock.yml⽂件,并配置A股⼤盘和外盘的编码数据:# 配置股票相关的参数 stock: inner: # A股 - sh000001 # 上证ID - sz399001 # 深证ID outer: # 外盘 - int_dji # 道琼斯 - int_nasdaq # 纳斯达克 - int_hangseng # 恒⽣ - int_nikkei # ⽇经指数 - b_FSSTI # 新加坡同时在主配置⽂件application.yml中激活该配置:
spring: profiles: active: stock说明:将股票相关的配置⽂件独⽴出来,⽅便后期维护,且避免产⽣臃肿的主配置⽂件;
在公共配置类中加载实体VO对象:
@EnableConfigurationProperties(StockInfoConfig.class) @Configuration public class CommonConfig { //省略N⾏ }测试类测试能读取配置文件
@SpringBootTest
public class TestStock {
@Autowired
private StockInfoConfig stockInfoConfig;
@Test
public void test01(){
System.out.println(stockInfoConfig);
}
}

国内⼤盘指数SQL分析:
业务功能::获取最新的国内⼤盘的数据信息
- ⽅案1:
-- 功能说明:获取最新国内A股⼤盘信息(上证和深证)
-- 如果不在股票交易时间,则显示最近时间点的交易信息
-- 分析:就是根据⼤盘的编码查询⼤盘的最新交易数据
-- ⼤盘编码:sh000001 sz399001
SELECT
smi.market_code AS code,
smi.market_name AS name,
smi.open_point AS openPoint,
smi.cur_point AS curPoint,
smi.pre_close_point AS preClosePoint,
smi.trade_amount AS tradeAmt,
smi.trade_volume AS tradeVol,
smi.cur_point-smi.pre_close_point AS upDown,
(smi.cur_point-smi.pre_close_point)/smi.pre_close_point
AS rose,
(smi.max_point-smi.min_point)/smi.pre_close_point AS
amplitude,
smi.cur_time AS curTime
FROM stock_market_index_info AS smi
WHERE smi.market_code IN ('sh000001','sz399001')
ORDER BY smi.cur_time DESC LIMIT 2;
存在的问题: :1.全表查询,效率较低
如何优化?
一⽅⾯为了为了避免重复数据,将时间和⼤盘编码作为联合唯⼀索引,起到唯⼀约束的作⽤
另外,借助这个索引,也避免全表查询查询最新的数据,可转化成查询最新的股票交易时间点下的数据
- 🎯⽅案2
自己参考下面的要求,想一下sql应该怎样优化比较好!
在sql查询时,尽量避免全表查询,否则随着数据量的增加,全表查询导致的查询时间成本会不断上升。
构建联合唯一索引,点击查看图解
国内⼤盘指数功能实现
- 定义获取A股⼤盘数据接⼝
@RestController
@RequestMapping("/api/quot")
public class StockController {
@Autowired
private StockService stockService;
//其它省略.....
/**
* 查询最新的国内大盘信息
*
* @return
*/
@ApiOperation("查询最新的国内大盘信息")
@GetMapping("/index/all")
public R<List<InnerMarketDomain>> getInnerIndexAll() {
return stockService.getInnerIndexAll();
}
}
定义国内⼤盘数据服务
- 服务接⼝:
public interface StockService { //其它省略...... /** * 查询最新的国内大盘信息 * @return */ R<List<InnerMarketDomain>> getInnerIndexAll(); }🎯服务接⼝实现:
自行实现哦!!!!! 输入密码查看
定义mapper⽅法与xml
- mapper下定义接⼝⽅法和xml
/** * 根据⼤盘的id和时间查询⼤盘信息 * @param marketIds ⼤盘id集合 * @param dateTime 当前时间点(默认精确到分钟) * @return */ List<InnerMarketDomain> getInnerIndexByTimeAndCodes(@Param("dateTime") Date dateTime, @Param("innerCodes") List<String> marketIds);- 定义mapper接⼝绑定SQL
<select id="getMarketInfo" resultType="com.itheima.stock.pojo.domain.InnerMarketDomain"> ...自己敲.... </select>web接⼝测试

- 点击apifox自动同步接口文档
3.2 板块指数功能实现 🎯
前言
stock_block_rt_info板块表分析:
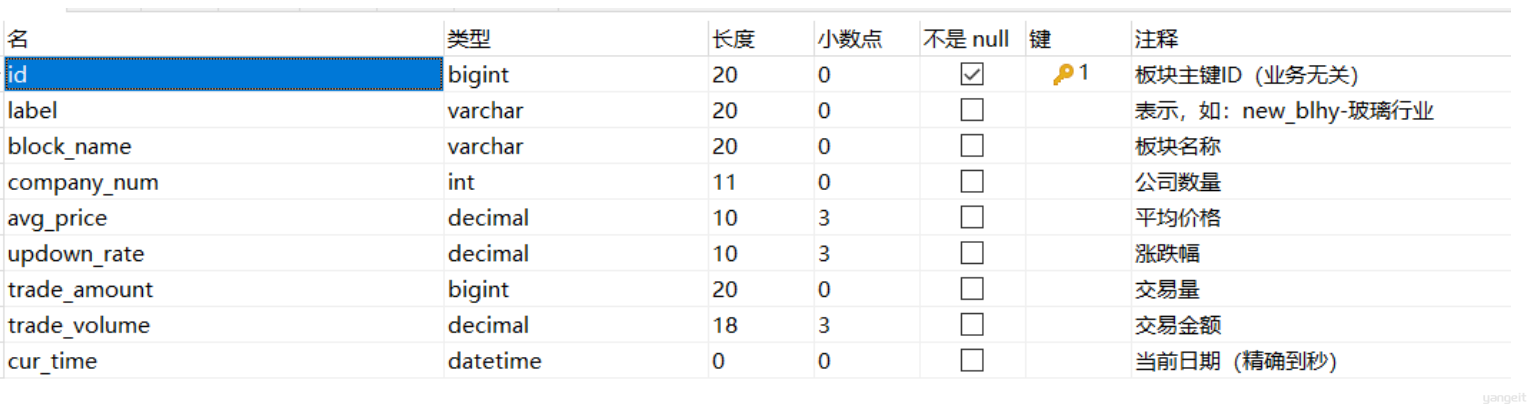
说明:板块表涵盖了业务所需的所有字段数据;
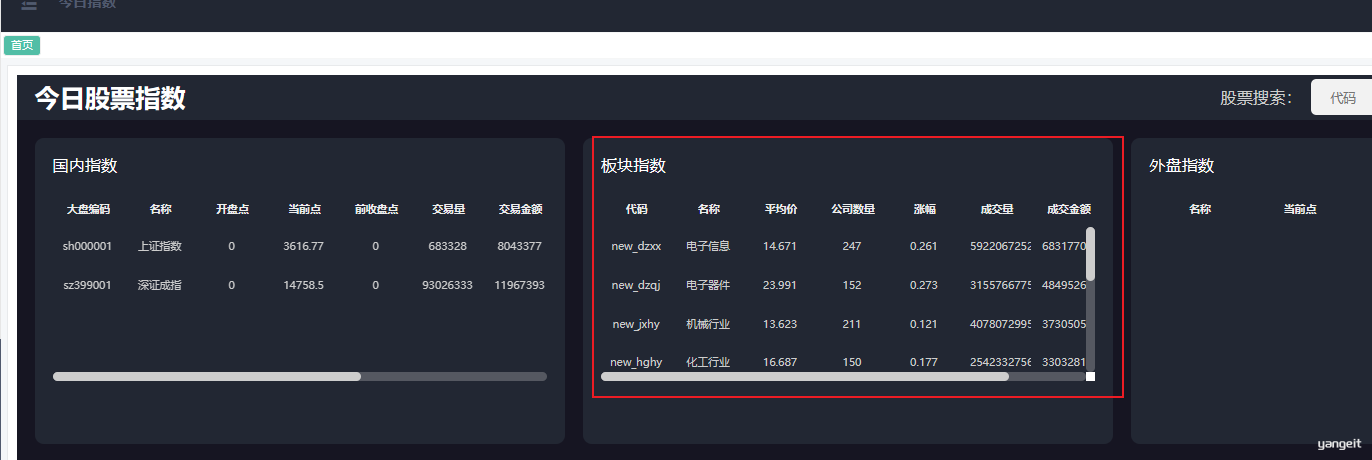
- 需求说明: 查询沪深两市最新的板块⾏情数据,并按照交易⾦额降序排序展示前10条记录
- 请求URL:
/api/quot/sector/all - 请求⽅式:
GET - 请求参数:
⽆ - 接⼝响应数据格式:
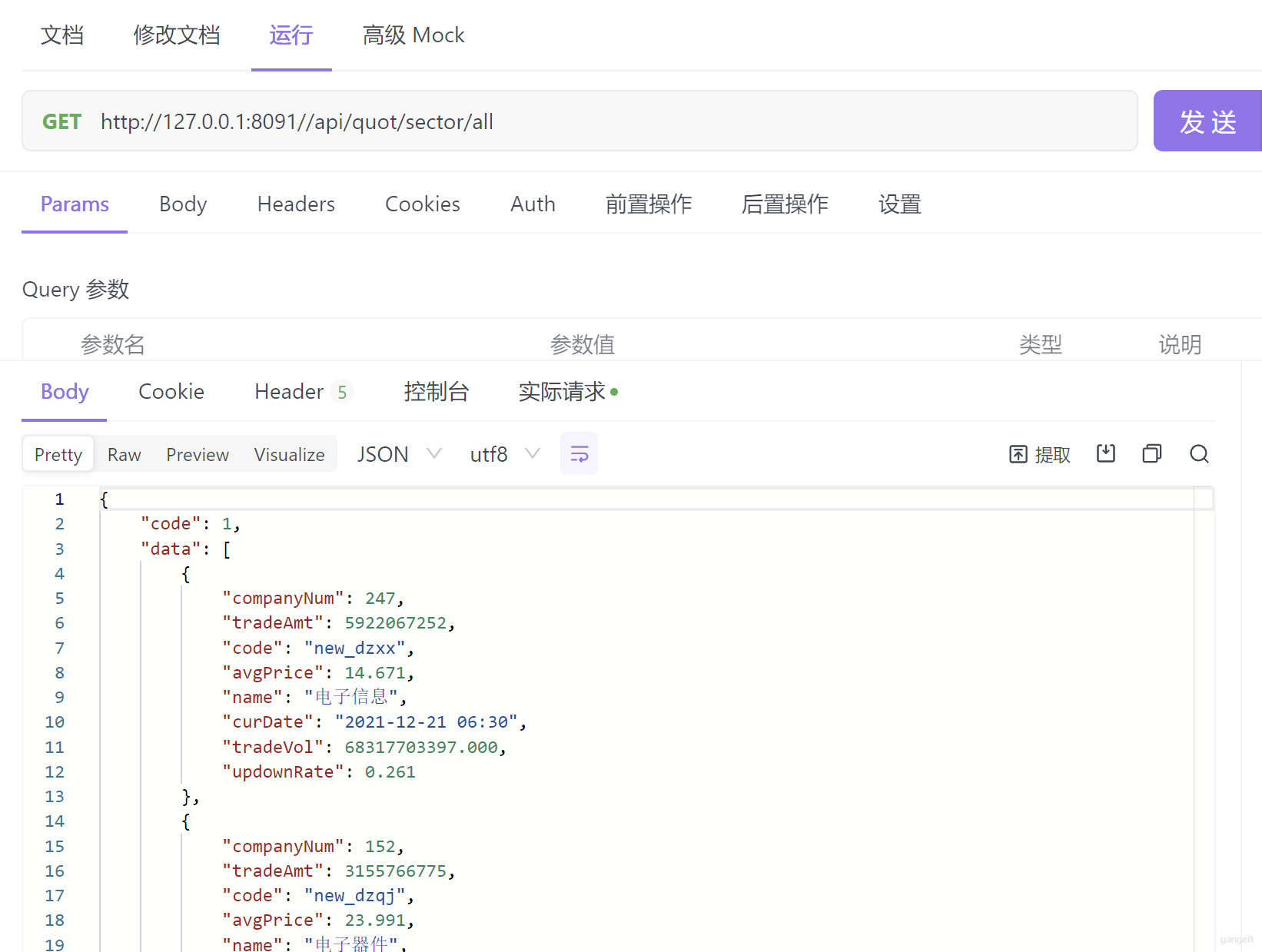
{ "code": 1, "data": [ { "companyNum": 247,//公司数量 "tradeAmt": 5065110316,//交易量 "code": "new_dzxx",//板块编码 "avgPrice": 14.571,//平均价格 "name": "电⼦信息",//板块名称 "curDate": "2021-12-30 09:50:10",//当前⽇期 "tradeVol": 60511659145,//交易总⾦额 "updownRate": 0.196//涨幅 }, //省略....... ] }
代码操作
实体类维护到stock_common⼯程下:
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class StockBlockDomain {
/**
* 公司数量
*/
private Integer companyNum;
/**
* 交易量
*/
private Long tradeAmt;
/**
* 板块编码
*/
private String code;
/**
* 平均价
*/
private BigDecimal avgPrice;
/**
* 板块名称
*/
private String name;
/**
* 当前⽇期
*/
@JsonFormat(pattern = "yyyy-MM-dd HH:mm")
private Date curDate;
/**
*交易⾦额
*/
private BigDecimal tradeVol;
/**
* 涨跌率
*/
private BigDecimal updownRate;
}
国内板块指数SQL分析:
核⼼功能要求: 查询最新板块数据信息,按交易⾦额降序排序取前10;
- ⽅案1:
-- 思考:将板块表根据⽇期和交易⾦额降序排序,取前10
select
sbr.company_num as companyNum,
sbr.trade_amount as tradeAmt,
sbr.label as code,
sbr.avg_price as avgPrice,
sbr.block_name as name,
sbr.cur_time as curDate,
sbr.trade_volume as tradeVol,
sbr.updown_rate as updownRate
from stock_block_rt_info as sbr
order by sbr.cur_time desc,sbr.trade_volume desc
limit 10
弊端: 每次查询都会全表排序,然后再limit返回指定数据,开销⾮常⼤
- ⽅案2
-- 思路:业务要求是查询最新的数据,也就以为这只需查询最新交易时间点对应的数据,然后根据交易⾦额降序排序取前10即可【⽇期字段构建索引,提⾼查询效率,通过索引获取少量数据,然后再排序,这样cpu和磁盘io的开销得以降低】
自己写....
构建联合唯一索引,
参考答案点击这里查看(需要密码)👈part2_板块指数功能实现sql分析.txt
国内板块指数功能实现
- 定义板块web访问接⼝⽅法
/**
*需求说明: 获取沪深两市板块最新数据,以交易总⾦额降序查询,
取前10条数据
* @return
*/
@GetMapping("/sector/all")
public R<List<StockBlockDomain>> sectorAll(){
return stockService.sectorAllLimit();
}
定义服务⽅法和实现
- 服务接⼝⽅法:
/** * 需求说明: 获取沪深两市板块最新数据,以交易总⾦额降序查询, 取前10条数据 * @return */ R<List<StockBlockDomain>> sectorAllLimit();🎯服务接⼝实现:
自行实现哦!!!!!
参考答案点击这里查看(需要密码)👈板块指数查询功能_业务层代码.jpg
定义mapper⽅法与xml
- mapper接⼝⽅法:
/** * 沪深两市板块分时⾏情数据查询,以交易时间和交易总⾦额降序查 询,取前10条数据 * @param timePoint 指定时间点 * @return */ List<StockBlockDomain> sectorAllLimit(@Param("timePoint") Date timePoint);- 定义mapper接⼝xml:
<select id="sectorAllLimit" resultType="com.itheima.stock.pojo.domain.StockBlockDomain" > select sbr.company_num as companyNum, sbr.trade_amount as tradeAmt, sbr.label as code, sbr.avg_price as avgPrice, sbr.block_name as name, sbr.cur_time as curDate, sbr.trade_volume as tradeVol, sbr.updown_rate as updownRate from stock_block_rt_info as sbr where sbr.cur_time=#{timePoint} order by sbr.trade_volume desc limit 10 </select>web接⼝测试 接口测试:http://127.0.0.1:8091/api/quot/sector/all
面试点:
项目中前后端分离存在哪些问题?是如何解决的?
- 跨域、状态识别问题、接口格式统一问题、接口文档维护相关
你们团队开发时接口文档如何维护?
- swagger+apifox
说一下你开发某个业务接口时的流程?
- 需求分析,确定边界-》作用于哪些表表结构
- 分析业务,进行SQL落地;
- 分析:实现业务功能的sql方式很多,尽量选择最优解;
雪花算法如何保证分布式环境下ID的唯一性的?
- 4个因子;
- 存在时间回拨的问题;
- TODO:
- 后台响应图片流+动态
- 验证码接口安全防护:单台机器一分钟内最多访问一次